.NET on AWS Blog
Building a Conversational Document Bot on Amazon Bedrock and Amazon Textract with .NET Windows Forms
Introduction
The growth in developing and launching Generative AI solutions is unprecedented. Most content available to help developers is in Python. While this may be the majority, many developers maintain and evolve long-lasting lines of business applications developed on .NET. Enterprises have invested a lot into these legacy applications, and it would be difficult for them to rebuild them from scratch to leverage Generative AI. This post covers the “How-to“ instructions for building a conversational document bot using .NET Windows Forms with Amazon Bedrock and Amazon Textract.
Amazon Bedrock is a fully managed service that provides a single API to call a broad range of Foundation Models (FM’s). The service includes models from Amazon and third-party models supporting a range of use cases. You can read about the FM’s available at Supported foundation models on Amazon Bedrock. Amazon Bedrock enables developers to create unique experiences with Generative AI capabilities supporting a broad range of programming languages and frameworks. Amazon Bedrock makes it easier to develop these solutions on .NET using the AWS SDK.
About the Conversational Document Bot
The conversational document bot allows users to upload a PDF or Microsoft Word document and ask questions about its content. Conversation history is persisted for the session: when the user asks follow up questions, the bot responds based on the context of the whole conversation. The app provides settings which control the behavior of document extraction and model responses. The number of tokens that you can pass to a model is based on its input token capacity. Tokens are a basic unit of text which a Large Language Model (LLM) processes and generates, 750 words ~=1000 tokens. There are multiple ways to handle the token limitation of the model and it is discussed later on.
You can find all the code used in this blog in this GitHub repo.

Figure 1: Document Bot app
Solution Overview
The solution implements answering questions from users about an uploaded document. The design uses the concept of question answering with context (Figure 2).
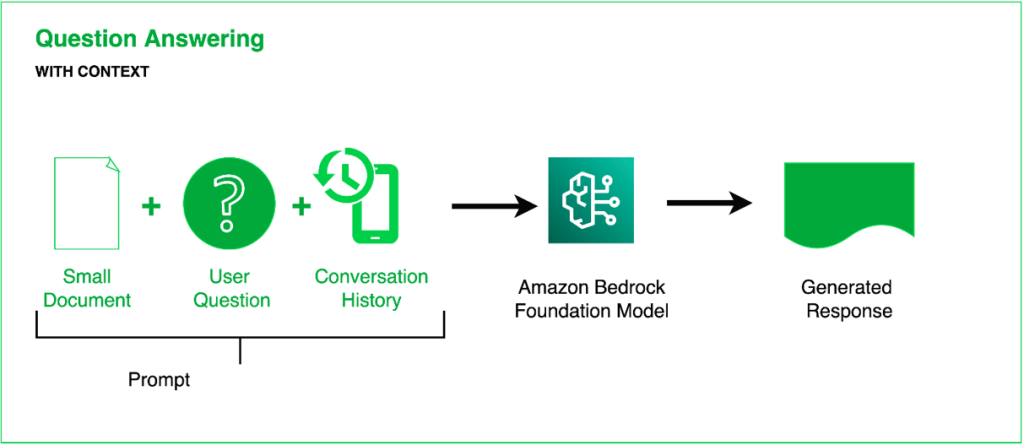
Figure 2: Q&A based on context and history
This approach works well for small to medium size documents with few pages (tested for up to 1MB of PDF/Word documents). First the user uploads the document using a file open dialog for Word and PDF files. Once the document is selected, based on its type, its content is extracted. For PDF documents the file is sent to the Amazon Textract service for text extraction and for Word documents, native Open XML processing is used.
Once the text from the document is extracted, it is then wrapped into a prompt which is then associated with the user entered question. Refer to Figure 3 for explanation of prompt and its components. The prompt also includes directions to the bot on how to interpret the augmented content and answer the question. The first question is always made by the app to the bot, to summarize the document.
The solution includes the following components:
- Application UI – The user interface to upload documents, set model hyperparameters and Amazon Textract settings. The UI is a Windows Forms App targeting .NET 8.
