AWS Database Blog
Model-driven graphs using OWL in Amazon Neptune
Amazon Neptune is a graph database service provided by AWS that you can use to build a knowledge graph of relationships among business objects. When building a knowledge graph, what is a suitable model to govern the representation of those relationships? We would prefer not to build our graph on the fly, but rather have a model to guide us. In this post, we use Web Ontology Language (OWL) as the language for that model. We show, using the example of a modern organization, how to build and validate the organizational graph of a fictional company from an organizational model described in OWL. We take a top-down, model-driven approach: from the model, we validate instances and create a template for populating new instances.
OWL is a good fit to use in Neptune because it is part of the same semantic layer cake as Resource Description Framework (RDF) and SPARQL Protocol and RDF Query Language (SPARQL). The layer cake, shown in the following figure, is a well-known visualization of linked-data standards from the Worldwide Web Consortium (W3C). RDF (as a graph data representation) and SPARQL (as a query language) are first-class concepts in Neptune. OWL sits above RDF in the figure, indicating that we can use it with graph databases that support the RDF data model. Between OWL and RDF in the figure is RDF Schema (RDFS), a basic language to define classes and properties for our RDF graph. OWL, as an ontology language, can do what RDFS does and more.
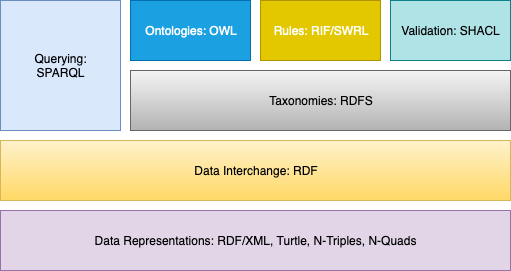
An ontology is like a data model, but subtly different. The Unified Modeling Language (UML) when used for data modeling is a rigid listing of classes and properties (or attributes) that fall under each class. UML is often used to model schemas for a relational database; the model is rigid, but then so is the relational table it’s modeling. An ontology is not a listing but rather a set of logical constraints describing how the graph can be arranged. This allows us to define classes using arbitrarily complex logical expressions and infer new relationships that follow from what we already know, even if they haven’t been explicitly stated. OWL is designed to be used by automated reasoner tools to draw such inferences. Ontology is ideal for modeling graphs, because in a graph we need flexibility in how we define relationships and benefit from inferred relationships when traversing a path.
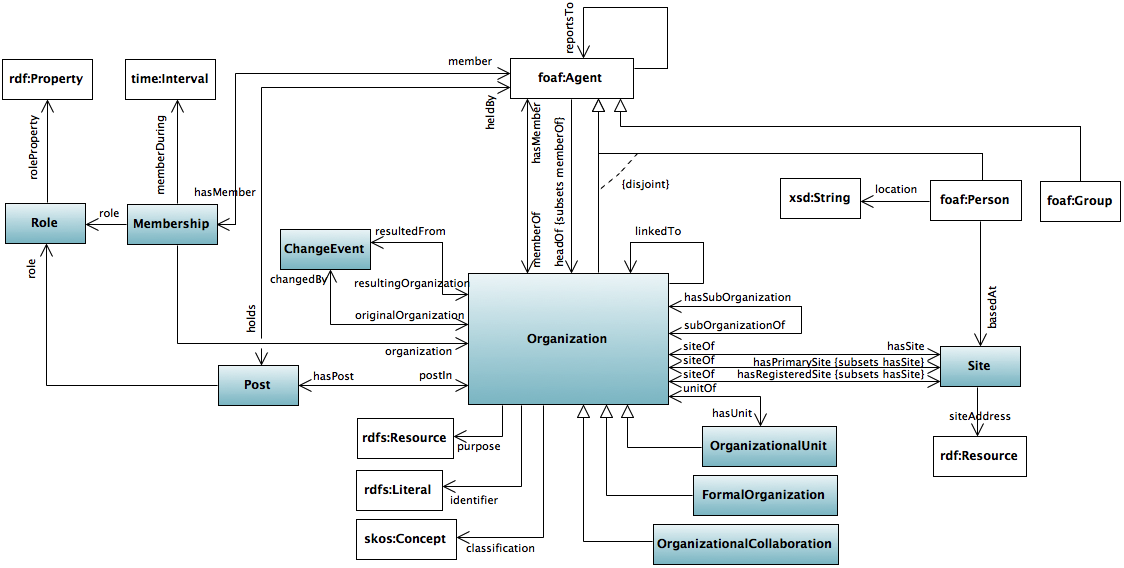
Our example ontology is the W3C organizational ontology. As the next figure [1] shows, an organization has sub-organizations and organizational units, participates in organizational collaborations, is located at sites, is subject to change events, and has members, posts, and roles. Members, additionally, report to other members. The ontology describes the generic structure of these relationships in the OWL language. Over the course of this post, we study snippets of that representation in depth.
