Containers
Introducing Data on EKS – Modernize Data Workloads on Amazon EKS
Introduction
We are thrilled to introduce Data on EKS (DoEKS), a new open-source project aimed at streamlining and accelerating the process of building, deploying, and scaling data workloads on Amazon Elastic Kubernetes Service (Amazon EKS).
With DoEKS, customers get access to a comprehensive range of resources including Infrastructure as Code (IaC) templates, performance benchmark reports, deployment examples, and architectures optimized for data-centric workloads aligned with AWS best practices and industry expertise. This means that customers can quickly and easily provision popular open-source data frameworks (e.g., Apache Spark, Ray, Apache Airflow, Argo Workflows, and Kubeflow) to run on Amazon EKS. Additionally, DoEKS areas of focus include distributed streaming platforms, query engines, and databases to meet the growing demands of data processing. DoEKS blueprints are made with managed AWS services and popular open-source tools to provide customers flexibility to choose the right combination of managed and self-managed components to suit their needs. For example, DoEKS includes several blueprints with Amazon EMR on EKS so customers can take advantage of optimized features like automated provisioning, scaling, faster runtimes, and debugging tools that Amazon EMR provides for running Spark applications.
Come be part of this exciting new project and take the first step toward revolutionizing your data processing on Amazon EKS. To get started, visit our documentation site.
Motivation
With the increasing importance of Big Data and Machine Learning (AI/ML) to global businesses and industries, Kubernetes has emerged as a popular platform to run data workloads due to improved agility, scalability, and portability. Kubernetes offers improved portability for data workloads between different environments, such as on-premise data centers, public clouds, and edge locations. It provides a unified environment for managing both stateful and stateless applications, making it easier to run a wide range of data workloads. Furthermore, Kubernetes supports frameworks like Spark, Flink, PyTorch, TensorFlow, and others, making it easier to run data processing jobs and orchestrate ML pipelines in cloud-native or on-prem environments. This has resulted in Kubernetes becoming an increasingly popular choice for AWS customers who want to run Big Data and AI/ML workloads, with many customers embracing the use of Amazon Elastic Container Service for Kubernetes (Amazon EKS) for their next-generation data platforms. The aim of these data platforms is to simplify data processing and analysis to extract valuable insights and drive value creation, provide a competitive edge, and enhance customer experiences.
However, deploying and scaling data workloads on Kubernetes remains a challenge for many customers. There are multiple conflicting tools with varying levels of maturity, integration, and compatibility with existing platforms that can be overwhelming. These workloads are often high-throughput, compute-intensive, and critical to business operations, requiring a proper configuration to support their requirements.
We are launching Data on EKS (DoEKS) to simplify and speed up the process of building, deploying, and scaling data workloads on Amazon EKS. DoEKS offers IaC templates in Terraform and AWS Cloud Development Kit (AWS CDK), performance benchmark reports, best practices, and sample code to help users run applications like Spark, Kubeflow, MLFlow, Airflow, Presto, Kafka, Cassandra, and more on Amazon EKS with ease.
What is Data on EKS?
Data on EKS (DoEKS) provides best practices, examples, and architectures aimed at making it easier to build, deploy, and scale data-intensive workloads on Amazon Elastic Kubernetes Service (Amazon EKS). It builds on the foundation of the Amazon EKS Blueprints project and incorporates guidance and tools to support the unique challenges and requirements of data-related workloads on Kubernetes.
Customers have asked for best practices and benchmarks for enterprise grade performance at scale. In addition to open-source tools, many customers want to use AWS managed services, like Amazon Managed Streaming for Apache Kafka (Amazon MSK) for data ingestion or Amazon EMR for batch processing, to offload some undifferentiated heavy lifting for parts of their pipeline. Data on EKS addresses these common questions and concerns from customers running data-centric workloads using tools such as Spark, Flink, Kafka, Ray, and more. It helps customers configure observability and logging, implement multi-tenancy for resource sharing among data teams, and choose the right cluster autoscalers (Karpenter), Kubernetes batch schedulers (Apache YuniKorn), and job schedulers (Amazon MWAA, Airflow, Argo Workflows, etc.).
One of the main areas of focus for DoEKS is running Spark on Amazon EKS. Customers often have questions on storage types (e.g., solid-state drive (SSD), persistent volume claim (PVC) with Amazon EBS or Amazon FSx for Lustre), preferred Amazon Elastic Compute Cloud (Amazon EC2) instance types for compute and memory intensive workloads, networking with Spark workloads using VPC CNI, enabling the Spark history server for debugging, and monitoring job metrics. DoEKS provides an opinionated way to configure these applications based on best practices and industry expertise, providing customers simplified and integrated options for efficiently running Spark on Amazon EKS.