- Anthropic’s Claude on Amazon Bedrock – The Foundation Model
isused to generate responses. Claude is based on Anthropic’s research into creating reliable, interpretable, and steerable AI systems. Created using techniques like Constitutional AI and harmlessness training, Claude excels at thoughtful dialogue, content creation, complex reasoning, creativity, and coding. - Amazon Textract – is a service used to extract text from PDF documents. Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, layout elements, and data from scanned documents.
- OpenXML – is the Open XML NuGet package used to extract text from Word documents.
Handling large documents and context size
For large documents with several pages, which would not fit into the input token capacity of the model, you can first summarize individual pages resulting into smaller chunks, which then can be combined before sending it to the model.
Also, you can leverage a Retrieval Augmented Generation (RAG) pattern which is done by splitting the large document into smaller chunks, converting those into embeddings and stored, usually a vector store. When the user enters a query, you convert the query into embeddings, send it for a semantic comparison with the embeddings generated from the document chunks. Matched embeddings are then used to retrieve corresponding text from the store, which is then augmented into the model along with the user query for a response.
What is a prompt?
Prompts provide a framework for coaxing the desired behavior and responses from an LLM. Prompts enable models to get the necessary inputs and guidance needed for completing a particular task. Prompts can be customized based on the need and demand of the use case. Prompt Engineering is an emerging discipline on developing optimized prompts to efficiently get a LLM to accomplish a variety of tasks.
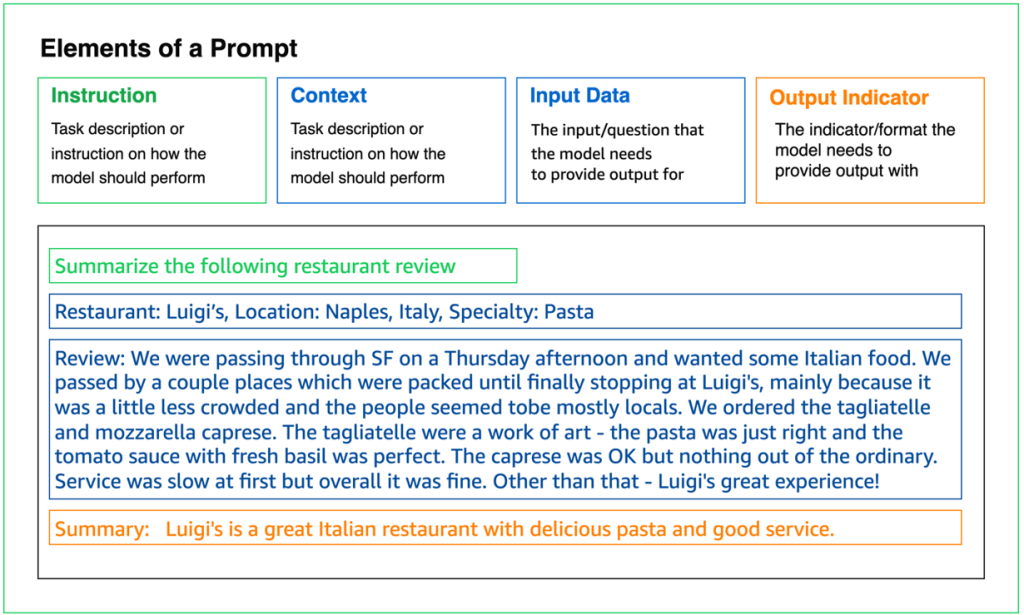
Figure 3: Prompt Components
The key ideas related to prompts are:
- Prompts contain one or more components defined in Figure 3.
- Prompts can contain context, which is additional content that we want a model to consider before responding. Typically, this is the data which the model has not been trained on.
- Prompts are tailored for a particular task and objective.
- Prompts give the LLM guidance about the desired output and format of the output. In the example above, the prompt could be phrased as “provide a response followed by ‘Summary:’” for specifying the output format.
We will cover details about the prompt formation for this app later in this post.
