AWS Database Blog
Load and unload data without permanently increasing storage space using Amazon RDS for Oracle read replicas
Generally, DBAs use Oracle Data Pump to move data around for activities like migrating existing data from Oracle on-premises to Amazon Relational Database Service (Amazon RDS) for Oracle or refreshing Oracle on-premises by exporting data from Amazon RDS for Oracle. As of this writing, after you create an RDS DB instance, you can’t decrease the total storage space by modifying the allocated storage size of the DB instance. If the size of the storage space to stage Data Pump files is considerately large, even after deleting the Data Pump files, considerable cost is still incurred.
This post introduces a solution to use RDS for Oracle read replicas to load and unload data without permanently increasing storage space. With this workaround, when you need to use Oracle Data Pump to move data, you can avoid the cost of storage space used for staging Oracle Data Pump files. Keep in mind that this solution only works for Amazon RDS for Oracle with Enterprise Edition and Bring Your Own License (BYOL).
Two major use cases can benefit from this solution:
- Importing data to an RDS for Oracle DB instance
- Exporting data from an RDS for Oracle DB instance to a DB instance on Amazon Elastic Compute Cloud (Amazon EC2) or on premises
Solution overview
Let’s look at the architecture and high-level solution for each of the use cases via an RDS for Oracle read replica. This solution takes advantage of the fact that replicas are initially created the same size as their source instance, but subsequent modifications to storage size are independent. Therefore, you can increase the size of the primary instance without increasing the size of the replica. The replica should always be sized to accommodate the database itself—as well as archived redo logs that may queue up during peak loads—but storage space for external files like Oracle Data Pump files only needs to be allocated on the primary. With this solution, you can create a replica based on the current size of the primary instance, allocate additional storage to the primary DB instance only, load or unload data using the additional storage space, promote the replica, and delete the original resized source instance.
This solution works for both read replicas and mounted replicas. The only difference is that you can’t perform the data validation before promoting a mounted replica to a standalone database.
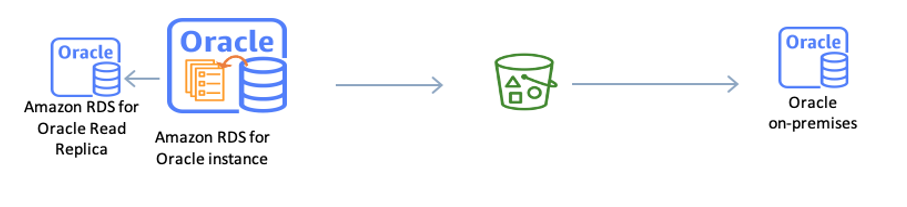
Use case 1: Import data to an RDS for Oracle DB instance
Before uploading Data Pump files from the source database into an S3 bucket, launch an RDS for Oracle DB instance and a read replica by allocating the same and appropriate size of storage space based on how much data you will load.

Allocate the appropriate storage space to stage the Data Pump files and upload the Data Pump files to the RDS for Oracle primary instance by using the S3_integration option.

Import the Data Pump files and conduct data validation on the RDS for Oracle read replica.

Stop the application in the maintenance window and make sure there is no replication lag. Promote the read replica to new standalone database, decommission old primary DB instance, rename this new standalone DB instance to old primary DB instance, and cut over the application to this new standalone database.

Use case 2: Export data from an RDS for Oracle DB instance to an EC2 or on-premises instance
Before you export data, launch a read replica with the same storage space for the source RDS for Oracle DB instance.
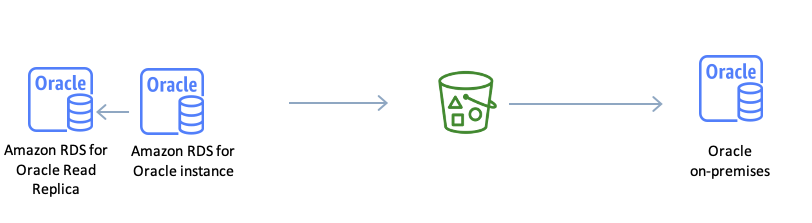
Allocate the appropriate storage space to stage the Data Pump files and export data by using Oracle Data Pump.
Upload the Data Pump files to an S3 bucket by using the s3_integration option.

Stop the application in the maintenance window and make sure there is no replication lag. Promote the read replica to new standalone database, decommission the old primary DB instance, rename this new standalone DB instance to the old primary DB instance, and cut over the application to this new standalone database.

