AWS Big Data Blog
Scaling Writes on Amazon DynamoDB Tables with Global Secondary Indexes
Ian Meyers is a Solutions Architecture Senior Manager with AWS
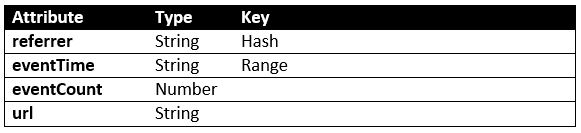
Amazon DynamoDB is a fast, flexible, and fully managed NoSQL database service that supports both document and key-value store models that need consistent, single-digit millisecond latency at any scale. In this post, we discuss a technique that can be used with DynamoDB to ensure virtually unlimited scaling when using secondary indexes. We focus on a data structure that provides data as a time series, commonly used for real-time analytics.
Time series tables
A time series table stores a broad range of values like any table, but organizes and sequences the data by a unit of time. This allows us to compare values that occurred in one time period to the values that occurred in another, given a common set of criteria. You would use a time series to answer questions such as ‘what is the revenue this quarter vs. the same quarter last year?’ or ‘what is the busiest hour over the course of a month?’
The time series that we reference today is a common requirement for many customers: ad impressions and click events over time, to facilitate the analysis of referring websites. For this solution, we want to be able to track the referring site URL or ID (referrer), when the event occurred, and how many clicks or impressions occurred over a period.
In DynamoDB, tables are accessed through a variety of mechanisms. Each table contains multiple items, where each item is composed of multiple attributes. For every table, you specify a primary key, which consists of either a hash or “hash and range” attribute.
Primary keys for time series tables
To create our time series table, we create a table with a hash and range primary key, which allows us to look up an item using two discrete values. The hash key for our table is the referrer. The range key is the date and time from within the impression or click event, stored at some downsampled time granularity such as ‘per-minute’ or ‘per-hour’. We downsample for simplicity of looking up specific time values for a referrer, but also because this significantly reduces the size of the hash and range key.
To perform this downsampling, we take a given event time and reduce it to the time period in which it occurred. For example, downsampling the value ‘2015-15-06 10:31:32’ to ‘per-hour’ would result in a value of ‘2015-15-06 10:00:00’, while ‘per-minute’ would give us ‘2015-15-06 10:31:00’.
This data structure allows us to receive an event, and then very efficiently update the aggregation of that event for the time period in which it occurred by the event’s referrer and the downsampled timestamp.
Local secondary indexes
In the same way that we can use the hash/range primary key to access a table, we can create multiple local secondary indexes that use the table’s existing hash key plus another attribute for access. When we create the index, we can select other non-indexed attributes to include, or project, into the index. These indexes are useful when we know the hash key, but want to be able to access data on the basis of multiple different attributes with extremely high performance.
In our example, we might want to find the referrers who created events for a specific page. A local secondary index on the referrer plus the URL would allow us to find those referrers who specifically accessed one page vs. another, out of all of the URLs accessed.

Global secondary indexes
Global secondary indexes give us the ability to create entirely new hash or hash/range indexes for a table from other attributes. As with local secondary indexes, we can choose which table attributes to project into an index. These indexes are useful when we want to access by different attributes than the hash/range key but with the same performance.
In our example, we definitely want to be able to see the events that occurred in a date range; for example, ‘show me new records since time N’. In our time series table, we can create a new global secondary index just on eventTime, which allows us to scan the table efficiently with DynamoDB query expressions such as ‘eventTime >= :querytime’.

Processing time series data with elastic throughput
To populate this time series table, we must receive the impression and click events, and then downsample and aggregate the data in our time series table. A powerful way to do this, without managing any servers, is to use Amazon Kinesis to stream events and AWS Lambda to process them, as shown in the following graphic.