Solution Architecture
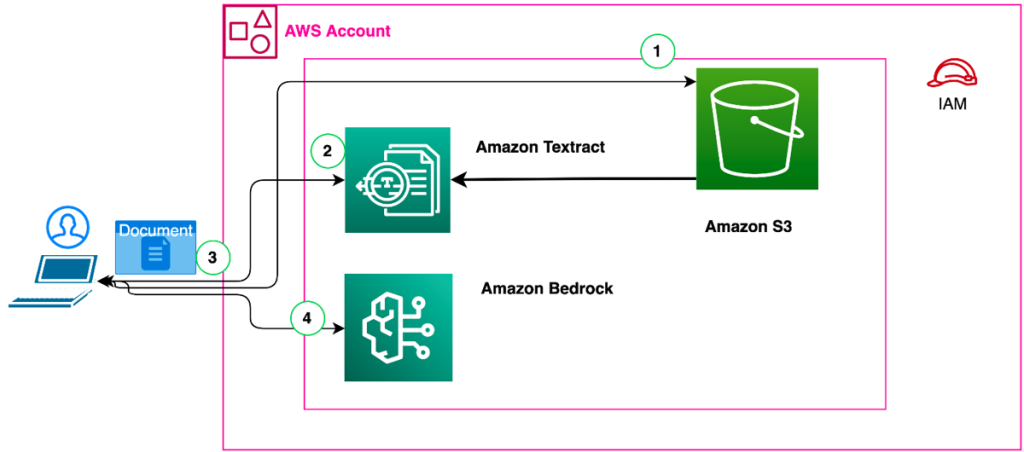
Figure 4: Execution flow with architecture
The execution flow is as follows:
- The user selects a document.
- If the document is a PDF, it is uploaded to S3 and then sent to Amazon Textract for extraction or locally extracted using Open XML if the file type is a Word document.
- The extracted text is returned to the App code
- The extracted content along with the question and conversation history is then formed into a prompt which is then sent to Amazon Bedrock Anthropic’s Claude V2.0 FM for response generation. Once the response is received the response is updated in the conversation view.
While we integrated the text extraction in the frontend for brevity of the code, you can very well separate that into a service endpoint or use orchestration managed with an AWS Step function.
Prerequisites
To implement the solution provided in this post, you should have an AWS account and familiarity with .NET Windows Forms, C# and Visual Studio. You should also be familiar with the AWS SDK for .NET.
You also need a user, or a role configured to be able to access your AWS Account programmatically. For more information on this you can check the Authentication and access documentation. For this sample, using short-term credentials to authenticate is sufficient but if you are building an application to be deployed in production, we recommend understanding the security implications of each option and picking the one most appropriate for your requirements.
Steps to setup Amazon Bedrock Access
The solution uses Amazon Bedrock’s Anthropic Claude V2.0 model. Ensure that this model is enabled for use in Amazon Bedrock as shown in Figure 6. On the Amazon Bedrock console, choose Model Access in the navigation pane on the left. If the model is enabled you will see the status “Access granted” against the Claude model, if it is not then choose Manage model access on the right top of the screen and select the checkbox next to it. Select Save at the bottom of the screen. The access is usually granted instantly.

Figure 5: Model access option in the Amazon Bedrock console
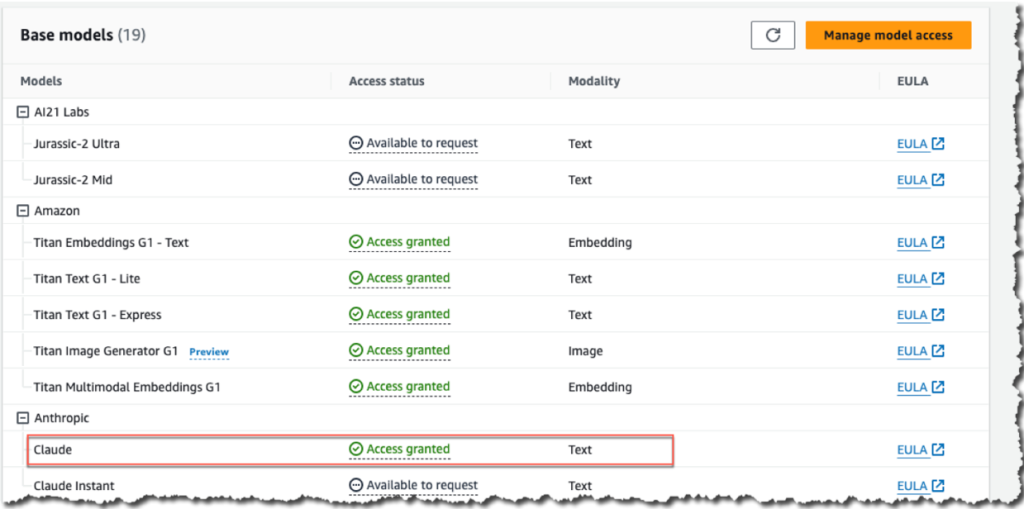
Figure 6: Model access option in the Amazon Bedrock console
Setting up IAM permissions
To be able to use Bedrock, you need a user or a role with the appropriate permissions. To grand Bedrock access to your user identity:
- Open the AWS IAM console.
