AWS Big Data Blog
Hosting Amazon Kinesis Applications on AWS Elastic Beanstalk
Ian Meyers is a Solutions Architecture Senior Manager with AWS
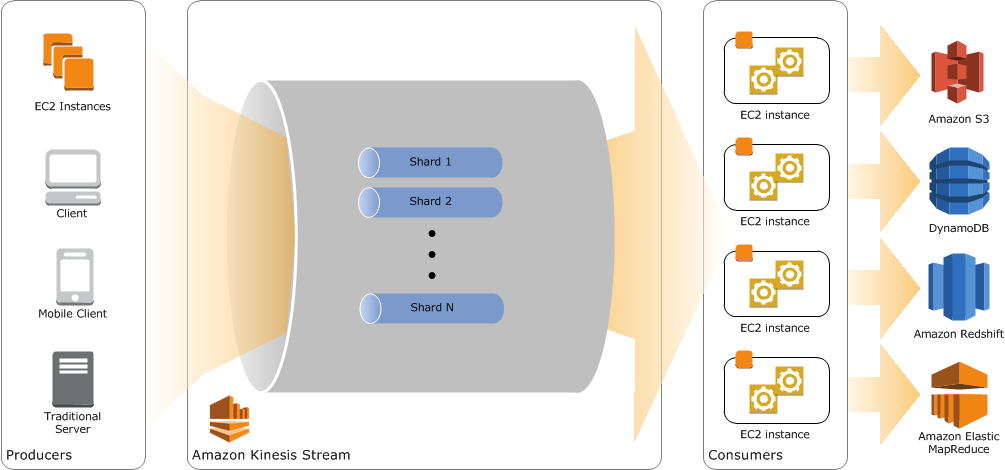
Amazon Kinesis provides a scalable and highly available platform for ingesting data from thousands of clients. Once data is available on a Kinesis stream, you can build applications to process the data using the Kinesis Client Library (KCL). KCL provides a framework for managing many of the complexities that accompany designing stream-processing applications. For example, the KCL will automatically distribute workers to process each shard in a Kinesis stream. It will manage this in a single JVM or across a fleet of instances. Using the KCL, you can build elastic, fault-tolerant, scalable stream-processing applications. Once you’ve built such an application, you’ll want a simple way to deploy it.
AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and services. Simply upload your application archive, and AWS Elastic Beanstalk automatically deploys it across multiple Availability Zones with configuration of AutoScaling. It also provides load balancing and monitors application health. These features make AWS Elastic Beanstalk a great platform for running Amazon Kinesis Applications. This article shows you how to host Kinesis applications in AWS Elastic Beanstalk.
You can now download an Amazon Elastic Beanstalk Application for Java/Tomcat, which lets you deploy your processing logic as an AWS Elastic Beanstalk-managed application. Simply build your Amazon Kinesis application as you normally would and expose the ability to start the Worker implementation using a publicly accessible run() method. Elastic Beanstalk handles the rest, including building the AutoScaling configuration and distributing your application across multiple Availability Zones. If an instance crashes, AWS Beanstalk replaces it. As you add shards to your stream, AWS Elastic Beanstalk scales your Kinesis Application based on CPU usage. As with all AWS Elastic Beanstalk applications, you can configure and customize the application and the underlying resources as required.
Creating a New Application
To get started, you’ll create a new application using the following steps.
- Clone the Kinesis Elastic Beanstalk Workers into a new directory:
git clone https://github.com/awslabs/aws-big-data-blog.git aws-big-data-blog
- Build and package your Amazon Kinesis application. This requires launching a worker with a Kinesis Configuration and an IRecordProcessorFactory that contains your application logic. Below is an example of how to create and start a Worker:
AWSCredentialsProvider credentialsProvider = new
DefaultAWSCredentialsProviderChain();
kinesisClientLibConfiguration = new KinesisClientLibConfiguration(
appName, streamName, credentialsProvider, workerId)
.withInitialPositionInStream(InitialPositionInStream.LATEST);
IRecordProcessorFactory recordProcessorFactory = new
CDRProcessorFactory(kinesisClientLibConfiguration);
Worker worker = new Worker(recordProcessorFactory,
kinesisClientLibConfiguration);
int failures = 0;
// run the worker, tolerating as many failures as is configured
while (failures < failuresToTolerate) {
try {
worker.run();
} catch (Throwable t) {
LOG.error("Caught throwable while processing data.", t);
failures++;
if (failures < failuresToTolerate) {
LOG.error("Restarting...");
}
}
}
- To use Kinesis Applications hosted in Elastic Beanstalk, ensure that the above example code can be invoked using a method called run in your application.
