AWS for Industries
Enhancing trading strategies through cloud services and machine learning
Please be aware this blog post dives deep into some areas of trading fundamentals. An intermediate level of trading knowledge is beneficial when reading this blog post.
—
Traders at financial institutions need to sift through a rapidly growing blizzard of news across real-time and historical data from thousands of sources. Combined with social media and tweets, financial markets are at the center of a “perfect storm” of surprise and uncertainty. Some trading decisions are made by algorithms in microseconds, generating profits at a speed and frequency impossible for a human trader to mimic.
As businesses continue to adapt to this ever-changing, data-driven world, new tools and capabilities to analyze markets and trading are required. On AWS, compute power and scalability meet the broadest and deepest machine learning (ML) capabilities to provide our financial services customers with the power to automatically derive insights from vast quantities of data. This allows traders to identify hard-to-visualize patterns in data and improve their reactions to the market. For example, Millennium Management uses Amazon SageMaker to securely add ML capabilities and integrate provable security into their development process, reinforcing the importance of balancing security and agility through automation.
Assets can be highly interconnected, sometimes with complex relationships. Seemingly unrelated events happening on the other side of the world can affect price movements in local markets. Trillions of cause-and-effect relationships happen every day and can influence changes to an asset’s price, as well as its intrinsic value. This continual loop of interdependencies makes it difficult for humans alone to identify and understand patterns and drivers behind assets’ movements, making it impossible to uncover the root cause behind fluctuations of financial instruments.
By leveraging the AWS Cloud, the power of a data lake, and processing data with machine learning, this blog brings together an approach to combine data pipelines and core components into ML solutions to develop a new generation of investment decision-making tools. We are not suggesting using this approach for algorithmic trading, but rather, to supplement a firm’s internal decision-making capability to create differentiated tools “as a service” for their own clients, or perhaps even uncover hidden alpha.
The key stages and AWS solutions outlined in this article are:
- Defining the required data to train a machine learning model – AWS Data Exchange
With AWS Data Exchange, customers can source external information very rapidly by using the AWS Data Exchange API to load data directly into the cloud and analyze it with a wide variety of AWS analytics and machine learning services. The AWS Data Exchange filter in AWS Marketplace provides more than 1,000 data products now available from over 80 qualified data providers. Qualified data providers include category-leading and up-and-coming brands such as: Reuters, Foursquare, TransUnion, Change Healthcare, Virtusa, Pitney Bowes, TP ICAP, Vortexa, IMDb, Epsilon, Enigma, TruFactor, ADP, Dun & Bradstreet, Compagnie Financière Tradition, Verisk, Crux Informatics, TSX Inc., Acxiom, Rearc, and many more.
- Data preparation and standardization – AWS Lake Formation
AWS Lake Formation makes it easy to set up a secure data lake in days. A data lake is a centralized, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. A data lake enables you to break down data silos and combine different types of analytics to gain insights and guide better business decisions.
- Model training and deployment – Amazon SageMaker
Amazon SageMaker addresses model training and deployment challenges by providing all the components used for machine learning in a single toolset, so models get to production faster with much less effort and at lower cost. The tools cover the entire ML lifecycle, from initial exploration to managing the production estate. They are seamlessly integrated with other AWS products and security features. Organizations can use this toolset to align their ML development processes with complex internal governance and satisfy most of their security requirements.