When we implement a Lambda function for this architecture, we see that we get multiple Amazon Kinesis records in a single function invocation, for a narrow time period as defined by the producer of the data. In this type of application, we want to buffer events in memory up to some threshold before writing to DynamoDB, so that we limit the I/O use on the table.
The required write rate on our table is defined by the number of unique referrers we are provided with when processing data, multiplied by the duration of ‘downsampled time’ for this set of events. For example, if we have an event stream of 2000 events per second and 200 unique referrers, and we receive 5000 events into our Lambda function invocation, then we would expect to require:
((EventsReceived / EventsPerSecond) * UniqueReferrerCount) / NumberOfSecondsDownsampled
((5000 / 2000 = 2.5) * 200 = 500) / 1 = 500 writes/second
We can set provisioned write IOPS on our DynamoDB table to 550 (to give ourselves a bit of headroom), and then scale up and down over time as the event rate changes. However, we don’t just require this write IOPS for the table, but also for the global secondary index on eventTime.

The accidental bottleneck
DynamoDB provisioned throughput is set on a table or index as a whole, and is divided up among many partitions that store data. The partition is selected on the basis of the hash key and at most, DynamoDB offers approximately 1000 writes/second to a single hash key value on a partition.
This won’t be a problem for our main table, because the 500 writes/second are spread over the 200 unique referrer values that make up the hash/range key for a specific downsampled time value. However, our global secondary index only has a single hash key value, eventTime, and so we write to only one partition. This will not achieve the required 500 writes/second on a given eventTime value. With the global secondary index as defined, we observe write throttling and timeouts, and because global secondary indexes are written asynchronously, we also observe an increased latency between the write to the table and the update of the secondary index.

No matter how high we provision the write IOPS on the index, we will always see throttling because we are focusing our writes to a single key (eventTime), and thus a single partition.
Addressing write bottlenecks with scattering
This problem can be solved by introducing a write pattern called scattering. Later, we review how we can re-gather this data at query time or in an asynchronous process to give us a simple model for reads.
We avoided a write bottleneck on our table because the writes are distributed across the 200 unique referrers to our site. We can use this same principle to remove the bottleneck on our global secondary index. Instead of creating the index on eventTime alone, we can convert it to a hash/range index on a new attribute ‘scatteredValue’ plus ‘eventTime’. scatteredValue is a synthetic column into which we write a random number between 0 and 99 every time we create or update a record.

