AWS HPC Blog
Category: Industries

HTC-Grid – examining the operational characteristics of the high throughput compute grid blueprint
The HTC-Grid blueprint meets the challenges that financial services industry (FSI) organizations for high throughput computing on AWS. This post goes into detail on the operational characteristics (latency, throughput, and scalability) of HTC-Grid to help you to understand if this solution meets your needs.

Deploying predictive models and simulations at scale using TwinFlow on AWS
AWS TwinFlow is an open source framework to build and deploy predictive models using heterogenous compute pipelines on AWS. In this post, we show the versatility of the framework with examples of engineering design, scenario analysis, systems analysis, and digital twins.

Benchmarking the Oxford Nanopore Technologies basecallers on AWS
Oxford Nanopore sequencers enables direct, real-time analysis of long DNA or RNA fragments. They work by monitoring changes to an electrical current as nucleic acids are passed through a protein nanopore. The resulting signal is decoded to provide the specific DNA or RNA sequence by virtue of compute-intensive algorithms called basecallers. This blog post presents the benchmarking results for two of those Oxford Nanopore basecallers — Guppy and Dorado — on AWS. This benchmarking project was conducted in collaboration between G42 Healthcare, Oxford Nanopore Technologies and AWS.

How Evolvere Biosciences performs macromolecule design on AWS
In this blog post, we catch a glimpse into drug discovery to see how Evolvere Biosciences has deployed a customized architecture w/ AWS Batch and Nextflow to quickly and easily run its macromolecule design pipeline.

BioContainers are now available in Amazon ECR Public Gallery
Today we are excited to announce that all 9000+ applications provided by the BioContainers community are available within ECR Public Gallery! You don’t need an AWS account to access these images, but having one allows many more pulls to the internet, and unmetered usage within AWS. If you perform any sort of bioinformatics analysis on AWS, you should check it out!

Optimize Protein Folding Costs with OpenFold on AWS Batch
In this post, we describe how to orchestrate protein folding jobs on AWS Batch. We also compare the performance of OpenFold and AlphaFold on a set of public targets. Finally, we will discuss how to optimize your protein folding costs.

A serverless architecture for high performance financial modelling
Understanding deal and portfolio risk and capital requirements is a computationally expensive process that requires the execution of multiple financial forecasting models every day and in often in real time. This post describes how it works at RenaissanceRe, one of the world’s leading reinsurance companies.

Benchmarking NVIDIA Clara Parabricks Somatic Variant Calling Pipeline on AWS
Somatic variants are genetic alterations which are not inherited but acquired during one’s lifespan, for example those that are present in cancer tumors. In this post, we will demonstrate how to perform somatic variant calling from matched tumor and normal genome sequence data, as well as tumor-only whole genome and whole exome datasets using an NVIDIA GPU-accelerated Parabricks pipeline, and compare the results with baseline CPU-based workflows.
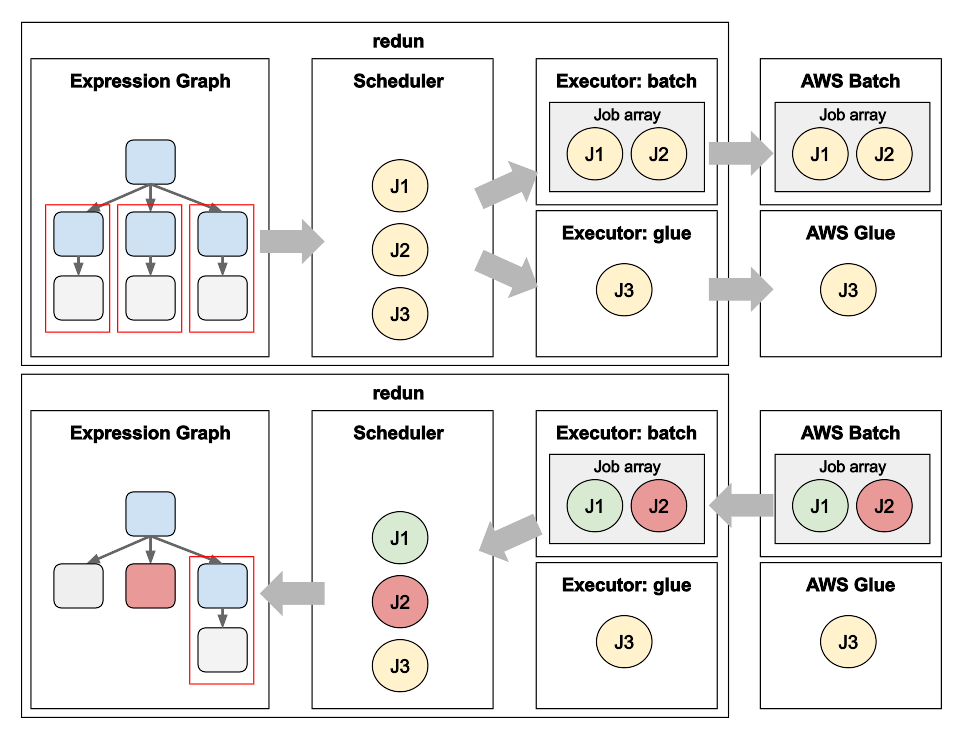
Data Science workflows at insitro: how redun uses the advanced service features from AWS Batch and AWS Glue
Matt Rasmussen, VP of Software Engineering at insitro, expands on his first post on redun, insitro’s data science tool for bioinformatics, to describe how redun makes use of advanced AWS features. Specifically, Matt describes how AWS Batch’s Array Jobs is used to support workflows with large fan-out, and how AWS Glue’s DynamicFrame is used to run computationally heterogenous workflows with different back-end needs such as Spark, all in the same workflow definition.

Data Science workflows at insitro: using redun on AWS Batch
Matt Rasmussen, VP of Software Engineering at insitro describes their recently released, open-source data science framework, redun, which allows data scientists to define complex scientific workflows that scale from their laptop to large-scale distributed runs on serverless platforms like AWS Batch and AWS Glue. I this post, Matt shows how redun lends itself to Bioinformatics workflows which typically involve wrapping Unix-based programs that require file staging to and from object storage. In the next blog post, Matt describes how redun scales to large and heterogenous workflows by leveraging AWS Batch features such as Array Jobs and AWS Glue features such as Glue DynamicFrame.