AWS Compute Blog
Category: Amazon Simple Storage Service (S3)

Enhancing file sharing using Amazon S3 and AWS Step Functions
In this blog post, you learn how you can securely share files with authorized external parties and track their access using AWS serverless services. The sample application presented uses Step Functions to allow you to extend and customize the workflows to meet your use case requirements.

Deploying low-latency hybrid cloud storage on AWS Local Zones using AWS Storage Gateway
This blog post is written by Ruchi Nigam, Senior Cloud Support Engineer and Sumit Menaria, Senior Hybrid SA. AWS Local Zones are a type of infrastructure deployment that places compute, storage, database, and other select AWS services close to large population and industry centers. With Local Zones close to large population centers in metro areas, […]

Deploying an automated Amazon CloudWatch dashboard for AWS Outposts using AWS CDK
This post is written by Enrico Liguori, Networking Solutions Architect, Hybrid Cloud and Sumeeth Siriyur, Sr. Hybrid Cloud Solutions Architect. AWS Outposts is a fully managed service that brings the same AWS infrastructure, services, APIs, and tools to virtually any data center, colocation space, manufacturing floor, or on-premises facility where it might be needed. With Outposts, […]
Introducing AWS Lambda response streaming
Today, AWS Lambda is announcing support for response payload streaming. Response streaming is a new invocation pattern that lets functions progressively stream response payloads back to clients. You can use Lambda response payload streaming to send response data to callers as it becomes available. This can improve performance for web and mobile applications. Response streaming […]
Serverless ICYMI Q1 2023
February 12, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Welcome to the 21st edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, […]
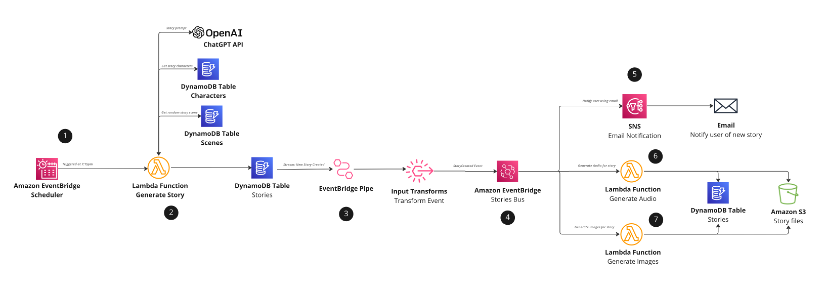
Implementing an event-driven serverless story generation application with ChatGPT and DALL-E
This post demonstrates how to integrate AWS serverless services with artificial intelligence (AI) technologies, ChatGPT, and DALL-E. This full stack event-driven application showcases a method of generating unique bedtime stories for children by using predetermined characters and scenes as a prompt for ChatGPT. Every night at bedtime, the serverless scheduler triggers the application, initiating an […]
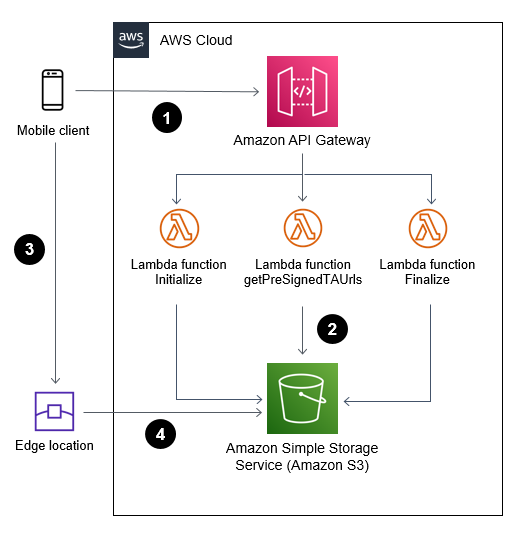
Uploading large objects to Amazon S3 using multipart upload and transfer acceleration
This blog shows how web and mobile applications can upload large objects to Amazon S3 in a secured and efficient manner when using presigned URLs and multipart upload.

Quick Restoration through Replacing the Root Volumes of Amazon EC2 instances
This blog post is written by Katja-Maja Krödel, IoT Specialist Solutions Architect, and Benjamin Meyer, Senior Solutions Architect, Game Tech. Customers use Amazon Elastic Compute Cloud (Amazon EC2) instances to develop, deploy, and test applications. To use those instances most effectively, customers have expressed the need to set back their instance to a previous state […]

Lifting and shifting a web application to AWS Serverless: Part 2
In this two-part article, you learn if it is possible to migrate a non-serverless web application to a serverless environment without changing much code. You learn different tools that can help you in this process, like AWS Lambda Web Adaptor and AWS Amplify, and how to solve some of the typical challenges that we have, like storage and authentication.
Lifting and shifting a web application to AWS Serverless: Part 1
In this article, you learn if it is possible to migrate a non-serverless web application to a serverless environment without changing much code. You learn different tools that can help you in this process, like the AWS Lambda Web Adaptor and AWS Amplify.