Import data to an RDS for Oracle DB instance
In this section, we walk through the first use case: importing data to an RDS for Oracle DB instance.
We provide an AWS CloudFormation template to help you create the AWS resources you need to set up the demo environment, which creates a primary RDS for Oracle instance, read replica, S3 bucket, and AWS Identity and Access Management (IAM) role with an attached policy that allows your RDS for Oracle DB instance to access the S3 bucket.
- Launch the CloudFormation template to create your required resources.
- Download the provided Oracle Data Pump file from the public S3 bucket.
- Verify that a read replica was created for the RDS for Oracle instance.
- Associate the IAM role created by CloudFormation to your primary RDS for Oracle instance.
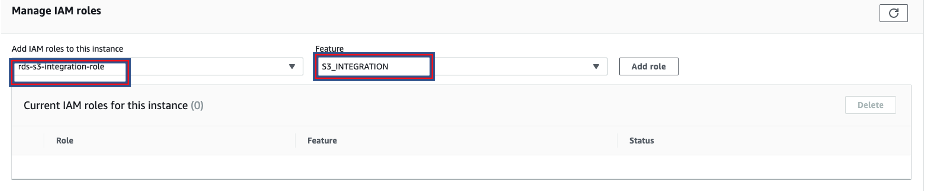
- Allocate an extra 20 GB of space on the primary RDS for Oracle instance.
For demo purposes, we allocate an extra 20 GB of storage space to stage the Oracle Dump files on the primary RDS for Oracle instance only. In a real-world environment, make sure you have enough space allocated for data files and archive log files on both the primary database instance and replica instance, and allocate appropriate storage space for staging external files like Oracle Data Pump files.

Run the following statements using an Oracle client tool like SQL*Plus, SQL Developer, or SQL Workbench/J.
- Upload the Data Pump file (
hr.dmp) to the S3 bucket created by the CloudFormation template with the following SQL statements:
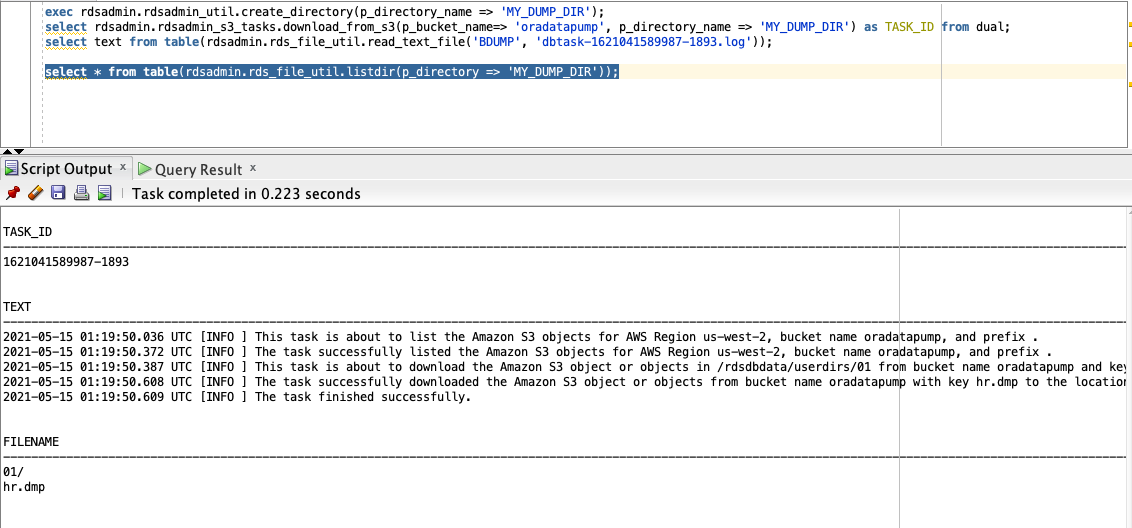
- Import data to the primary RDS for Oracle instance:

