AWS Big Data Blog
Compose your ETL jobs for MongoDB Atlas with AWS Glue
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and data lakes based on operational data. This is driven by the need to centralize and integrate data coming from disparate sources.
At the same time, operational data often originates from applications backed by legacy data stores. Modernizing applications requires a microservice architecture, which in turn necessitates the consolidation of data from multiple sources to construct an operational data store. Without modernization, legacy applications may incur increasing maintenance costs. Modernizing applications involves changing the underlying database engine to a modern document-based database like MongoDB.
These two tasks (building data lakes or data warehouses and application modernization) involve data movement, which uses an extract, transform, and load (ETL) process. The ETL job is a key functionality to having a well-structured process in order to succeed.
AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. MongoDB Atlas is an integrated suite of cloud database and data services that combines transactional processing, relevance-based search, real-time analytics, and mobile-to-cloud data synchronization in an elegant and integrated architecture.
By using AWS Glue with MongoDB Atlas, organizations can streamline their ETL processes. With its fully managed, scalable, and secure database solution, MongoDB Atlas provides a flexible and reliable environment for storing and managing operational data. Together, AWS Glue ETL and MongoDB Atlas are a powerful solution for organizations looking to optimize how they build data lakes and data warehouses, and to modernize their applications, in order to improve business performance, reduce costs, and drive growth and success.
In this post, we demonstrate how to migrate data from Amazon Simple Storage Service (Amazon S3) buckets to MongoDB Atlas using AWS Glue ETL, and how to extract data from MongoDB Atlas into an Amazon S3-based data lake.
Solution overview
In this post, we explore the following use cases:
- Extracting data from MongoDB – MongoDB is a popular database used by thousands of customers to store application data at scale. Enterprise customers can centralize and integrate data coming from multiple data stores by building data lakes and data warehouses. This process involves extracting data from the operational data stores. When the data is in one place, customers can quickly use it for business intelligence needs or for ML.
- Ingesting data into MongoDB – MongoDB also serves as a no-SQL database to store application data and build operational data stores. Modernizing applications often involves migration of the operational store to MongoDB. Customers would need to extract existing data from relational databases or from flat files. Mobile and web apps often require data engineers to build data pipelines to create a single view of data in Atlas while ingesting data from multiple siloed sources. During this migration, they would need to join different databases to create documents. This complex join operation would need significant, one-time compute power. Developers would also need to build this quickly to migrate the data.
AWS Glue comes handy in these cases with the pay-as-you-go model and its ability to run complex transformations across huge datasets. Developers can use AWS Glue Studio to efficiently create such data pipelines.
The following diagram shows the data extraction workflow from MongoDB Atlas into an S3 bucket using the AWS Glue Studio.
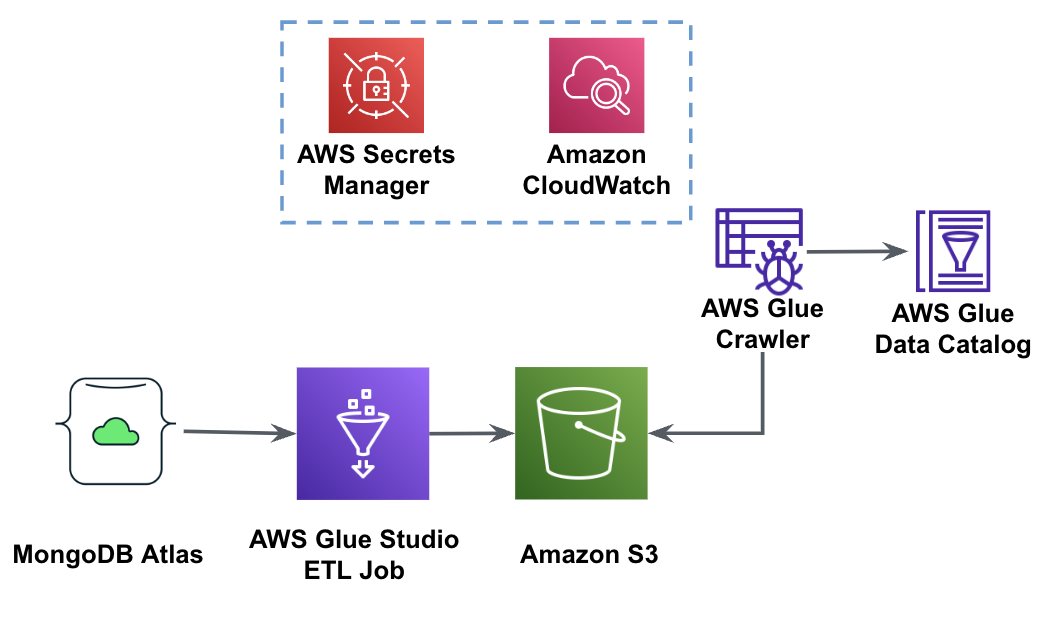
In order to implement this architecture, you will need a MongoDB Atlas cluster, an S3 bucket, and an AWS Identity and Access Management (IAM) role for AWS Glue. To configure these resources, refer to the prerequisite steps in the following GitHub repo.
The following figure shows the data load workflow from an S3 bucket into MongoDB Atlas using AWS Glue.