- Select Policies, then search for the AmazonBedrockFullAccess policy and attach it to the user.
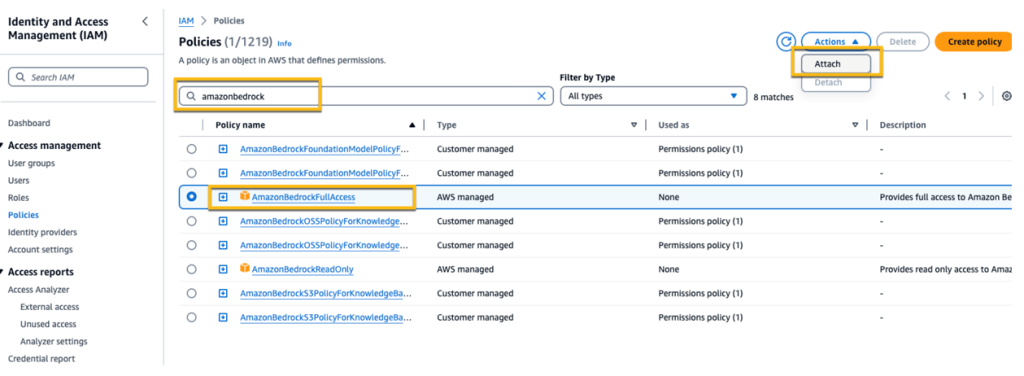
Figure 7: The Policies screen in the AWS IAM console
Configuring AWS SDK for .NET
The AWS SDK for .NET makes it easier to build .NET applications that tap into cost-effective, scalable, and reliable AWS services such as Amazon Bedrock, Amazon Simple Storage Service (Amazon S3) and Amazon Textract. The SDK simplifies the use of AWS services by providing a set of libraries that are consistent and familiar for .NET developers.
A brief about how you call various Amazon services using AWS .NET SDK
The AWS SDK for .NET uses a client request model to simplify communication with AWS services. Here are some key aspects of the model:
- The SDK provides client classes for each AWS service, such as AmazonTextractClient and AmazonS3Client. These client classes handle authentication, request signing and retries behind the scenes.
- Developers make API calls on the client objects to interact with AWS services.
- The clients serialize requests to JSON or XML and send them to AWS endpoints. It then deserializes the responses.
- Common parameters like region are configured on the client and all requests use those parameters by default
- Tasks like signing, error handling and retries are abstracted away, making the API intuitive for .NET developers to use AWS services.
Detailed instructions on developing the conversational document bot
Ensure that you have access to the FM and have set required IAM permissions to call the API (explained above).
Depending on the FM you like to use you will have to pass a set of parameters along with the payload when calling the API.
The defaults setting for the behavior of the model is defined in the /AppSettings.cs Class.
public class AppSettings
{
private float temperature = 0.0f;
private int topP = 0;
private int topK = 10;
private int maxTokens = 500;
private string stopSequence = "\n\nHuman:";
private string s3BucketName = "YOURBUCKETNAMEHERE";
//generate get/set methods for all of the above properties
[CategoryAttribute("Model Hyperparameters"), DescriptionAttribute("Temperature (temperature)– Use a lower value to decrease randomness in the response. value range 0.0 to 1.0.")]
public float Temperature
{
get { return temperature; }
set { if (value < 0 || value > 1)
this.temperature = 0;
else
this.temperature = value;
}
}
[CategoryAttribute("Model Hyperparameters"), DescriptionAttribute("Top P (topP) – Use a lower value to ignore less probable options. Decimal values from 0 to 1 are accepted.")]
