AWS Database Blog

Replicate your data from Amazon Aurora MySQL to Amazon ElastiCache for Redis using AWS DMS
Caching enables the best user experience for real-time applications. You can build applications that provide sub-millisecond response times by storing the most frequently requested data in an in-memory cache like Redis. On August 30, 2021, we announced the support for migrating your data from supported sources to Redis, Amazon ElastiCache for Redis, and Amazon MemoryDB […]

How BlueFin helped build a scalable IoT data platform for Walchem using Amazon Timestream
Walchem is a leading manufacturer of online analytical instruments and electronic metering pumps. Their mission is to provide the integration of sensor, pump, and electronic technologies for chemical control. Walchem’s Fluent platform provides cloud-based telemetry and monitoring within water treatment facilities, enabling facility operators to gather insights into how the facility is operating and whether […]

Customize Amazon RDS events notification using Amazon EventBridge and AWS Lambda
Large customer database infrastructures are often deployed with Amazon Relational Database Service (Amazon RDS), which includes various engine types such as Oracle, SQL Server, MySQL, MariaDB, and PostgreSQL. Monitoring is an important part of maintaining the reliability, availability, and performance of Amazon RDS and your AWS solutions. To debug multi-point failures, we recommend that you collect monitoring data from all parts […]

Data preparation for machine learning using Amazon Timestream
Precognition, the ability to see events in the future, has always fascinated humankind. We probably will get there someday, but time series forecasting gets you close. The human brain is naturally trained to anticipate future events by analyzing the past, but the brain often makes only linear predictions because it can’t analyze the amount of […]

Configure an AWS SCT multi-server project
The AWS Schema Conversion Tool (AWS SCT) accelerates migration for commercial database and data warehouse schemas along with code objects to open-source engines or AWS-native services, such as Amazon Aurora and Amazon Redshift. For your database migration to the cloud, you can choose a rehost (lift and shift), replatform (lift and reshape), or refactor approach. […]

Develop a Full Stack Serverless NFT Application with Amazon Managed Blockchain – Part 1
The advent of blockchain technology, a decentralized ledger on which digital assets can be created and exchanged peer to peer, has shifted the conventional understanding of ownership. Often, these digital assets are referred to as tokens, which you can use as a medium of exchange like a currency, a representation of a physical or digital […]

Your guide to Amazon Managed Blockchain and Amazon QLDB breakouts, workshops, and chalk talks at AWS re:Invent 2021
AWS re:Invent 2021 is here! This post includes a complete list of Amazon Managed Blockchain and Amazon Quantum Ledger Database (Amazon QLDB) sessions taking place at re:Invent 2021. This year we have five total sessions on Managed Blockchain and Amazon QLDB, including one breakout, three chalk talks sessions, and one workshop. Make sure to sign […]

Auto scale your Amazon Neptune database to meet workload demands
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications with highly connected datasets. You can use Neptune to build fraud detection, entity resolution, product recommendation, and knowledge graph applications. Built on open standards, Neptune enables developers to use three popular open-source graph query languages […]
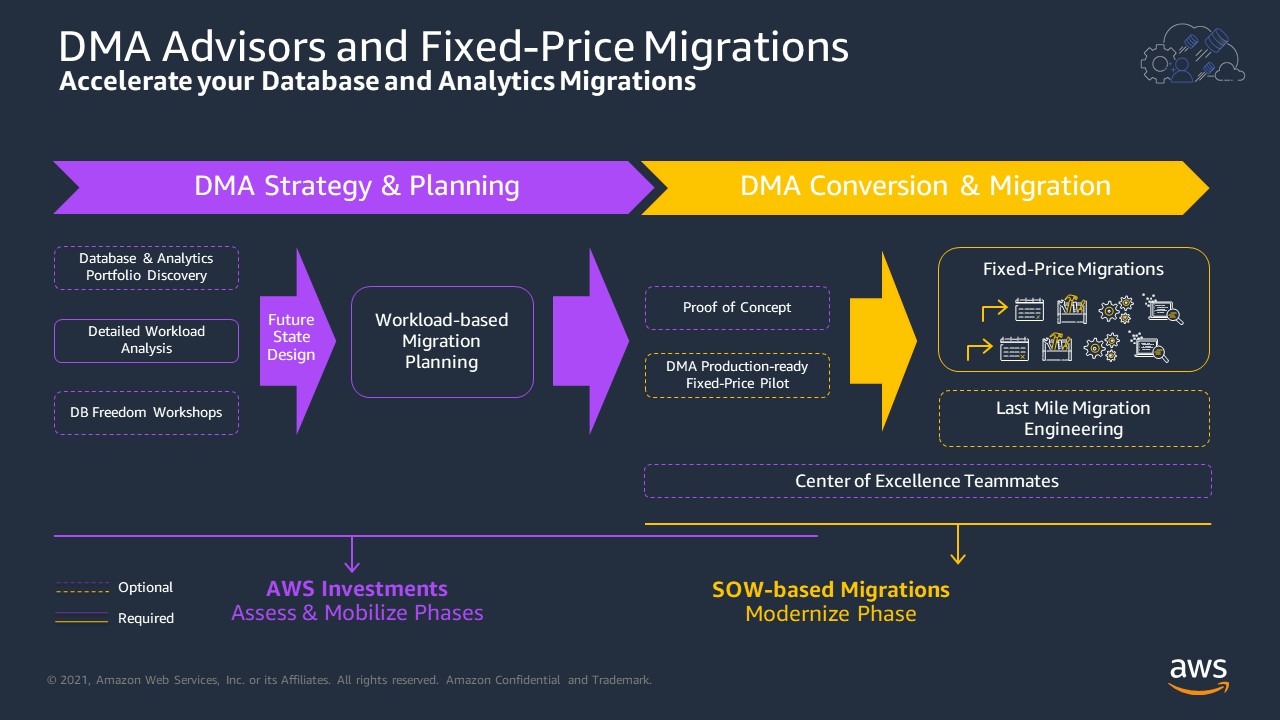
Fast-forward your database and analytics migrations with Amazon DMA
Amazon Database Migration Accelerator (Amazon DMA) helps you accelerate migrations to AWS Databases and Analytics services. Amazon DMA is comprised of migration domain experts including engineers, who can assist you with your migration strategy and planning to deploying your applications and databases to a production environment. Amazon DMA helps build a strong foundation for AWS Databases […]

Use the TempTable storage engine on Amazon RDS for MySQL and Amazon Aurora MySQL
August 2023: This post was reviewed and updated to reflect a new parameter change in MySQL Community 8.0.28 that impacts Amazon Aurora MySQL release. MySQL 8.0 has introduced TempTable as the new, default internal temporary table storage engine to speed up query processing. The MySQL query optimizer creates temporary tables internally to store intermediate datasets […]