The same prerequisites are needed here: an S3 bucket, IAM role, and a MongoDB Atlas cluster.
Load data from Amazon S3 to MongoDB Atlas using AWS Glue
The following steps describe how to load data from the S3 bucket into MongoDB Atlas using an AWS Glue job. The extraction process from MongoDB Atlas to Amazon S3 is very similar, with the exception of the script being used. We call out the differences between the two processes.
- Create a free cluster in MongoDB Atlas.
- Upload the sample JSON file to your S3 bucket.
- Create a new AWS Glue Studio job with the Spark script editor option.

- Depending on whether you want to load or extract data from the MongoDB Atlas cluster, enter the load script or extract script in the AWS Glue Studio script editor.
The following screenshot shows a code snippet for loading data into the MongoDB Atlas cluster.

The code uses AWS Secrets Manager to retrieve the MongoDB Atlas cluster name, user name, and password. Then, it creates a DynamicFrame for the S3 bucket and file name passed to the script as parameters. The code retrieves the database and collection names from the job parameters configuration. Finally, the code writes the DynamicFrame to the MongoDB Atlas cluster using the retrieved parameters.
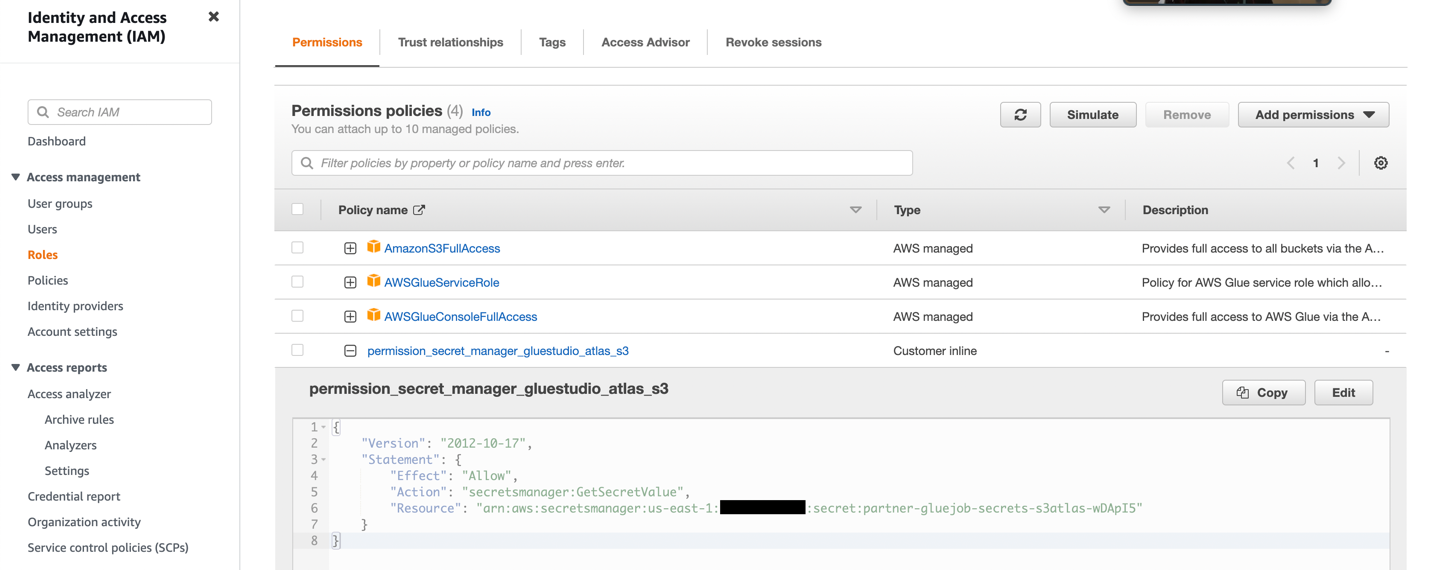
- Create an IAM role with the permissions as shown in the following screenshot.
For more details, refer to Configure an IAM role for your ETL job.
- Give the job a name and supply the IAM role created in the previous step on the Job details tab.
- You can leave the rest of the parameters as default, as shown in the following screenshots.