The DoEKS project is continually evolving to meet the evolving needs of our customers. It covers five main focus areas including Data Analytics, AI/ML, Distributed Database & Query Engines, Streaming Data Platforms, and Job & Workflow Schedulers. Although it already encompasses most of these areas, many of the blueprints are still being developed, reflecting the projects ongoing commitment to improvement. Visit the Github repository for a full list of available blueprints, including those still in progress.
Data on Amazon EKS patterns can be used to provision Amazon EKS environments in any AWS Region where Amazon EKS is available. With these patterns, you pay only for the resources you deploy. For example, if you deploy an Amazon EKS cluster with a Managed Node Group, you incur standard Amazon EKS and Amazon EC2 charges.
Solution overview
Data on EKS components
The following diagram illustrates the open-source data tools, Kubernetes operators, and frameworks covered by DoEKS, as well as the integration of AWS Data Analytics managed services. It should be noted that this list is only representative and we’ll continue to evolve these components based on our experience and customer feedback.
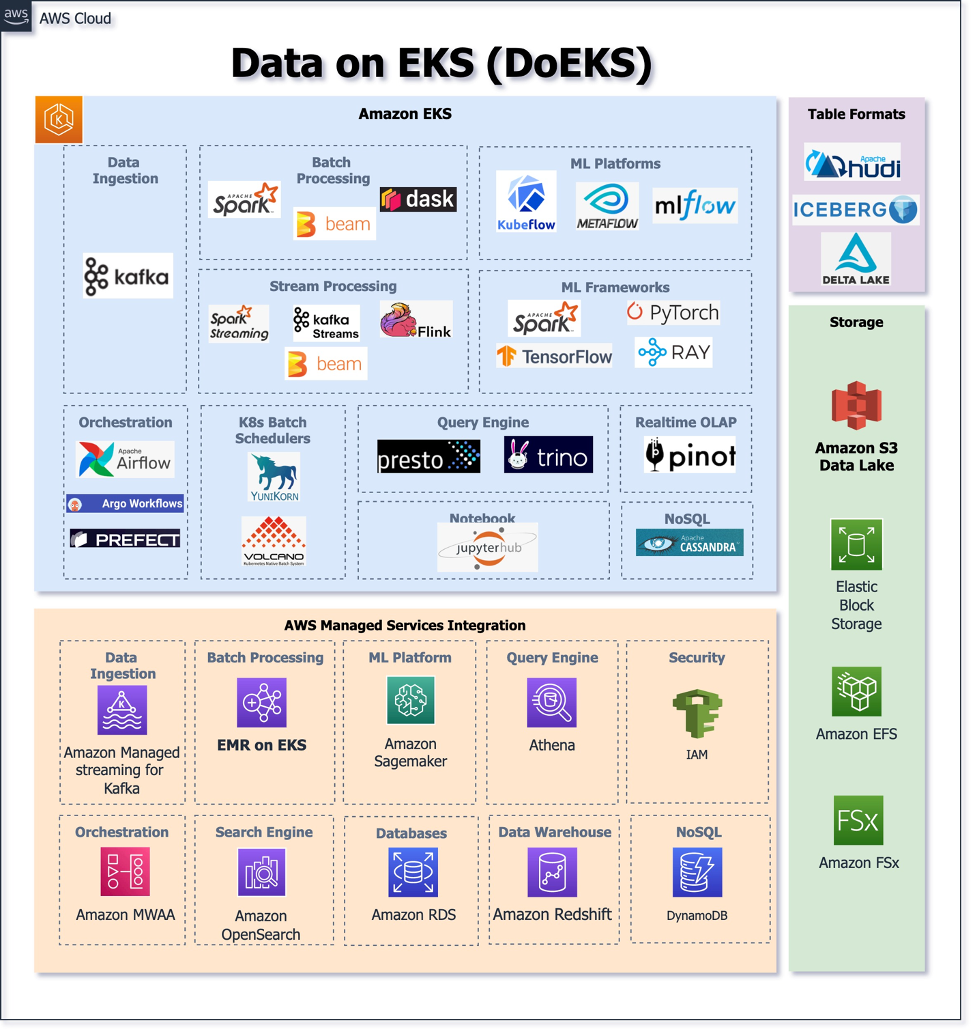
Walkthrough
Using DoEKS Blueprints
Data on EKS offers several blueprints for running Spark workloads on Amazon EKS, including using the open-source Spark Operator and managed EMR on EKS. The following example walks through a simple deployment of EMR on EKS with Karpenter Autoscaler and Apache YuniKorn batch scheduler.
