AWS Big Data Blog
Explore your data lake using Amazon Athena for Apache Spark
Amazon Athena now enables data analysts and data engineers to enjoy the easy-to-use, interactive, serverless experience of Athena with Apache Spark in addition to SQL. You can now use the expressive power of Python and build interactive Apache Spark applications using a simplified notebook experience on the Athena console or through Athena APIs. For interactive Spark applications, you can spend less time waiting and be more productive because Athena instantly starts running applications in less than a second. And because Athena is serverless and fully managed, analysts can run their workloads without worrying about the underlying infrastructure.
Data lakes are a common mechanism to store and analyze data because they allow companies to manage multiple data types from a wide variety of sources, and store this data, structured and unstructured, in a centralized repository. Apache Spark is a popular open-source, distributed processing system optimized for fast analytics workloads against data of any size. It’s often used to explore data lakes to derive insights. For performing interactive data explorations on the data lake, you can now use the instant-on, interactive, and fully managed Apache Spark engine in Athena. It enables you to be more productive and get started quickly, spending almost no time setting up infrastructure and Spark configurations.
In this post, we show how you can use Athena for Apache Spark to explore and derive insights from your data lake hosted on Amazon Simple Storage Service (Amazon S3).
Solution overview
We showcase reading and exploring CSV and Parquet datasets to perform interactive analysis using Athena for Apache Spark and the expressive power of Python. We also perform visual analysis using the pre-installed Python libraries. For running this analysis, we use the built-in notebook editor in Athena.
For the purpose of this post, we use the NOAA Global Surface Summary of Day public dataset from the Registry of Open Data on AWS, which consists of daily weather summaries from various NOAA weather stations. The dataset is primarily in plain text CSV format. We have transformed the entire and subsets of the CSV dataset into Parquet format for our demo.
Before running the demo, we want to introduce the following concepts related to Athena for Spark:
- Sessions – When you open a notebook in Athena, a new session is started for it automatically. Sessions keep track of the variables and state of notebooks.
- Calculations – Running a cell in a notebook means running a calculation in the current session. As long as a session is running, calculations use and modify the state that is maintained for the notebook.
For more details, refer to Session and Calculations.
Prerequisites
For this demo, you need the following prerequisites:
- An AWS account with access to the AWS Management Console
- Athena permissions on the workgroup
DemoAthenaSparkWorkgroup, which you create as part of this demo - AWS Identity and Access Management (IAM) permissions to create, read, and update the IAM role and policies created as part of the demo
- Amazon S3 permissions to create an S3 bucket and read the bucket location
The following policy grants these permissions. Attach it to the IAM role or user you use to sign in to the console. Make sure to provide your AWS account ID and the Region in which you’re running the demo.
Create your Athena workgroup
We create a new Athena workgroup with Spark as the engine. Complete the following steps:
- On the Athena console, choose Workgroups in the navigation pane.
- Choose Create workgroup.
- For Workgroup name, enter
DemoAthenaSparkWorkgroup.
Make sure to enter the exact name because the preceding IAM permissions are scoped down for the workgroup with this name. - For Analytics engine, choose Apache Spark.
- For Additional configurations, select Use defaults.
The defaults include the creation of an IAM role with the required permissions to run Spark calculations on Athena and an S3 bucket to store calculation results. It also sets the notebook (which we create later) encryption key management to an AWS Key Management Service (AWS KMS) key owned by Athena. - Optionally, add tags to your workgroup.
- Choose Create workgroup.
Modify the IAM role
Creating the workgroup creates a new IAM role. Choose the newly created workgroup, then the value under Role ARN to be redirected to the IAM console.
Add the following permission as an inline policy to the IAM role created earlier. This allows the role to read the S3 datasets. For instructions, refer to the section To embed an inline policy for a user or role (console) in Adding IAM identity permissions (console).
Set up your notebook
To run the analysis on Spark on Athena, we need a notebook. Complete the following steps to create one:
- On the Athena console, choose Notebook Editor.
- Choose the newly created workgroup
DemoAthenaSparkWorkgroupon the drop-down menu. - Choose Create Notebook.
- Provide a notebook name, for example
AthenaSparkBlog. - Keep the default session parameters.
- Choose Create.
Your notebook should now be loaded, which means you can start running Spark code. You should see the following screenshot.

Explore the dataset
Now that we have workgroup and notebook created, let’s start exploring the NOAA Global Surface Summary of Day dataset. The datasets used in this post are stored in the following locations:
- CSV data for year 2022 –
s3://noaa-gsod-pds/2022/ - Parquet data for year 2021 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2021/ - Parquet data for year 2020 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/ - Entire dataset in Parquet format (until October 2022) –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/historical/
In the rest of this post, we show PySpark code snippets. Copy the code and enter it in the notebook’s cell. Press Shift+Enter to run the code as a calculation. Alternatively, you can choose Run. Add more cells to run subsequent code snippets.
We start by reading the CSV dataset for the year 2022 and print its schema to understand the columns contained in the dataset. Run the following code in the notebook cell:

We get the following output.

