AWS Compute Blog
Migrate Wildfly Cluster to Amazon ECS using Service Discovery
This post is courtesy of Vidya Narasimhan, AWS Solutions Architect
1. Overview
Java Enterprise Edition has been an important server-side platform for over a decade for developing mission-critical & large-scale applications amongst enterprises. High-availability & fault tolerance for such applications is typically achieved through built-in JEE clustering provided by the platform.
JEE clustering represents a group of machines working together to transparently provide enterprise services such as JNDI, EJB, JMS, HTTPSession etc. that enable distribution, discovery, messaging, transaction, caching, replication & component failover. Implementation of clustering technology varies in JEE platforms provided by different vendors. Many of the clustering implementations involve proprietary communication protocols that use multicast for intra-cluster communications that is not supported in public cloud.
This article is relevant for JEE platforms & other products that use JGroups based clustering such as Wildfly. The solution described allows easy migration of applications developed on these platforms using native clustering to Amazon Elastic Container Service (Amazon ECS) which is a highly scalable, fast, container management service that makes it easy to orchestrate, run & scale Docker containers on a cluster. This solution is useful when the business objective is to migrate to cloud fast with minimum changes to the application. The approach recommends lift & shift to AWS wherein the initial focus is to migrate as-is with optimizations coming in later incrementally.
Whether the JEE application to be migrated is designed as a monolith or micro services, a legacy or green-field deployment, there are multiple reasons why organizations should opt for containerization of their application. This link explains well the benefits of containerization (see section Why Use Containers) https://aws.amazon.com/getting-started/projects/break-monolith-app-microservices-ecs-docker-ec2/module-one/
2. Wildfly Clustering on ECS
Here onwards, this article highlights how to migrate a standard clustered JEE app deployed on Wildfly Application Server to Amazon ECS. Wildfly supports clustering out of the box and supports two modes of clustering, standalone & domain mode. This article explores how to setup WildFly cluster in ECS with multiple Wildfly standalone nodes enabled for HA to form a cluster. The clustering is demonstrated through a web application that replicates session information across the cluster nodes and can withstand a failover without session data loss.
The important components of clustering that requires a mention right away are ECS Service Discovery, JGroups & Infinispan.
- JGroups – Wildfly clustering is enabled by the popular open-source JGroups toolkit. The JGroups subsystem provides group communication support for HA services using a multicast transmission by default. It deals with all aspects of node discovery and providing reliable messaging between the nodes as follows-
- Node-to-node messaging — By default is based on UDP/multicast that can be extended via TCP/unicast.
- Node discovery — By default uses multicast ping MPING. Alternatives include TCPPING, S3_PING, JDBC_PING, DNS_PING and others.
This article focusses on DNS_PING for node discovery using TCP protocol.
ECS Service discovery – Amazon ECS service can optionally be configured to use Amazon ECS Service Discovery. Service discovery uses Amazon Route 53 auto naming API actions to manage DNS entries (A or SRV records) for service tasks, making them discoverable within your VPC. You can specify health check conditions in a service task definition and Amazon ECS will ensure that only healthy service endpoints are returned by a service lookup.
As your services scale up or down in response to load or container health, the Route 53 hosted zone is kept up to date.
Wildfly uses JGroups to discover the cluster nodes via DNS_PING discovery protocol that sends a DNS service endpoint query to the ECS service registry maintained in Route53.

- Infinispan – Wildfly uses Infinispan subsystem to provides high-performance, clustered, transactional caching. In a clustered web application, Infinispan handles the replication of application data across the cluster by means of a replicated/distributed cache. Under the hood, it uses JGroups channel for data transmission within the cluster.
3. Implementation Instructions
Configure Wildfly
- Modify Wildfly standalone configuration file – Standalone-HA.xml. The HA suffix implies high availability configuration.
- Modify the JGroup Subsystem – Add a TCP Stack with DNS_Ping as the discovery protocol & configure the DNS Query endpoint. It is important to note that the DNS_QUERY matches the ECS service endpoint when configuring the ECS service.

- Change the JGroup default stack to point to the TCP Stack.

- Configure a custom Infinispan replicated cache to be used by the web app or use the default cache.

Build the docker image & store it in Elastic Container Registry (ECR)
- Package the JBoss/Wildfly image with JEE application & Wildfly platform on Docker. Create a Dockerfile & include the following:
- Install the WildFly distribution & set permissions – This approach requires the latest Wildfly distribution 15.0.0.Final released recently.