First, we load into a Neptune database the organizational ontology as well as an example instance of it: the organizational graph of a fictional company, the Mega Group. OWL ontologies are represented in RDF, and therefore can be loaded as is. That is important because we introspect the ontology by querying it with SPARQL, deriving its classes and their likely properties in an opinionated fashion—opinionated because although OWL has broad logical expressive power, we draw the line and look for the most common patterns. After we derive this opinionated model, we programmatically compare the ontology with our Mega Group instances, logging any gaps. We also stamp out a template for creating new instances by generating a boilerplate RDF model that instantiates the classes and applies properties to the instances.
The code accompanying this post is available as an open-source repository on GitHub.
Overview of solution
We implement the solution through the following steps:
- Set up AWS resources, including Neptune and a Neptune Workbench notebook.
- Load into the Neptune database the ontologies (the organizational ontology plus an additional edge case ontology) plus sample data.
- Explore the ontologies and sample data using SPARQL.
- From the ontologies, build a model from which we can validate existing instance data and generate new instance data.
- Use the model to generate new instances represented in Turtle, a standard RDF serialization format supported by Neptune.
- Use the model to validate our existing sample instances.
- Clean up AWS resources.
Let’s now step through the solution, provisioning in your AWS account a test environment and then following along with a notebook to load, introspect, and use the ontology.
Prerequisites
To run this example, you need an AWS account with permission to create resources such as a Neptune cluster.
Provision resources
To follow along with this post in your AWS account, you need a Neptune database, the Neptune notebook featuring our ontology model exploration, and other resources. Refer to the section Setup instructions to setup these resources. When you complete the setup, open the Neptune notebook in your browser. In the remaining steps, you use the notebook.
Load ontologies and RDF sample data
Next, we load our source data into the Neptune database. The source data resides in an S3 bucket that you create as part of the provisioning of resources. The bucket contains three RDF objects in Turtle representation:
- org.ttl – The W3C organizational ontology. During the provisioning of resources, it is downloaded from the W3C website to the bucket. For more information, refer to the W3C documentation.
- example_org.ttl – An example organization and its members.
- tester_ontology.ttl – An ontology, plus example instances, that cover common OWL modeling patterns.
To load these into the Neptune database, complete the following steps:
- Navigate in the notebook to the heading Loading the Ontology and Examples into Neptune.
The section contains three load magics to run. Each resides in its own cell and begins with the text %load. For example, the magic to load the organizational ontology resembles the following:
Here neptuneforblog-s3workingbucket-1mk8x5dqln2j5 refers to the S3 bucket created in our environment. Yours will be different, but it should exactly match the name of the bucket that you created when provisioning your resources. If it doesn’t match, manually edit it.
- Run the first cell.
You’re presented with a form confirming the load details. The values in the form fields are prepopulated and don’t need to be edited.
- Choose Submit.
- Repeat for the other two magics:
- After you run each, confirm you see the message
Load Completedin the cell’s output.
Query ontologies and sample data
You now have ontologies and sample data loaded into your Neptune database. We query that data to understand its structure.
- In the notebook, navigate to the heading Querying Org Ontology.
The first query uses the %%sparql magic to get a list of OWL classes (that is, subjects whose rdf:type is owl:Class). For each class, it also finds equivalent classes (owl:equivalentClass), classes of which this class is a subclass (rdfs:subClassOf), and keys (owl:hasKey in a list with rdf:first and rdf:rest). See the following code:
- Run the cell containing the first query.
The results are shown in tabular form. The following screenshot shows an excerpt.

The classes returned by the query fall into three categories:
- Organization classes, which bear the prefix
http://www.w3.org/ns/org#. These includeChangeEvent,FormalOrganization,Membership,Organization,OrganizationalCollaboration,OrganizationalUnit,Post,Role, andSite. - Example classes, which bear the prefix
http://amazonaws.com/db/neptune/examples/ontology/tester#. Among these areFather,Mother, andGrandpa. We use these to test our model later in this post. - Blank nodes, which begin with a
b. We need to dig deeper to understand the purpose of these classes. When we build our model in the next section, these classes will fall into place.
