AWS Big Data Blog
Introducing new features for Amazon Redshift COPY: Part 1
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as high-performance business intelligence (BI) reporting, dashboarding applications, data exploration, and real-time analytics.
Loading data is a key process for any analytical system, including Amazon Redshift. Loading very large datasets can take a long time and consume a lot of computing resources. How your data is loaded can also affect query performance. You can use many different methods to load data into Amazon Redshift. One of the fastest and most scalable methods is to use the COPY command. This post dives into some of the recent enhancements made to the COPY command and how to use them effectively.
Overview of the COPY command
A best practice for loading data into Amazon Redshift is to use the COPY command. The COPY command loads data in parallel from Amazon Simple Storage Service (Amazon S3), Amazon EMR, Amazon DynamoDB, or multiple data sources on any remote hosts accessible through a Secure Shell (SSH) connection.
The COPY command reads and loads data in parallel from a file or multiple files in an S3 bucket. You can take maximum advantage of parallel processing by splitting your data into multiple files, in cases where the files are compressed. The COPY command appends the new input data to any existing rows in the target table. The COPY command can load data from Amazon S3 for the file formats AVRO, CSV, JSON, and TXT, and for columnar format files such as ORC and Parquet.
Use COPY with FILLRECORD
In situations when the contiguous fields are missing at the end of some of the records for data files being loaded, COPY reports an error indicating that there is mismatch between the number of fields in the file being loaded and the number of columns in the target table. In some situations, columnar files (such as Parquet) that are produced by applications and ingested into Amazon Redshift via COPY may have additional fields added to the files (and new columns to the target Amazon Redshift table) over time. In such cases, these files may have values absent for certain newly added fields. To load these files, you previously had to either preprocess the files to fill up values in the missing fields before loading the files using the COPY command, or use Amazon Redshift Spectrum to read the files from Amazon S3 and then use INSERT INTO to load data into the Amazon Redshift table.
With the FILLRECORD parameter, you can now load data files with a varying number of fields successfully in the same COPY command, as long as the target table has all columns defined. The FILLRECORD parameter addresses ease of use because you can now directly use the COPY command to load columnar files with varying fields into Amazon Redshift instead of achieving the same result with multiple steps.
With the FILLRECORD parameter, missing columns are loaded as NULLs. For text and CSV formats, if the missing column is a VARCHAR column, zero-length strings are loaded instead of NULLs. To load NULLs to VARCHAR columns from text and CSV, specify the EMPTYASNULL keyword. NULL substitution only works if the column definition allows NULLs.
Use FILLRECORD while loading Parquet data from Amazon S3
In this section, we demonstrate the utility of FILLRECORD by using a Parquet file that has a smaller number of fields populated than the number of columns in the target Amazon Redshift table. First we try to load the file into the table without the FILLRECORD parameter in the COPY command, then we use the FILLRECORD parameter in the COPY command.
For the purpose of this demonstration, we have created the following components:
- An Amazon Redshift cluster with a database, public schema, awsuser as admin user, and an AWS Identity and Access Management (IAM) role, used to perform the COPY command to load the file from Amazon S3, attached to the Amazon Redshift cluster. For details on authorizing Amazon Redshift to access other AWS services, refer to Authorizing Amazon Redshift to access other AWS services on your behalf.
- An Amazon Redshift table named
call_center_parquet. - A Parquet file already uploaded to an S3 bucket from where the file is copied into the Amazon Redshift cluster.
The following code is the definition of the call_center_parquet table:
The table has 31 columns.
The Parquet file doesn’t contain any value for the cc_gmt_offset and cc_tax_percentage fields. It has 29 columns. The following screenshot shows the schema definition for the Parquet file located in Amazon S3, which we load into Amazon Redshift.

We ran the COPY command two different ways: with or without the FILLRECORD parameter.
