AWS Database Blog
Tag: DMS

Migrating your SQL Server database to Amazon RDS for SQL Server using AWS DMS
This post provides a solution for migrating your on-premises SQL Server database to Amazon RDS for SQL Server using the SQL Server backup and restore method in conjunction with AWS Database Migration Service (AWS DMS) to minimize downtime. This method is useful when you have to migrate the database code objects, including views, stored procedures, and functions, as part of the database migration.

Rolling back from a migration with AWS DMS
When migrating a database to a new system using AWS Database Migration Service (DMS), it is prudent to have a fallback strategy if the new system doesn’t work as expected. At a high level, there are four basic strategies for rolling back from a migration: basic fallback, fall forward, dual write, and bidirectional replication. Depending […]

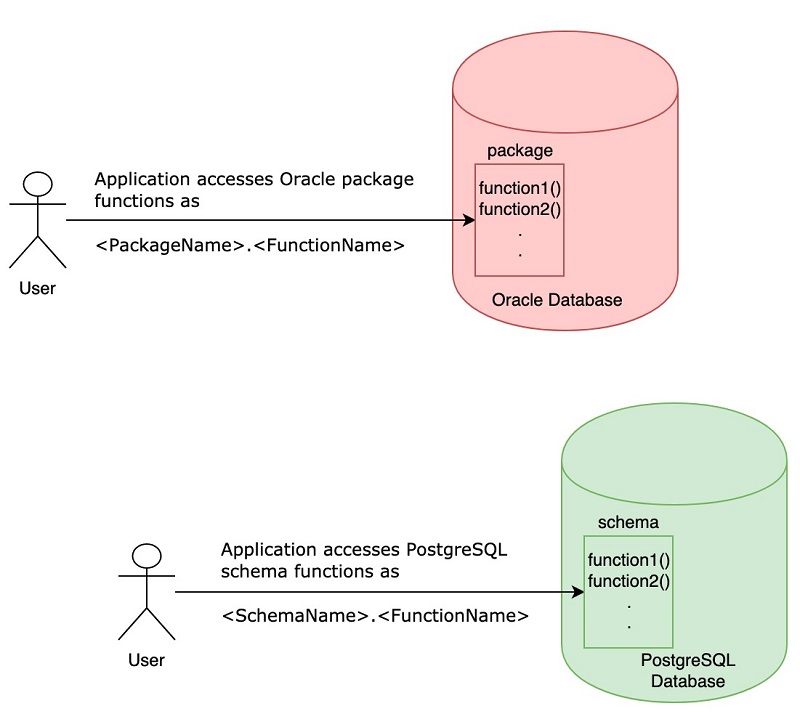
Migration tips for developers converting Oracle and SQL Server code to PostgreSQL
PostgreSQL is one of the most popular open-source relational database systems. It is considered to be one of the top database choices when customers migrate from commercial databases such as Oracle and Microsoft SQL Server. AWS provides two managed PostgreSQL options: Amazon RDS and Amazon Aurora. In addition to providing managed PostgreSQL services, AWS also […]

Disaster recovery on Amazon RDS for Oracle using AWS DMS
AWS Database Migration Service (AWS DMS) helps you migrate data from databases on-premises to Amazon Relational Database Service (RDS). You can also use it to migrate data between heterogeneous or homogeneous database engines, among other things. Businesses of all sizes use AWS to enable faster disaster recovery (DR) of their critical IT systems without having […]

Automating table mappings creation in AWS DMS
AWS Database Migration Service (AWS DMS) helps you migrate on-premises databases to AWS quickly and securely. It supports homogeneous migrations as well as heterogeneous migrations. The source database remains operational while the migration is running or being tested. Migration takes place using a DMS replication server, source, target endpoints, and migration tasks. If you are […]
Validating database objects after migration using AWS SCT and AWS DMS
Database migration can be a complicated task. It presents all the challenges of changing your software platform, understanding source data complexity, data loss checks, thoroughly testing existing functionality, comparing application performance, and validating your data. AWS provides several tools and services that provide a pre-migration checklist and migration assessments. You can use the AWS Schema […]
Automate AWS CloudFormation template creation for AWS DMS tasks
Expanding on the earlier post, Create AWS CloudFormation templates for AWS DMS tasks using Microsoft Excel, this post highlights an enhanced feature of the same tool that can speed database migration. To demonstrate this feature, we present a small command line tool written in Python. The tool takes a CSV file containing the names of […]

Announcing the support of Parquet data format in AWS DMS 3.1.3
Today AWS DMS announces support for migrating data to Amazon S3 from any AWS-supported source in Apache Parquet data format. This is one of the many new features in DMS 3.1.3. Many of you use the “S3 as a target” support in DMS to build data lakes. Then, you use this data with other AWS […]

Transform data with AWS DMS version 3.1.3
AWS now supports new data transformation capabilities in the latest AWS Database Migration Service (AWS DMS) version 3.1.3. You can change schema, table, and column names; specify individual tablespace names for Oracle targets; and update a table’s primary and unique key on any target. DMS version 3.1.3 supports the following new data transformation capabilities: Explicit table […]

Python code to download DMS Task Logs using the AWS DMS Task ID
With AWS Database Migration Service (AWS DMS), you can migrate databases to AWS quickly and securely. In this post, we walk through the sample Python code required to download AWS DMS task logs on to your local computer using the AWS DMS task ID. Overview The DMS task logs contain task information logged during the […]