- Build as you normally would using your preferred build tool.
- When you’re done, drop the assembled jar file into the aws-big-data-blog/aws-blog-kinesis-beanstalk-workers/src/main/WebContent/WEB-INF/lib directory.
- Build your Beanstalk Application Web Archive using Maven. To build your application, open a terminal window in the aws-big-data-blog/aws-blog-kinesis-beanstalk-workers directory and issue the following command: mvn clean compile war:war
When completed, the WAR file is generated to directory aws-big-data-blog/aws-blog-kinesis-beanstalk-workers/target/MyKinesisBeanstalkApplication.war.
Creating an Application Version
Now that you’ve created an application, you’ll use the Elastic Beanstalk Console to create an Application version.
- Go to the Elastic Beanstalk Console.
- Configure IAM permissions so your Kinesis Workers in Elastic Beanstalk have rights to your KCL application. This requires access to Kinesis, the ability to write Amazon CloudWatch metrics, and the ability to checkpoint the worker state into Amazon DynamoDB. Create an IAM Role that allows the Amazon Elastic Compute Cloud (Amazon EC2) instances in the Elastic Beanstalk Stack to assume an identity that gives them these privileges. In the IAM console, create a new role and provide the following policy:
{
"Version": "2014-03-25",
"Statement" [
{
"Sid": "Stmt1392290776000",
"Effect": "Allow",
"Action" [
"kinesis:*", "cloudwatch:*", "dynamodb:*"
],
"Resource": [
"*"
]
}
]
}
You can also use the Policy Generator to ensure your application has access to Kinesis, DynamoDB, and CloudWatch.
- Perform a Basic Beanstalk Configuration. The Elastic Beanstalk deployment wizard asks you questions to determine how your application should be run. The Kinesis Beanstalk Worker application is designed to run as a web server environment, so select this on the Environment Type page, along with the Tomcat predefined configuration. For Kinesis-enabled applications, we recommend running on multiple instances in a load-balanced configuration.
- On the next page, upload the WAR file generated by Maven.
- Create an environment name that is meaningful to you, such as “Development” or “Testing,” and select a URL for your application healthcheck page. You will not require an RDS environment, but of course can run this application within VPC as outlined on the Additional Resources panel of the wizard.
- Select an instance type to run on and a public/private key pair for authentication if you want to SSH to the instances.
- Configure the EC2 Instance Profile with the IAM Role configured earlier (Figure 1).

Figure 1 – Configuration Details screen
- Select Tags for your environment.
- Review the configuration and launch the environment. Once deployed, your Beanstalk application displays a splash page reading “OK – Kinesis Client Library Application hosted in Elastic Beanstalk Online.” For fault tolerance, this application is deployed across all Availability Zones in the Region in which you’ve deployed and scales as your Kinesis Client Application gets busy.
- Select the Configuration left-hand navigation on the environment, and then select the Software Configuration panel.
- Scroll down. Under Environment Properties, enter the full class name including the package for the location of your worker in parameter PARAM1 (Figure 2).

Figure 2 – Environment Properties screen
Once you’re done, you can update your environment, which causes the Kinesis Application start.
Publishing Test Data
To publish test data, download the Kinesis Log4J Appender and follow the instructions. This publishes the contents of a file that you provide to the configured Kinesis Stream, which should match the format of data supported by your consumer application.
Monitoring and Operating the Application
You can review the logs for the Kinesis Client Worker from the Web Console by selecting Logs in the left-hand navigation of the Elastic Beanstalk Console and then selecting Snapshot Logs. All of the available logs for the application are retrieved from the EC2 instances supporting the Beanstalk application and stored in Amazon Simple Storage Service (Amazon S3). You can browse these files to confirm that your KCL application is performing as expected. Additionally, you can learn how to create new Environments for different versions of your KCL application using Elastic Beanstalk. You can also upgrade the software using new Application Versions.
If you have questions or suggestions, please enter a comment below.
—————————————————————
Related:
Snakes in the Stream! Feeding and Eating Amazon Kinesis Streams with Python