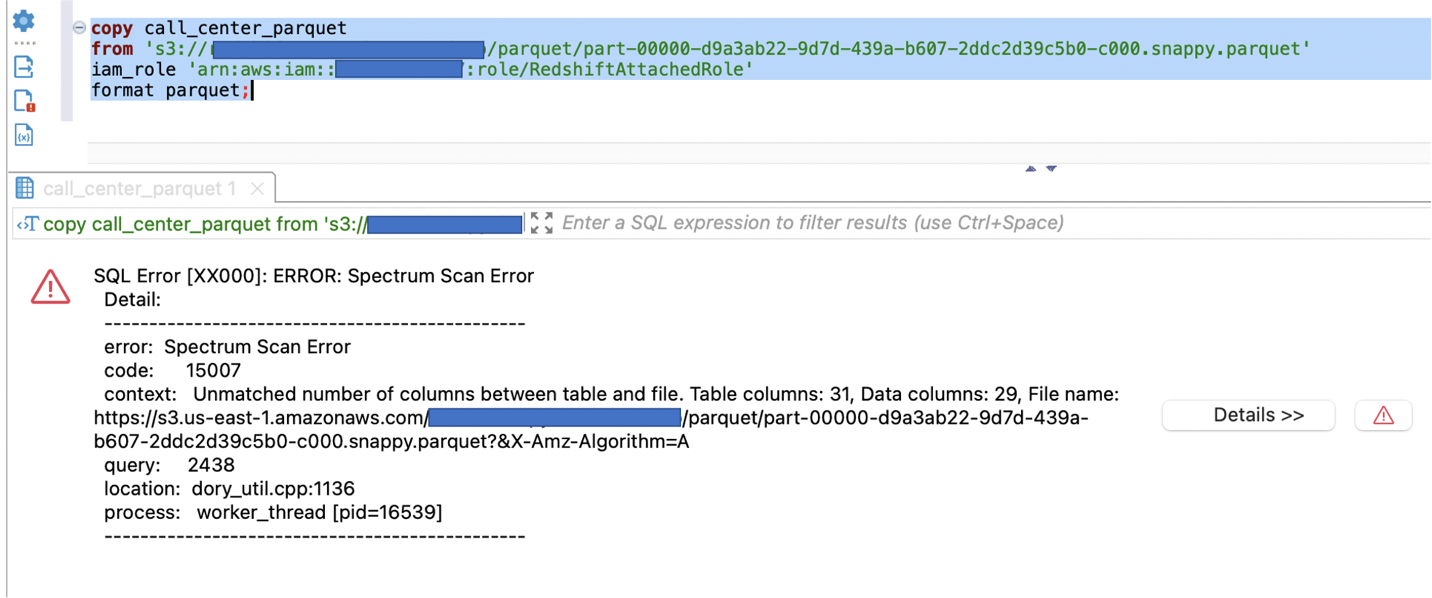
We first tried to load the Parquet file into the call_center_parquet table without the FILLRECORD parameter:
It generated an error while performing the copy.
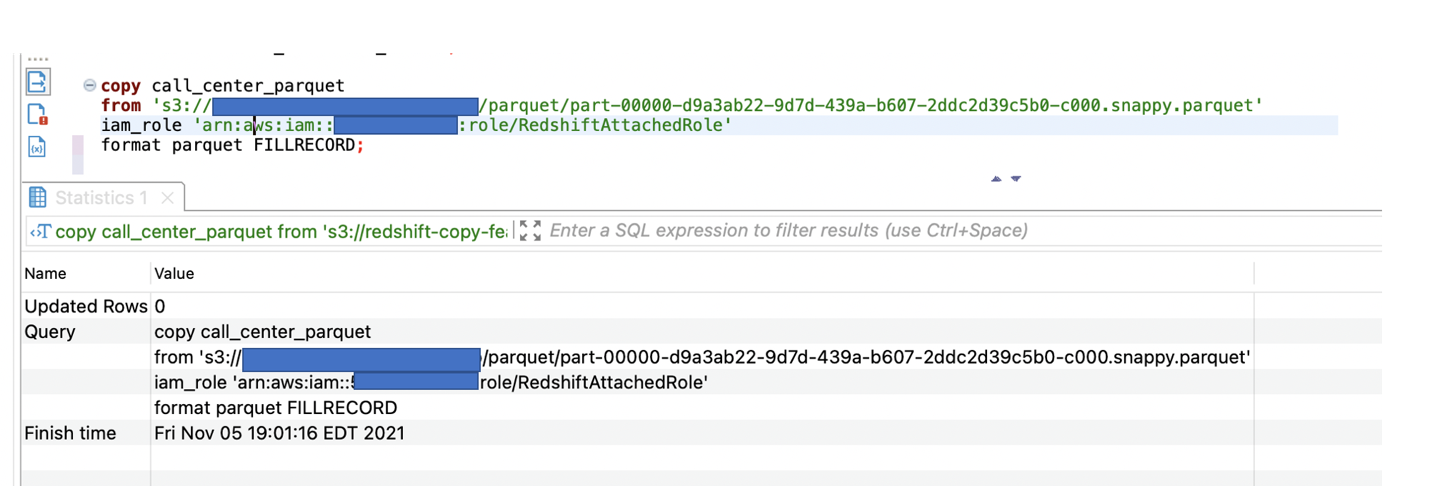
Next, we tried to load the Parquet file into the call_center_parquet table and used the FILLRECORD parameter:
The Parquet data was loaded successfully in the call_center_parquet table, and NULL was entered into the cc_gmt_offset and cc_tax_percentage columns.