public int TopP { get => topP; set => topP = value; }
[CategoryAttribute("Model Hyperparameters"), DescriptionAttribute("Top K (topK) – Specify the number of token choices the model uses to generate the next token.")]
public int TopK { get => topK; set => topK = value; }
[CategoryAttribute("Model Hyperparameters"), DescriptionAttribute("Maximum length (max_tokens_to_sample) – Specify the maximum number of tokens to use in the generated response. We recommend a limit of 4,000 tokens for optimal performance.")]
public int MaxTokens { get => maxTokens; set => maxTokens = value; }
[CategoryAttribute("Model Hyperparameters"), DescriptionAttribute("Stop sequences (stop_sequences) – Configure up to four sequences that the model recognizes. After a stop sequence, the model stops generating further tokens. The returned text doesn't contain the stop sequence.")]
public string StopSequence { get => stopSequence; set => stopSequence = value; }
[CategoryAttribute("Textract Settings"), DescriptionAttribute("The name of the S3 bucket where the document will be uploaded.")]
public string S3BucketName { get => s3BucketName; set => s3BucketName = value; }
public AppSettings() { }
}
AppSettings class
We are using the Windows Forms PropertyGrid control to bind the AppSettings class, so the attributes can be changed while the app is running. This is optional and if you do not want this part, you can comment out the code in the form load event for the AppSettings binding.
Extracting text from the uploaded document
- Based on the selected document type, PDF documents are sent to extract text with Amazon Textract service. PDF Text extraction is done using the StartDocumentTextDetection method defined in the AmazonTextractClient class, which can detect lines of text. It supports JPEG, PNG, TIFF, and PDF documents. Complex documents with multiple pages can be extracted using this method. It also requires the document to be first uploaded to an S3 bucket using the AmazonS3Client class, before processing.
- For Word documents we use Open XML parser to extract the text.
public static async Task<String> StartDetectTextAsync(string s3Bucket, string filename)
{
// The uploaded file
var localFile = filename;
builder.Clear();
//Creating an object of AmazonTextractClient class
//you can set your specific region in the constructor
using (var textractClient = new AmazonTextractClient(RegionEndpoint.USEast1))
//Creating an object of AmazonS3Client class
using(var s3Client = new AmazonS3Client(RegionEndpoint.USEast1))
{
//setting basic parameters for the method call
var putRequest = new PutObjectRequest
{
BucketName = s3Bucket,
FilePath = localFile,
Key = Path.GetFileName(localFile)
};
try
{
await s3Client.PutObjectAsync(putRequest);
} catch (Exception ex)
{
Debug.Write(ex.Message);
}
//Start document detection job
var startResponse = await textractClient.StartDocumentTextDetectionAsync(new StartDocumentTextDetectionRequest
{
DocumentLocation = new DocumentLocation
{
S3Object = new Amazon.Textract.Model.S3Object
{
Bucket = s3Bucket,
Name = putRequest.Key
}
}
});
String JobID = startResponse.JobId;
//storing the jobid of the request for extracting the text
var getDetectionRequest = new GetDocumentTextDetectionRequest
{
JobId = startResponse.JobId
};
//Poll to detect job completion
GetDocumentTextDetectionResponse getDetectionResponse = null;
do
{
//sleep timer to wait until next poll
Thread.Sleep(1000);
getDetectionResponse = await textractClient.GetDocumentTextDetectionAsync(getDetectionRequest);
} while (getDetectionResponse.JobStatus == JobStatus.IN_PROGRESS);
// prepare the response text if the job was successful
// If the job was successful loop through the pages of results and print the detected text
if (getDetectionResponse.JobStatus == JobStatus.SUCCEEDED)
{
do
{
foreach (var block in getDetectionResponse.Blocks)
{
//build a string from each block
BuildBlockString( block.Text);
}
// Check to see if there are no more pages of data. If no then break.