The next query finds properties of classes. More precisely, it finds classes such that the class is the domain (rdfs:domain) of a property:
- Run this query.
Among the results, observe that properties for Organization include org:hasSite, org:hasSubOrganization, and org:hasMember. FormalOrganization has properties org:hasRegisteredSite and org:hasUnit.

- Continue to the heading Querying Example Data, where you can discover a fictional organization called the Mega Group.
This section contains six queries. Notice that they assume the structure of the organizational ontology to find the data.
For example, the first query finds organizations by searching for subjects whose rdf:type is org:Organization. For each organization, it find sub-organizations, units, and sites by checking properties org:hasSubOrganization, org:hasUnit, and org:hasSite, respectively. The query is guided by our understanding of the ontology: we saw that org:Organization is a class and that properties org:hasSubOrganization, org:hasUnit, and org:hasSite have org:Organization as their domain. (This turns out to be not quite correct! In a later section, we validate this and see where we erred.)
- Run this query.
You can observe that the Mega Group has two sub-organizations: MegaSystems and MegaFinancial. MegaSystems has two units: Sales and R&D.

Another query examines the reporting structure in MegaFinancial using org:memberOf and org:reportsTo relationships:
- Run this query.
Among the results, observe that Bonnibelle Valenta has boss Andromache Laborda and her full top-down line of superiors is Ilyssa Sylett, Andromache Laborda.

Build a model
Next, we query the ontologies to produce an opinionated model of classes and their properties. The goal of the model is twofold:
- Validate instances – Check if the instance has the properties expected by the ontology. Check that it honors the constraints (range, multiplicity, restriction) of the property.
- Generate instances – Generate RDF in Turtle form that creates instances of classes and uses properties to draw relationships to other instances.
We explore validation and generation in subsequent steps. In this step, build the model by running the Python code under the heading Build the Model. The main function is build_model, which runs SPARQL queries to gather sufficient detail about classes, properties, and restrictions, and then combines the query results into a listing of classes and associated properties.
Logically, the algorithm works as follows. (Try comparing this with the code implemented in the notebook, which runs queries using Neptune magics and interprets results with ordinary Python. Another useful Python library for RDF processing, not used here, is RDFLib.)
- Using SPARQL, it gathers all classes (
owl:Class) using predicates such asrdfs:subClassOf,owl:equivalentClass,owl:hasKey, andowl:intersectionOf. - Using SPARQL, it gathers all properties (
owl:ObjectProperty,owl:DatatypeProperty, orrdf:Property) using predicates such asrdfs:subPropertyOf,rdfs:domain, andrdfs:range. - Using SPARQL, it gathers all restrictions (
owl:Restriction) using predicates such asowl:onProperty,owl:hasValue,owl;allValuesFrom, andowl:someValuesFrom. - Then it walks each class looking for properties. For each class C:
- If there is a property P whose domain is C, or whose domain is a union of classes that includes C, consider P a property of C.
- If P is a sub-property of another property P1, consider P1 a property of C. (As we demonstrate in this section, having an organizational unit is a sub-property of having a sub-organization. Therefore, a class with the former property must have the latter property too.)
- If C is a subclass of class C1, consider C to have all of C1’s properties too. This applies to all ancestors too. If C is subclass of C1 which is subclass of C2, consider C to have properties of C1 and C2.
- If C is the intersection of classes C1, C2, C3, …, consider C to have properties of C1, C2, C3, …. (Intuitively, if
Motheris the intersection ofPersonandParent, a mother can have properties of bothPersonandParent, as we discuss in the next table. This rule doesn’t hold for union. IfPersonis a union ofManandWoman, a person does not have properties of bothManandWoman.) - If C is equivalent to, or is a subclass of, a restriction on property P, consider C to have property P.
Run the code cell. The output is a printed summary of the model. The following is an excerpt:
Our model is opinionated. We associate properties with classes based on the ontology’s use of conventional modeling patterns. Our algorithm looks for those! OWL is expressive, and there are countless ways to define classes and properties in OWL ontology that our algorithm doesn’t look for. Nonetheless, the algorithm is just code, and it’s eminently changeable. To adjust it is as simple as modifying code in the notebook cell. (Additionally, as mentioned previously, the full source code accompanying this post is available as an open-source GitHub repo.)