- Next, define the job parameters that the script uses and supply the default values.

- Save the job and run it.
- To confirm a successful run, observe the contents of the MongoDB Atlas database collection if loading the data, or the S3 bucket if you were performing an extract.



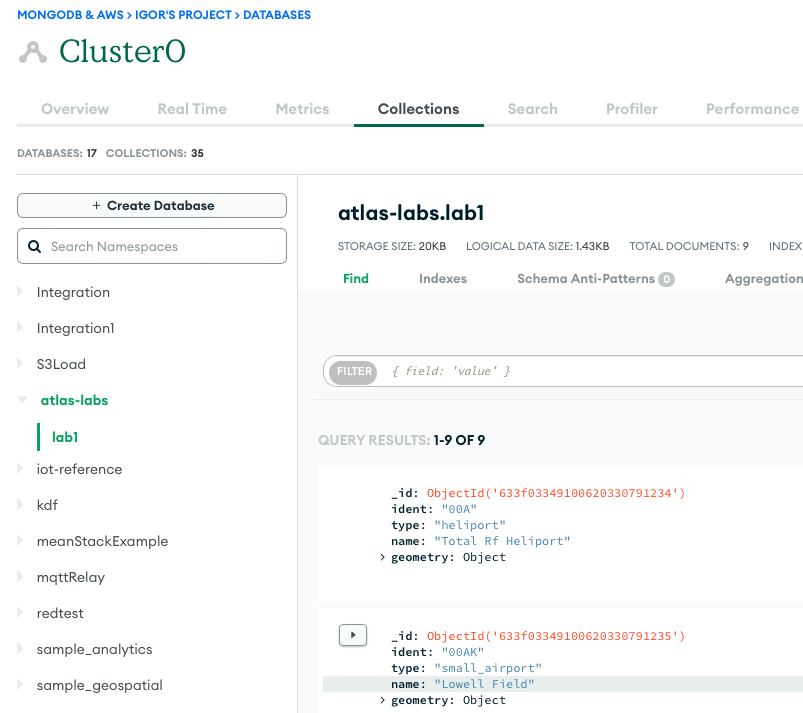
The following screenshot shows the results of a successful data load from an Amazon S3 bucket into the MongoDB Atlas cluster. The data is now available for queries in the MongoDB Atlas UI.
- To troubleshoot your runs, review the Amazon CloudWatch logs using the link on the job’s Run tab.
The following screenshot shows that the job ran successfully, with additional details such as links to the CloudWatch logs.

Conclusion
In this post, we described how to extract and ingest data to MongoDB Atlas using AWS Glue.
With AWS Glue ETL jobs, we can now transfer the data from MongoDB Atlas to AWS Glue-compatible sources, and vice versa. You can also extend the solution to build analytics using AWS AI and ML services.
To learn more, refer to the GitHub repository for step-by-step instructions and sample code. You can procure MongoDB Atlas on AWS Marketplace.
About the Authors

Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
 Babu Srinivasan
is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.
Babu Srinivasan
is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.