if (string.IsNullOrEmpty(getDetectionResponse.NextToken))
{
break;
}
getDetectionRequest.NextToken = getDetectionResponse.NextToken;
getDetectionResponse = await textractClient.GetDocumentTextDetectionAsync(getDetectionRequest);
} while (!string.IsNullOrEmpty(getDetectionResponse.NextToken));
}
else
{
String message = getDetectionResponse.StatusMessage;
}
}
//return extracted text
return builder.ToString();
}Code showing Textract StartDetectTextAsync method. Implementation source code reference
public static string ParseWordFile(string filePath)
{
using (WordprocessingDocument wordDoc = WordprocessingDocument.Open(filePath, true))
{
Body body = wordDoc.MainDocumentPart.Document.Body;
StringBuilder contents = new StringBuilder();
foreach (Paragraph co in
wordDoc.MainDocumentPart.Document.Body.Descendants<Paragraph>())
{
String innertext = co.InnerText;
if (innertext != null)
{
contents.AppendLine(innertext);
}
}
Debug.WriteLine(contents);
return contents.ToString();
}
}OpenXML word document parsing function
Preparing the payload for the Amazon Bedrock API
For this solution we are using Anthropic’s Claude 2 model which is a large language model enabling a wide range of tasks, from sophisticated dialogue and creative content generation based on detailed instructions.
The document bot is a conversational bot which means you will have to keep track of the conversation history and ensure including this history in the context passed to the model for inference each time.
The first step in this is to build the prompt which is the detailed instruction sent to the model to generate a response.
Building the prompt
The first step in the prompt building is to include a persona definition which the model will have to assume while responding. It will also contain instructions on how to interpret the context included and instructions on the response requested.
StringBuilder promptBuilder = new StringBuilder();
//Persona Settings - Instructions on how the model should respond based on the persona definition and also provide any additional
//instruction in explaning the rest of the prompt
promptBuilder.Append("You are a helpful assistant. The following text includes the original content of a document,");
promptBuilder.Append("the conversation history between the human and you so far and a followup question which you must answer ");
promptBuilder.Append("with the most acurate response possible.");
promptBuilder.Append("You are allowed to say 'I do not know' if you dont have the answer.");
promptBuilder.Append(Environment.NewLine);The next step is to include the original extracted text from the document:
//Context - The content of the document
//Anthropic model generate more accurate responses, when context is passed in XML Structure
promptBuilder.Append("<Document>" + txtDocumentContent.Text + "</Document>");
promptBuilder.Append(Environment.NewLine);Include the conversation history:
//Input Data - Converstaion History
promptBuilder.Append("<ConversationHistory>" + rtxtResponse.Text + "</ConversationHistory>");
promptBuilder.Append(Environment.NewLine);Add the user question:
//User Question - The question entered by the user. Anthropic requires the prompt to be asked in this format "Human: "
promptBuilder.Append("\n\nHuman:" + txtQuestion.Text);
Add the out indicator for the model:
//Output Indicator - Showing the model to provide response after "Assistant:"
promptBuilder.Append("\n\nAssistant:");Prompt components at a glance
The figure below shows a combined view of various prompt components explained above:
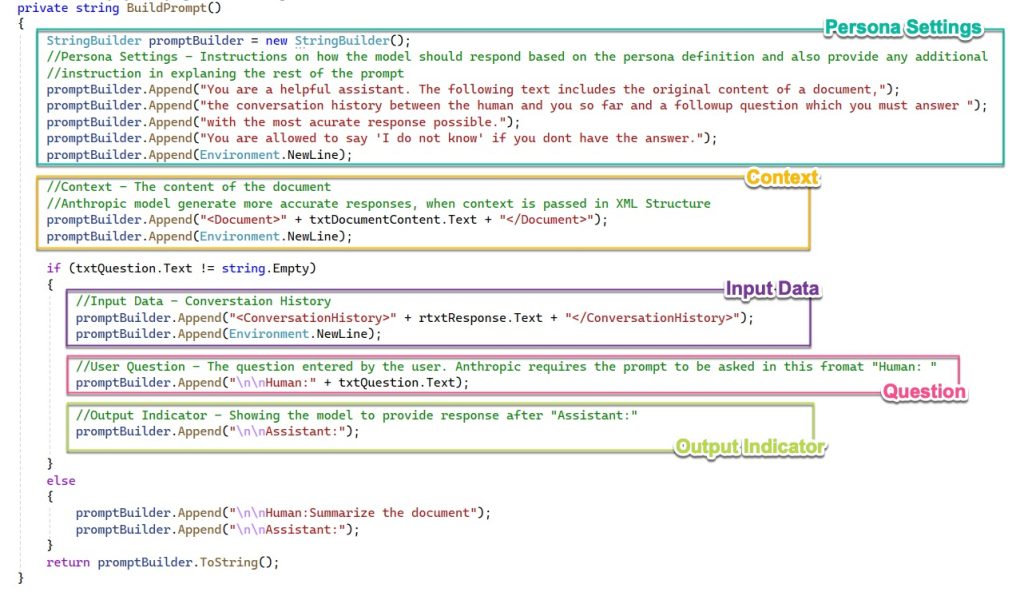
Figure 8: Prompt components in code
Model Inference Settings
Model inference settings guides model behavior and the response generated. The following parameters are passed in the API call:
- Temperature – (optional setting) is the value which determines how creative or accurate the model can be. Use a lower value to decrease randomness in the response. Value range 0.0 to 1.0.