Let’s discuss each of these patterns. In the following sections, we name each pattern, give an example of its use in the organizational or test ontology, and show how an instance uses the pattern. The instance examples might strike you as having a peculiarly generated quality. They’re generated by our model! We consider generation in the next section.
The Mother example is from OWL Primer. RedWine, RedThing, and RealArtist examples are from OWL Restrictions.
Pattern: Key
Ontology example:
Instance example:
Pattern: Subclass
Ontology example:
Instance example:
Notice the FormalOrganization instance has property org:hasSite, whose domain is Organization. But FormalOrganization is a subclass of Organization. This leads to a finding during validation, as you see in a later section.
Pattern: Object property whose domain is class
Ontology example:
Instance example:
Pattern: Data type property whose domain is class
Ontology example:
Instance example:
Pattern: Generic property whose domain is class
Ontology example:
Instance example:
Pattern: Property whose domain is a union
Ontology example:
Instance example:
Notice the Post instance has org:reportsTo property. Post is in domain union of org:reportsTo.
Pattern: Sub-property
Ontology example:
Instance example:
Pattern: Functional property
Ontology example:
Instance example:
Pattern: Class as intersection of classes
Ontology example:
Instance example:
Notice how Mother gets properties of both intersecting classes: womanliness from Woman, thatParentQuality from Parent.
Pattern: Subclass restriction (also restriction on value)
Ontology example:
Instance example:
Pattern: Equivalent restriction
Ontology example:
Instance example:
Pattern: Restriction (some values of)
Ontology example:
Instance example:
Pattern: Restriction (all values of)
Ontology example:
Instance example:
Generate instances from the model
In the notebook, navigate to the heading Generation. The code cell contains Python code that outputs RDF in Turtle notation featuring generated instances of the classes from the ontology. The code is straightforward; it iterates each class, instantiating it and giving values for each property.
Run it. The following is an excerpt of the output:
In the preceding section, we discussed the ontology patterns our opinionated model uses. In that discussion, we gave examples of what instance code looks like when following the pattern. Those examples are drawn from the generated instances you just ran! Compare the output you see in this step with those examples.
Validate the model
For the last step, navigate to the heading Validation in the notebook. The validate_instances function runs a SPARQL query to pull the instances. It then compares the instances to the model, applies several validation rules to it, and reports its findings. Run the cell containing that code.
To understand the output, take a closer look at the main rules, their findings, and examples of violations. We report the rule violations as findings rather than errors. A finding is not necessarily a problem. We just want to highlight cases in which instances differ from classes in case there is a mistake in the instances.
Rule: Missing key
In the ontology, the class has a key. But the instance does not contain the key, or the instance has multiple values for the key.
Finding:
Example:
Nowhere do we actually provide org:identifier for ex:Org-MegaSystems.
Rule: Unrecognized property
The instance has a property not in the model.
Finding:
Example:
As we discussed previously, hasUnit is a property of FormalOrganization, not Organization. That is the reason for the finding.
Rule: Literal/object mismatch on property
In the instance, the property’s value is literal, but in the ontology, the property is an object property. Or the opposite: the value in the instance is an object, but in the ontology, the property is a data type property.
Finding:
Example:
Rule: Unexpected type of property
The instance property’s value of type S, but S isn’t in the range of the property’s definition in the ontology.
Finding:
Example:
Our validation rules considers range a constraint on the value of org:siteOf. That is fine for an opinionated validation model. Actually, range is not restrictive, but generative. If an instance has a property, a reasoner can infer the type of that property has the specified range.
Rule: Multiple values of functional property
The instance gives multiple values for a property, but in the ontology the property is functional.
Finding:
Example:
Rule: Unexpected value on restriction
The instance has a restricted property, but the value of that property doesn’t match the value given in the restriction’s hasValue in the ontology.
Finding:
Example:
Rule: Restriction value counters owl:allValuesFrom
The instance has a restricted property whose value is of type S. In the ontology, the restricted property specifies owl:allValuesFrom = T.
Finding:
Example:
Rule: Missing value on restriction with owl:someValuesFrom
In the ontology, the class has a restriction that a property has the owl:someValuesFrom class. The instance doesn’t have any values for this.
Finding:
Example:
The issue is that at least one tst:creatorOf needs to be tst:ArtObject. But for the instance tst:TheSoonToBeArtist, all of tst:creatorOf are tst:WastefulActivity.