Customers running Spark on Kubernetes can experience challenges achieving their scalability and performance goals by using standard components such as Kubernetes Scheduler and Cluster Autoscaler (CA). A few challenges are detailed as follows:
- The standard scheduler has no idea how many executors the driver needs until after the driver has started. This can lead to resource contention when submitting multiple jobs, since drivers can request more executors then can be fulfilled causing stalled jobs and performance degradation.
- Lack of ordering is also a concern, since it’s possible for smaller Spark applications to skip ahead of larger ones increasing the rate of failure for the larger and more expensive submissions.
- When a large number of pods are being co-scheduled, CA can be slow to react to pending pods before triggering the scale-up operation causing significant time delays.
- Scaling down a cluster is time consuming especially when operating hundreds of nodes, since CA terminates nodes one at a time.
To address these challenges, we take a blended approach by combining managed and open-source components to produce a highly scalable and efficient processing solution all packaged into a single DoEKS blueprint. By using EMR on EKS, customers can run Spark workloads faster with higher utilization, leading to lower running costs. It provides the benefits of Amazon EMR runtime for Apache Spark, including easy setup and management of Spark clusters, combined with the scalability and versatility of the Kubernetes platform. With Karpenter, Spark clusters can scale quickly and dynamically to meet the demands of your workloads while ensuring that resources are always available and utilized efficiently. Karpenter also features improvements to workload consolidation, de-provisioning, and node termination further improving efficiency and cost savings. Apache YuniKorn batch scheduler is purpose-built for running Big Data and ML workloads on Kubernetes with features like gang scheduling, job ordering, and hierarchy queues built-in for optimized Spark performance. Together, these tools provide a powerful combination for running highly efficient and scalable Spark workloads on Amazon EKS.
Deploying the solution
In this example, you’ll provision all the resources required to run Spark Jobs using EMR on EKS with Karpenter as Autoscaler, Apache YuniKorn as the batch scheduler as well as monitor job metrics using Amazon Managed Prometheus and Amazon Managed Grafana.
Prerequisites
Ensure that you have installed the following tools on your machine:
Deploy
To deploy all resources, clone the repository and run the following commands. The complete list of resources created by the blueprint can be found here. This deployment may take up to 20 minutes for Terraform to create the Amazon EKS Cluster and provision all resources.
Verify the resources
Verify the Amazon EKS Cluster and Amazon Managed Service for Prometheus.
Verify EMR on EKS namespaces emr-data-team-a and emr-data-team-b and Pod status for Prometheus, FluentBit, Karpenter, YuniKorn, etc.
Execute the sample PySpark job
This example uses the Karpenter provisioner for memory optimized instances. This template leverages the Karpenter AWS Node template with Userdata. Three input parameters are needed, including EMR_VIRTUAL_CLUSTER_NAME and EMR_JOB_EXECUTION_ROLE_ARN, which can be obtained from the Terraform apply output values. For the S3_BUCKET parameter, you can either create a new Amazon Simple Storage Service (Amazon S3) bucket or utilize an existing one to store the necessary scripts, input, and output data to run this sample job.
The Karpenter Autoscaler may take between 1-2 minutes to spin up a new memory optimized r5d node, as outlined in the provisioner templates, prior to executing Spark Jobs. Once the job is finished, the nodes will be drained.
Verify the job execution
This command displays the running Spark driver and executor pods, as well as the EMR on EKS job pod triggered by the EMR on EKS API.
Cleanup
To clean up your environment, destroy the Terraform modules in reverse order with -target option to avoid destroy failures.
Conclusion
In this post, we showed you how Data on EKS provides a comprehensive range of resources to run data workloads on Amazon EKS that are optimized for enhanced agility, scalability, and performance.
Getting involved
Data on EKS is developed and maintained by a collective group of Amazonians with a passion for Kubernetes and data-centric applications. Feature development is public and open for comment today, and the patterns we develop are driven by the feedback of our customers and the open-source community. We look forward to hearing about your experience and encourage everyone to use the issues section of the Github repository to post feedback, submit feature requests, or report bugs.
The Data on EKS community is open to everyone. If you are passionate about building next-generation data solutions on Kubernetes, then we invite you to join this initiative. Please check out the Contributing Guidelines for more information.
Next steps
To get started with Data on EKS, please visit the Data on EKS Website or Data on EKS Github repository. There you will find best practice documentation, samples, and instructions on getting started.