- Validate by running sanity tests on both the primary RDS for Oracle instance and read replica.
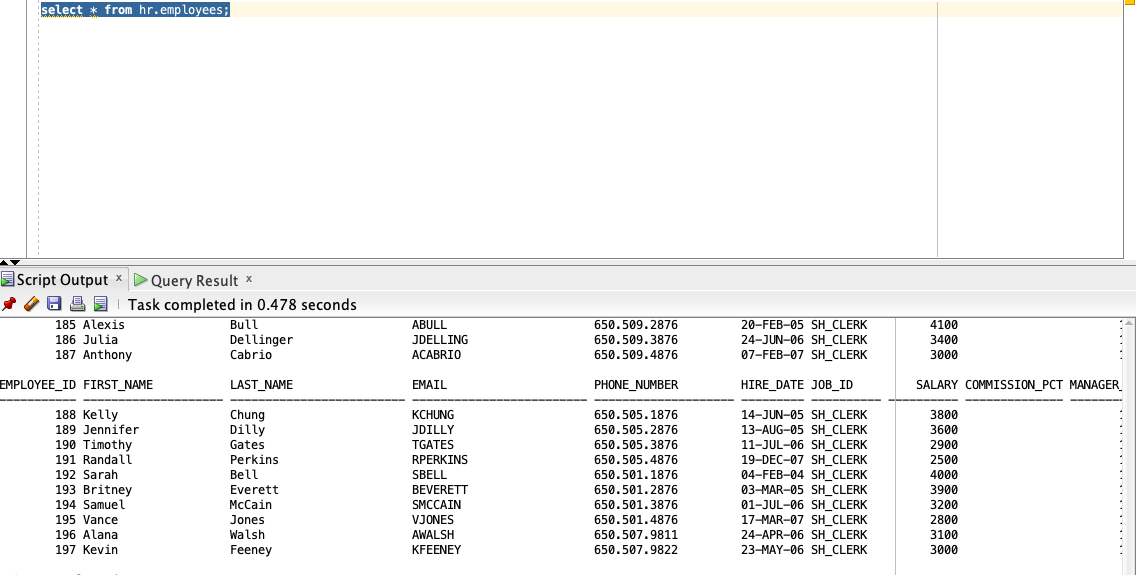
- Plan your application cutover window and check that there is no replica lag by checking the following views:
- V$DATAGUARD_STATS – Shows a detailed breakdown of the components that make up the replica lag
- V$DATAGUARD_STATUS – Provides the status information from Oracle’s internal replication processes
- V$ARCHIVED_LOG – Shows which commits have been applied to the read replica
You can also check replica lag on the Amazon RDS console.
- Promote the read replica to a standalone database.

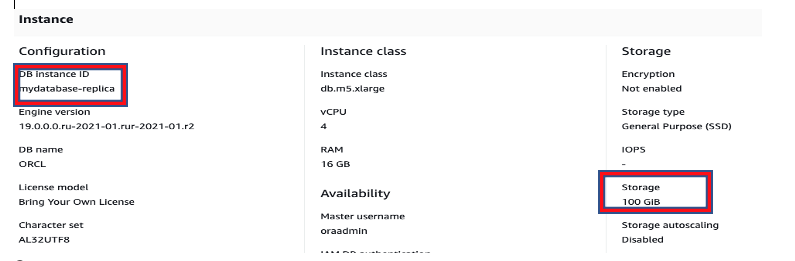
The following screenshots compare the storage space between the primary RDS for Oracle database and the new standalone database.

Considerations
Keep in mind the following when evaluating the solution for your use cases:
- Before data loading, make sure you have enough storage space for your data files and archive log files for both the primary database instance and replica database instance for accommodating data load. Make sure the primary database instance has enough space for staging external files.
- If you have an existing replica within the same Region as the primary database instance for read offload purposes, you can promote the existing replica after data loading is complete, then recreate a read replica for the newly promoted standalone database.
- If you have an existing cross-Region replica, you need to recreate the cross-Region replica for the newly promoted standalone database after data loading and replica promotion is complete, then decommission the previous primary and cross-Region replica.
- You should always make a checklist to walk through when you test out the solution and measure the performance impact.
- If you need to load a large amount of data, we recommend choosing a time window with the smallest workload to minimize performance overhead and reduce the chance that the primary database and replica are significantly out of sync.
Summary
In this post, we introduced a solution to load and unload data without permanently increasing storage space using RDS for Oracle read replicas to avoid unnecessary storage cost. We walked through a use case of importing data to an RDS for Oracle DB instance. You can follow a similar procedure for the second use case we mentioned: exporting data from an RDS for Oracle instance to an EC2 or on-premises instance. Please try out the solution for your real-world use cases, and leave your feedbacks, thoughts and ideas in the comments.
About the Authors
 Kathleen Li, Data & Analytics Specialist SA
Kathleen Li, Data & Analytics Specialist SA
 Vejey Gandier, Product Manager – Technical
Vejey Gandier, Product Manager – Technical
 Amit Grover (AWS – RDS), Senior Database Engineer
Amit Grover (AWS – RDS), Senior Database Engineer