We were able to submit the preceding code as a calculation instantly using the notebook.
Let’s continue exploring the dataset. Looking at the columns in the schema, we’re interested in previewing the data for the following attributes in 2022:
- TEMP – Mean temperature
- WDSP – Mean wind speed
- GUST – Maximum wind gust
- MAX – Maximum temperature
- MIN – Minimum temperature
- Name – Station name
Run the following code:
We get the following output.

Now we have an idea of what the dataset looks like. Next, let’s perform some analysis to find the maximum recorded temperature for the Seattle-Tacoma Airport in 2022. Run the following code:
We get the following output.

Next, we want to find the maximum recorded temperature for each month of 2022. For this, we use the Spark SQL feature of Athena. First, we need to create a temporary view on the year_22_csv data frame. Run the following code:
To run our Spark SQL query, we use %%sql magic:
We get the following output.

The output of the preceding query produces the month in numeric form. To make it more readable, let’s convert the month numbers into month names. For this, we use a user-defined function (UDF) and register it to use in the Spark SQL queries for the rest of the notebook session. Run the following code to create and register the UDF:
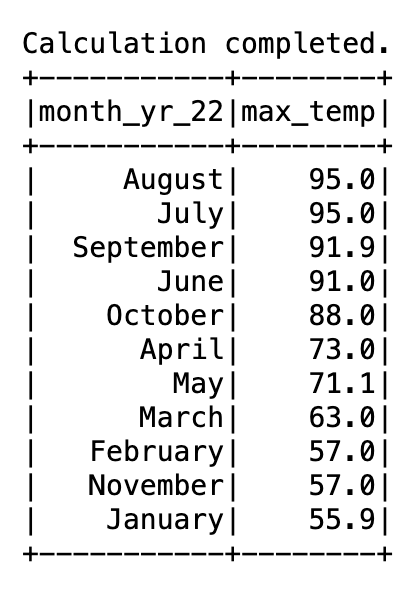
We rerun the query to find the maximum recorded temperature for each month of 2022 but with the month_name_udf UDF we just created. Also, this time we sort the results based on the maximum temperature value. See the following code:
The following output shows the month names.
Until now, we have run interactive explorations for the year 2022 of the NOAA Global Surface Summary of Day dataset. Let’s say we want to compare the temperature values with the previous 2 years. We compare the maximum temperature across 2020, 2021, and 2022. As a reminder, the dataset for 2022 is in CSV format and for 2020 and 2021, the datasets are in Parquet format.
To continue with the analysis, we read the 2020 and 2021 Parquet datasets into the data frame and create temporary views on the respective data frames. Run the following code:
We get the following output.

To compare the recorded maximum temperature for each month in 2020, 2021, and 2022, we perform a join operation on the three views created so far from their respective data frames. Also, we reuse the month_name_udf UDF to convert month number to month name. Run the following code:
We get the following output.

So far, we’ve read CSV and Parquet datasets, run analysis on the individual datasets, and performed join and aggregation operations on them to derive insights instantly in an interactive mode. Next, we show how you can use the pre-installed libraries like Seaborn, Matplotlib, and Pandas for Spark on Athena to generate a visual analysis. For the full list of preinstalled Python libraries, refer to List of preinstalled Python libraries.
We plot a visual analysis to compare the recorded maximum temperature values for each month in 2020, 2021, and 2022. Run the following code, which creates a Spark data frame from the SQL query, converts it into a Pandas data frame, and uses Seaborn and Matplotlib for plotting:
The following graph shows our output.

Next, we plot a heatmap showing the maximum temperature trend for each month across all the years in the dataset. For this, we have converted the entire CSV dataset (until October 2022) into Parquet format and stored it in s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/historical/.
Run the following code to plot the heatmap:
We get the following output.

From the potting, we can see the trend has been almost similar across the years, where the temperature rises during summer months and lowers as winter approaches in the Seattle-Tacoma Airport area. You can continue exploring the datasets further, running more analyses and plotting more visuals to get the feel of the interactive and instant-on experience Athena for Apache Spark offers.
Clean up resources
When you’re done with the demo, make sure to delete the S3 bucket you created to store the workgroup calculations to avoid storage costs. Also, you can delete the workgroup, which deletes the notebook as well.
Conclusion
In this post, we saw how you can use the interactive and serverless experience of Athena for Spark as the engine to run calculations instantly. You just need to create a workgroup and notebook to start running the Spark code. We explored datasets stored in different formats in an S3 data lake and ran interactive analyses to derive various insights. Also, we ran visual analyses by plotting charts using the preinstalled libraries. To learn more about Spark on Athena, refer to Using Apache Spark in Amazon Athena.
About the Authors
 Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
 Raj Devnath is a Sr. Product Manager at AWS working on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.
Raj Devnath is a Sr. Product Manager at AWS working on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.