- Copy the modified Wildfly standalone-ha.xml to the container.
- Deploy the JEE web application. This simple web app is configured as distributable and uses Infinispan to replicate session information across cluster nodes. It displays a page containing the container IP/hostname, Session ID & session data & helps demonstrate session replication.

- Define a custom entrypoint, entrypoint.sh, to boot Wildfly with the specified bind IP addresses to its interfaces. The script gets the container metadata, extracts the container IP to bind it to Wildfly interfaces. This interface binding is an important step as it enables the application related network communication (web, messaging) between the containers.

- Add the enrypoint.sh script to the image in the Dockerfile.

- Build the container & push it to ECR repository. Amazon Elastic Container Registry (ECR) is a fully managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images.
- Install the WildFly distribution & set permissions – This approach requires the latest Wildfly distribution 15.0.0.Final released recently.
The Wildly configuration files, the Dockerfile & the web app WAR file can be found at the Github link https://github.com/vidyann/Wildfly_ECS
Create ECS Service with service discovery
- Create a Service using service discovery.
- This link describe steps to set up a ECS task & service with service discovery https://docs.aws.amazon.com/AmazonECS/latest/developerguide/create-service-discovery.html#create-service-discovery-taskdef. Though the example in the link creates a Fargate cluster, you can create an EC2 based cluster as well for this example.
- While configuring the task choose the network mode as AWSVPC. The task networking features provided by the AWSVPC network mode give Amazon ECS tasks the same networking properties as Amazon EC2 instances. Benefits of task networking can be found here – https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-networking.html
- Tasks can be flagged as compatible with EC2, Fargate, or both. Here is what the cluster & service looks like:
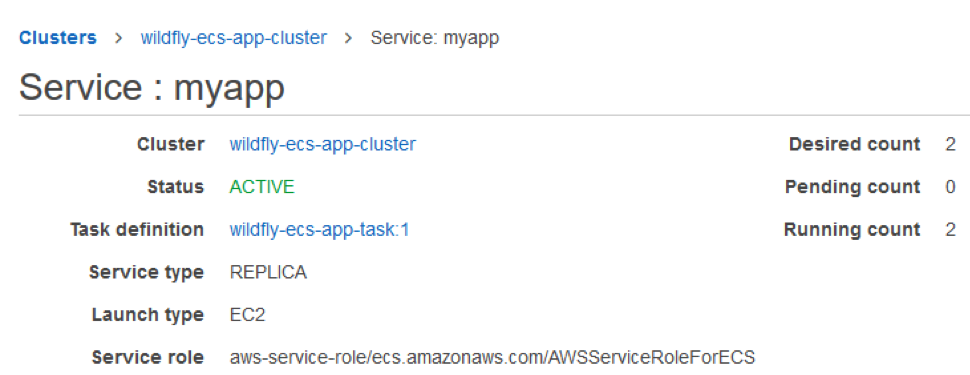
- When setting up the container details in task, use 8080 as the port, which is the default Wildfly port. This can be changed through WIldfly configuration. Enable the cloudwatch logs which captures Wildfly logging.
- While configuring the ECS service, ensure that the service name & namespace should combine to form service endpoint that exactly matches the DNS_Query endpoint configured in Wildfly configuration file. The container security group should allow inbound traffic to port 8080. Here is what the service endpoint looks like:

- The route53 registry created by ECS is shown below. We see two DNS entries corresponding to the DNS endpoint myapp.sampleaws.com.

- Finally view the Wildfly logs in the console by clicking a task instance. You can check if clustering is enabled by looking for a log entry as below:

Here we see that a Wildfly cluster was formed with two nodes(same as the pic in route 53).
Run the Web App in a browser
- Spin up a windows instance in the VPC & open the web app in a browser. Below is a screenshot of the webapp:

- Open in different browsers & tabs & verify the Container IP & session ID. Now force shutdown a node by resizing the ECS service task instances to one. Note that though the container IP in the webapp changes, the session ID does not change and the webapp is available and the HTTP Session is alive thus demonstrating the session replication & failover amongst the clustering nodes.
4. Summary
Our goal here is to migrate the enterprise JEE apps to Amazon ECS by tweaking a few configurations but gaining immediately the benefits of containerization & orchestration managed by ECS. By delegating the undifferentiated heavy lifting of container management, orchestration, scaling to ECS, you can focus on improvising/re-architecting your application to micro-services oriented architecture. Please note that all the deployment procedures in this article can be fully automated via the AWS CI/CD services.