Split large text files while copying
The second new feature we discuss in this post is automatically splitting large files to take advantage of the massive parallelism of the Amazon Redshift cluster. A best practice when using the COPY command in Amazon Redshift is to load data using a single COPY command from multiple data files. This loads data in parallel by dividing the workload among the nodes and slices in the Amazon Redshift cluster. When all the data from a single file or small number of large files is loaded, Amazon Redshift is forced to perform a much slower serialized load, because the Amazon Redshift COPY command can’t utilize the parallelism of the Amazon Redshift cluster. You have to write additional preprocessing steps to split the large files into smaller files so that the COPY command loads data in parallel into the Amazon Redshift cluster.
The COPY command now supports automatically splitting a single file into multiple smaller scan ranges. This feature is currently supported only for large uncompressed delimited text files. More file formats and options, such as COPY with CSV keyword, will be added in the near future.
This helps improve performance for COPY queries when loading a small number of large uncompressed delimited text files into your Amazon Redshift cluster. Scan ranges are implemented by splitting the files into 64 MB chunks, which get assigned to each Amazon Redshift slice. This change addresses ease of use because you don’t need to split large uncompressed text files as an additional preprocessing step.
With Amazon Redshift’s ability to split large uncompressed text files, you can see performance improvements for the COPY command with a single large file or a few files with significantly varying relative sizes (for example, one file 5 GB in size and 20 files of a few KBs). Performance improvements for the COPY command are more significant as the file size increases even with keeping the same Amazon Redshift cluster configuration. Based on tests done, we observed a more than 1,500% performance improvement for the COPY command for loading a 6 GB uncompressed text file when the auto splitting feature became available.
There are no changes in the COPY query or keywords to enable this change, and splitting of files is automatically applied for the eligible COPY commands. Splitting isn’t applicable for the COPY query with the keywords CSV, REMOVEQUOTES, ESCAPE, and FIXEDWIDTH.
For the test, we used a single 6 GB uncompressed text file and the following COPY command:
The Amazon Redshift cluster without the auto split option took 102 seconds to copy the file from Amazon S3 to the Amazon Redshift store_sales table. When the auto split option was enabled in the Amazon Redshift cluster (without any other configuration changes), the same 6 GB uncompressed text file took just 6.19 seconds to copy the file from Amazon S3 to the store_sales table.
Summary
In this post, we showed two enhancements to the Amazon Redshift COPY command. First, we showed how you can add the FILLRECORD parameter in the COPY command in order to successfully load data files even when the contiguous fields are missing at the end of some of the records, as long as the target table has all the columns. Secondly, we described how Amazon Redshift auto splits large uncompressed text files into 64 MB chunks before copying the files into the Amazon Redshift cluster to enhance COPY performance. This automatic split of large files allows you to use the COPY command on large uncompressed text files—Amazon Redshift auto splits the file without needing you to add a preprocessing step to the split the large files yourself. Try these features to make your data loading to Amazon Redshift much simpler by removing custom preprocessing steps.
In Part 2 of this series, we will discuss additional new features of Amazon Redshift COPY command and demonstrate how you can take benefits of those to optimize your data loading process.
About the Authors
 Dipankar Kushari is a Senior Analytics Solutions Architect with AWS.
Dipankar Kushari is a Senior Analytics Solutions Architect with AWS.
 Cody Cunningham is a Software Development Engineer with AWS, working on data ingestion for Amazon Redshift.
Cody Cunningham is a Software Development Engineer with AWS, working on data ingestion for Amazon Redshift.
 Joe Yong is a Senior Technical Product Manager on the Amazon Redshift team and a relentless pursuer of making complex database technologies easy and intuitive for the masses. He has worked on database and data management systems for SMP, MPP, and distributed systems. Joe has shipped dozens of features for on-premises and cloud-native databases that serve IoT devices through petabyte-sized cloud data warehouses. Off keyboard, Joe tries to onsight 5.11s, hunt for good eats, and seek a cure for his Australian Labradoodle’s obsession with squeaky tennis balls.
Joe Yong is a Senior Technical Product Manager on the Amazon Redshift team and a relentless pursuer of making complex database technologies easy and intuitive for the masses. He has worked on database and data management systems for SMP, MPP, and distributed systems. Joe has shipped dozens of features for on-premises and cloud-native databases that serve IoT devices through petabyte-sized cloud data warehouses. Off keyboard, Joe tries to onsight 5.11s, hunt for good eats, and seek a cure for his Australian Labradoodle’s obsession with squeaky tennis balls.
 Anshul Purohit is a Software Development Engineer with AWS, working on data ingestion and query processing for Amazon Redshift.
Anshul Purohit is a Software Development Engineer with AWS, working on data ingestion and query processing for Amazon Redshift.