AWS HPC Blog
Category: *Post Types

Coming soon: dedicated HPC instances and hybrid functionality
This year, we’ve launched a lot of new capabilities for HPC customers, making AWS the best place for the length and breadth of their workflows. EFA went mainstream and is now available in sixteen instance families for fast fabric capabilities for scaling MPI and NCCL codes. We’ve written deep-dive studies to explore and explain the optimizations that will drive your workloads faster in the cloud than elsewhere. We released a major new version of AWS ParallelCluster with its own API for controlling the cluster lifecycle. AWS Batch became deeply integrated into AWS Step Functions and now supports fair-share scheduling, with multiple levers to control the experience. Today we’re signaling the arrival of a new HPC-dedicated instance family – the Hpc6a – and an enhanced EnginFrame that will bring the best of the cloud and on-premises together in a single interface.

Using the Slurm REST API to integrate with distributed architectures on AWS
The Slurm Workload Manager by SchedMD is a popular HPC scheduler and is supported by AWS ParallelCluster, an elastic HPC cluster management service offered by AWS. Traditional HPC workflows involve logging into a head node and running shell commands to submit jobs to a scheduler and check job status. Modern distributed systems often use representational […]

Introducing fair-share scheduling for AWS Batch
Today we are announcing fair-share scheduling (FSS) for AWS Batch, which provides fine-grain control of the scheduling behavior by using a scheduling policy. With FSS, customers can prevent “unfair” situations caused by strict first-in, first-out scheduling where high priority jobs can’t “jump the queue” without draining other jobs first. You can now balance resource consumption between groups of workloads and have confidence that the shared compute environment is not dominated by a single workload. In this post, we’ll explain how fair-share scheduling works in more detail. You’ll also find a link to a step-by-step workshop at the end of this post, so you can try it out yourself.

Scaling a read-intensive, low-latency file system to 10M+ IOPs
Many shared file systems are used in supporting read-intensive applications, like financial backtesting. These applications typically exploit copies of datasets whose authoritative copy resides somewhere else. For small datasets, in-memory databases and caching techniques can yield impressive results. However, low latency flash-based scalable shared file systems can provide both massive IOPs and bandwidth. They’re also easy to adopt because of their use of a file-level abstraction. In this post, I’ll share how to easily create and scale a shared, distributed POSIX compatible file system that performs at local NVMe speeds for files opened read-only.

Using AWS Batch Console Support for Step Functions Workflows
Last year, we published the Genomics Secondary Analysis Using AWS Step Functions and AWS Batch solution as a companion solution to the Genomics Data Transfer, Analytics, and Machine Learning Using AWS Services whitepaper. Since then, many customers have used the secondary analysis solution to automate their bioinformatics pipelines in AWS. A common pain point expressed […]
The Convergent Evolution of Grid Computing in Financial Services
The Financial Services industry makes significant use of high performance computing (HPC) but it tends to be in the form of loosely coupled, embarrassingly parallel workloads to support risk modelling. The infrastructure tends to scale out to meet ever increasing demand as the analyses look at more and finer grained data. At AWS we’ve helped many customers tackle scaling challenges are noticing some common themes. In this post we describe how HPC teams are thinking about how they deliver compute capacity today, and highlight how we see the solutions converging for the future.

Putting bitrates into perspective
Recently, we talked about the advances NICE DCV has made to push pixels from cloud-hosted desktops or applications over the internet even more efficiently than before. Since we published that post on this blog channel, we’ve been asked by several customers whether all this efficient pixel-pushing could lead to outbound data charges moving up on their AWS bill. We decided to try it on your behalf, and share the details with you in this post. The bottom line? The charges are unlikely to be significant unless you’re doing intensive streaming (such as gaming) and other cost optimizations (like AWS Instance Savings Plans) that will have more impact on your bill.
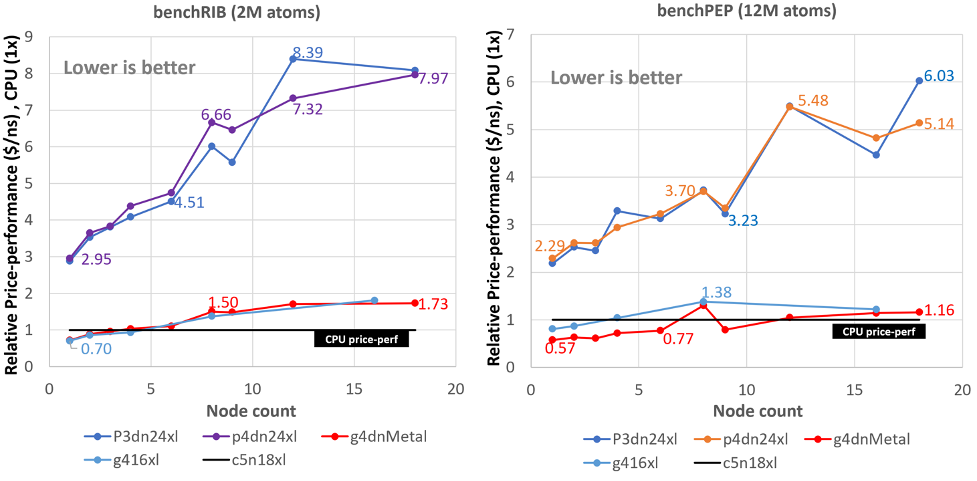
Running GROMACS on GPU instances: multi-node price-performance
This three-part series of posts cover the price performance characteristics of running GROMACS on Amazon Elastic Compute Cloud (Amazon EC2) GPU instances. Part 1 covered some background no GROMACS and how it utilizes GPUs for acceleration. Part 2 covered the price performance of GROMACS on a particular GPU instance family running on a single instance. […]

Running GROMACS on GPU instances: single-node price-performance
This three-part series of posts cover the price performance characteristics of running GROMACS on Amazon Elastic Compute Cloud (Amazon EC2) GPU instances. Part 1 covered some background no GROMACS and how it utilizes GPUs for acceleration. This post (Part 2) covers the price performance of GROMACS on a particular GPU instance family running on a […]

Running GROMACS on GPU instances
Comparing the performance of real applications across different Amazon Elastic Compute Cloud (Amazon EC2) instance types is the best way we’ve found for finding optimal configurations for HPC applications here at AWS. Previously, we wrote about price-performance optimizations for GROMACS that showed how the GROMACS molecular dynamics simulation runs on single instances, and how it […]