- max_tokens_to_sample – (required setting) The maximum number of tokens to be generated by the model. Recommendation is to keep 4000 tokens. You can read about Anthropic’s input/output size at Anthropic models comparison.
- Top K – (optional setting) The number of most probable choice of words that the model considers for the next token. Choose a lower value to keep the available choice of words low. And keep it higher for a large choice of words.
- Top P – (optional setting) The percentage of most probable choice of words.
- Stop_sequences – (optional setting) an indicator sent to the model to stop generating responses upon receiving the set sequence. This is useful when using streaming API.
Calling Amazon Bedrock when the user enters a question and submit for response
This method uses the prompt constructed in previous steps and the app settings to populate the payload, which is then used to make the Amazon Bedrock call using the AmazonBedrockRuntimeClient class. Note that we are using Anthropic’s Claude version 2.0.
public static async Task<string> InvokeClaudeAsync(string prompt, AppSettings settings)
{
//Setting the model id to call in Amazon Bedrock
string claudeModelId = "anthropic.claude-v2";
//Creating Amazon Bedrock client object, you can optionally pass the region,
//you have to make sure if the service is available in your region
AmazonBedrockRuntimeClient client = new(RegionEndpoint.USEast1);
//preparing the inference parameters
string payload = new JsonObject()
{
{ "prompt", prompt },
{ "max_tokens_to_sample",settings.MaxTokens },
{ "temperature", settings.Temperature },
{ "top_p", settings.TopP },
{ "top_k",settings.TopK },
{ "stop_sequences", new JsonArray(settings.StopSequence) }
}.ToJsonString();
string generatedText = "";
try
{
//Invoking the model
InvokeModelResponse response = await client.InvokeModelAsync(new InvokeModelRequest()
{
ModelId = claudeModelId,
Body = AWSSDKUtils.GenerateMemoryStreamFromString(payload),
ContentType = "application/json",
Accept = "application/json"
});
//Check if the http code is returned ok
if (response.HttpStatusCode == System.Net.HttpStatusCode.OK)
{
//Parse the response
return JsonNode.ParseAsync(response.Body).Result?["completion"]?.GetValue<string>() ?? "";
}
else
{
Console.WriteLine("InvokeModelAsync failed with status code " + response.HttpStatusCode);
}
}
catch (AmazonBedrockRuntimeException e)
{
Console.WriteLine(e.Message);
}
return generatedText;
}Things to consider
- Before running this code, make sure Amazon Bedrock and the Anthropic model are available in your region. You can find the updated information for Amazon Bedrock at Supported AWS Regions and model availability at Model support by AWS region.
- Note that each foundation model provided in Amazon Bedrock has different input prompt format requirements and responses, which requires different parsing for each model responses individually, refer to Amazon Bedrock Runtime examples using AWS SDK for .NET for further reading.
Conclusion
In this post, we shared a conversational document bot sample using Amazon Bedrock and Amazon Textract. This sample application is on GitHub and shows the power of Generative AI. As a .NET developer working on AWS, cloning this repository and experimenting with Amazon Bedrock will provide hands-on learning. Immersing yourself in real-world examples is the best way to understand how you can leverage these transformative technologies to solve problems and create innovative solutions. We also encourage you to learn and experiment with Amazon Bedrock, Amazon Textract and all the other AWS AI services you can use in your .NET code.