Analysis of findings
In the examples shown, it’s likely a data issue that ex:Person-ImposterOf-Michel-Urban is a member of the tech president role. The finding helps spot the issue; we need to fix our data. However, there might be no issue relating ex:AnnualFiddleWeek to a site. True, the ontology expects the range of org:siteOf to be an organization, and our instance data gives ex:SmallTownEvent as the type of ex:AnnualFiddleWeek. But it might be that ex:AnnualFiddleWeek actually is an organization too, and we just forgot to state that in the instances. For OWL, the open-world assumption holds: just because we didn’t state it doesn’t mean it’s false. Indeed, you could infer that it’s an organization.
Setup instructions
We share an AWS CloudFormation template to create these resources in your account. To provision these resources using CloudFormation, first download a copy of the CloudFormation template. Then complete the following steps:
- On the AWS CloudFormation console, choose Create stack.
- Choose With new resources (standard).
- Select Upload a template file.
- Choose Choose file to upload the local copy of the template that you downloaded. The name of the file is
neptune-ontology-main.yml. - Choose Next.
- Enter a stack name of your choosing.
- You may keep default values for Parameters. In particular, leave DBReplicaIdentifierSuffix blank if you want to create a single Neptune instance. Set this to a value if you want to add a replica instance.
- Choose Next.
- Continue through the remaining sections.
- Read and select the check boxes in the Capabilities section.
- Choose Create stack.
- When the stack creation is complete (approximately 15 minutes), on the Outputs tab for the stack, find the values for
NeptuneSageMakerNotebookand BulkLoadS3BucketName. - In the browser, navigate to the URL given by
NeptuneSageMakerNotebook.
You should now have a Jupyter notebook instance, as shown in the following screenshot.

- Choose Neptune_Ontology_Example.ipynb to open the notebook containing the code for this post.
The following figure shows the resources created in this CloudFormation stack.

The CloudFormation stack installs a Neptune primary instance and, optionally, a replica instance that acts as both a read replica and a failover target if the primary fails. These form a Neptune cluster, which exposes a DNS endpoint that applications use to access the cluster. In this post, that application is the Neptune_Ontology_Example notebook, which loads ontology and instance data into the Neptune instance, and then queries it, via the endpoint. The user, Organizational Graph SME, accesses that notebook through the browser to analyze the organizational ontology and graph. You play this role in this walkthrough.
The Neptune instance and the notebook reside in private subnets of a virtual private cloud (VPC), which we build using Amazon Virtual Private Cloud (Amazon VPC). The VPC spans two Availability Zones in your Region.
The stack also uses Amazon Simple Storage Service (Amazon S3) to create a bucket containing the ontologies and sample data. We use the notebook to load this data into the Neptune instance. The stack provisions a VPC endpoint to enable Neptune to connect to Amazon S3 over the AWS network to gather the data to be loaded.
Clean up
If you’re done experimenting with ontologies in Neptune and want to avoid incurring future charges, delete the Neptune database and notebook. To do this, navigate to the AWS CloudFormation console and delete the stack that you created previously. AWS CloudFormation removes Neptune and related resources.
Conclusion
Our purpose in this post was to use OWL ontology to derive a data model to validate and generate RDF data in Neptune. Because OWL is itself expressed as RDF, we were able to load a well-known organizational ontology into our Neptune database and query it using SPARQL to build validation and data generation logic. We compared the ontology to sample organizational data expressed in RDF. We used a notebook to walk through all the steps. Our model is opinionated in the sense that when it introspects the ontology to decide what makes a valid knowledge graph, it assumes, to keep things simple, conventional OWL modeling patterns. Opinions can change! If your patterns are different, we encourage you to modify the code in the notebook to enhance the derivation of the model.
Learn more about Amazon Neptune by visiting the website or feel free to ask questions in the comments.
References
[1] Image derived from https://www.w3.org/TR/vocab-org/. Copyright 2012-2014 W3C (MIT, ERCIM, Keio, Beihang), All Rights Reserved
About the Author
 Mike Havey is a Solutions Architect for AWS with over 25 years of experience building enterprise applications. Mike is the author of two books and numerous articles. Visit his Amazon author page to know more.
Mike Havey is a Solutions Architect for AWS with over 25 years of experience building enterprise applications. Mike is the author of two books and numerous articles. Visit his Amazon author page to know more.