This leading random value in the index enables DynamoDB to spread the writes over a larger number of partitions. We’re writing 100 unique values, so DynamoDB can scale to 100 partitions. This means that we can achieve 1000 * cardinality of scatter value (100) = 100,000 writes/second for a single eventTime value. This is much better!
If we needed even more writes/second, then we could increase to 1000 unique scatteredValue entries (0-999). Our table writes now execute without any throttling, and data in our global secondary index does not lag significantly behind the table.
Gathering scattered records together
We originally created the global secondary index on eventTime so that we could ask a query such as ‘what aggregate events happened after time N?’ Now that the index is on scatteredValue/eventTime, we can’t just query the eventTime attribute. However, we can take advantage of the DynamoDB parallel scan feature to easily gather all the relevant records together.
To do this, we create multiple worker threads in our application, who each scan several scatteredValue entries and apply an expression to the eventTime. If we use 10 parallel workers, then worker 0 must scan scatteredValue between 0 and 9, worker 1 scans values between 10 and 19, and so on, until worker 10 scans scatteredValue between 90 and 99. This can be visualized as by the following graphic:
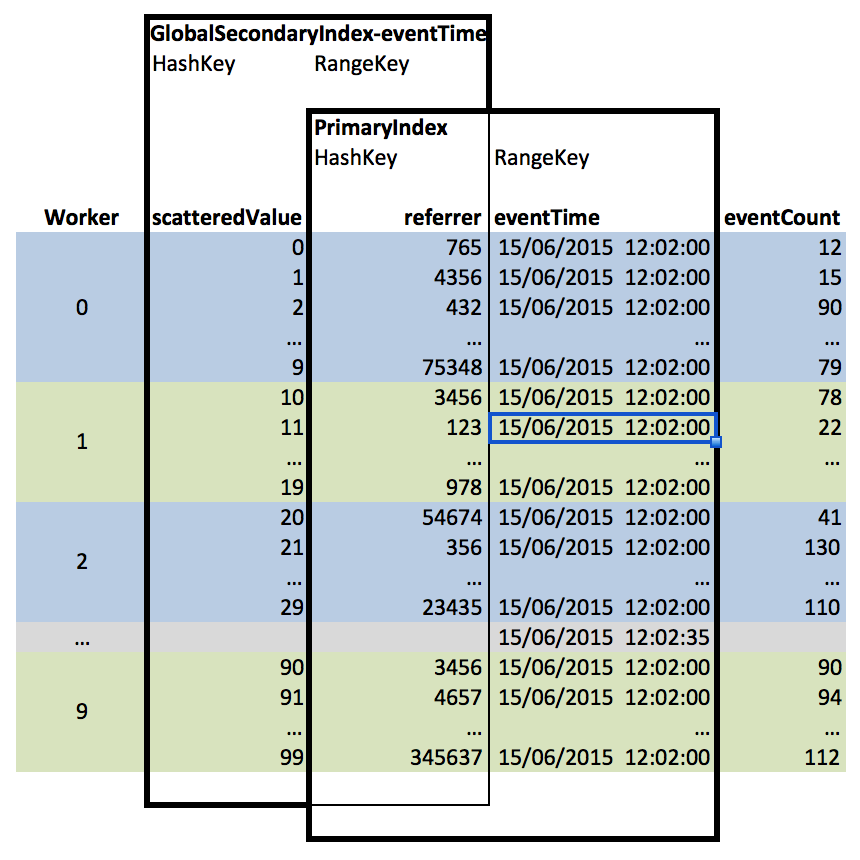
These workers can then provide a unique list of hash/range key values on referrer/eventTime (which are always projected into a global secondary index) or, if we decided to project eventCount into the index, we could simply use this value directly with an aggregation.
For those who would like to implement a parallel gather reader, an example of this implemented in Node.js is available in the appendix.
Summary
Global secondary indexes offer a powerful mechanism to allow you to query complex data structures, but in certain cases they can result in write bottlenecks that cannot be addressed by simply increasing the write IOPS on the DynamoDB table or index. By using a random value as the hash key of a global secondary index, we can evenly spread the write load across multiple DynamoDB partitions, and then we can use this index at query time via the parallel Scan API. This approach offers us the ability to scale writes on a table with a complex index structure to any required write rate.
Further Resources
For more information about using this type of data structure, you can review Amazon Kinesis Aggregators aggregators (https://github.com/awslabs/amazon-kinesis-aggregators), a framework designed for automatic time series analysis of data streamed from Amazon Kinesis. In this codebase, DynamoDataStore and DynamoQueryEngine implement the scatter/gather pattern, and are available for re-use in other AWS applications.
If you have questions or suggestions, please leave a comment below.
Appendix 1: Sample code to query time series data from DynamoDB
var region = process.env['AWS_REGION'];
var async = require('async');
var aws = require('aws-sdk');
aws.config.update({
region : region
});
var dynamoDB = new aws.DynamoDB({
apiVersion : '2012-08-10',
region : region
});
// generate an array of integers between start and start+count
var range = function(start, count) {
return Array.apply(0, Array(count)).map(function(element, index) {
return index + start;
});
};
// function to query DynamoDB for a specific date time value and scatter prefix
var gatherQueryDDB = function(dateTimeValue, index, callback) {
var params = {
TableName : "myDynamoTable",
IndexName : "myGsiOnEventTime",
KeyConditionExpression : "scatterPrefix = :index and eventTime = :date",
ExpressionAttributeValues : {
":index" : {
N : '' + index
},
":date" : {
S : dateTimeValue
}
}
};
dynamoDB.query(params, function(err, data) {
if (err) {
callback(err);
} else {
callback(null, data.Items);
}
});
};
// function which prints the results of the worker scan
var printResults = function(err, results) {
if (err) {
console.log(JSON.stringify(err));
process.exit(-1);
} else {
results.map(function(item) {
if (item && item.length > 0) {
console.log(JSON.stringify(item));
}
});
}
};
/* set this range to the scatter prefix size */
var scatteredValues = range(0, 100);
/* set this value to how many concurrent reads to do against the table */
var concurrentReads = 20;
async.mapLimit(scatteredValues, concurrentReads, gatherQueryDDB.bind(undefined, "date query value in yyyy-MM-dd HH:mm:ss format"), printResults);
Related:
Powering Gaming Applications with DynamoDB