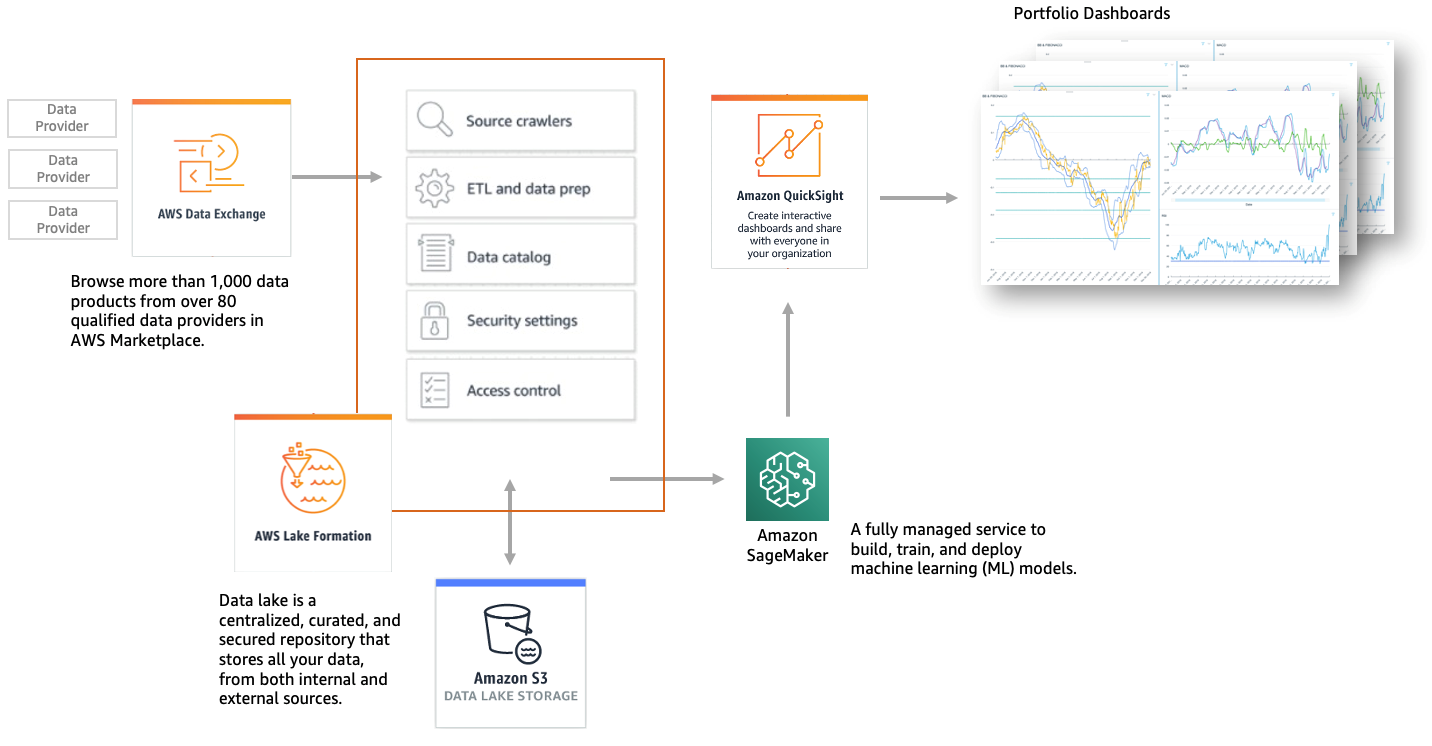
Figure 1: Amazon Machine Learning architecture for bond yield prediction use case
Japanese government bond yields prediction ML use case
This use case demonstrates how a firm would use machine learning to predict future movements of 10-year Japanese government bond yields. This requires us to analyze millions of events and pre-conditions that may cause a particular asset to move in a particular direction. We capture as many of these pre-conditions as possible through historical data or smart feature engineering. Predicting future price levels of various assets gives sell-side traders and buy-side portfolio managers the ability to build better trading strategies or to advise their clients.
Domain knowledge of the Japanese government bonds is required, as well as an understanding of how fixed income markets work, including what changes the value of a bond and differences of the bond types (callable, strips, convertible, etc.) to determine what data is required to predict, approximate, and calculate the bond yields.
The first step is to access historical data for every financial asset (stock, bond, FX rate, or commodity) that potentially correlates with the asset we want to predict. For the best trading strategies and the most accurate machine learning algorithms, we need to collect and use all relevant data in order to create as many informative features as possible.
In this use case, we look at FX and fixed income-related data, since fluctuations in FX and swaps are leading indicators of changes in bond yields. We incorporate data points from the global economy, specifically interest rates in several different currencies, as well as inflation rates and Gross Domestic Product (GDP).
Data gathered from the Japan stock market indicates the overall health of the Japanese economy, and the government bond yield’s likely direction. We gather additional data including export statistics for manufactured goods such as heavy machinery, electronics, and vehicles, and commodity prices including oil, copper, and silver. As all these asset classes affect bond prices due to fundamental economic and business connections. We extract the required historical data through AWS Data Exchange, and via APIs for all of the different datasets available in cloud native formats on AWS.
The next step is to use feature engineering. This is the process of extracting additional “meaning” from the data. This is the most crucial step for unravelling hidden connections, patterns, and correlations in the data. These “features” give us a deeper understanding of assets from different perspectives. This in turn helps the machine learning algorithms detect deeply rooted patterns and correlations between the different data points, which will help improve the accuracy in predicting future data sample sets.
In this use case, we add different types of features, including:
- Technical indicators, such as Bollinger Bands, RSI, moving averages, and MACD, are widely used by technical traders to trade their position based on the technical analysis of these and other factors.
- Trend extraction and removal of noise using Fourier transforms or geometric Brownian Motion. Having trend approximations helps machine learning algorithms pick up prediction trends more accurately. Figure 2 shows how short- and long-term trends can be extracted from a real-time series by use of Fourier transforms with differing numbers of components.
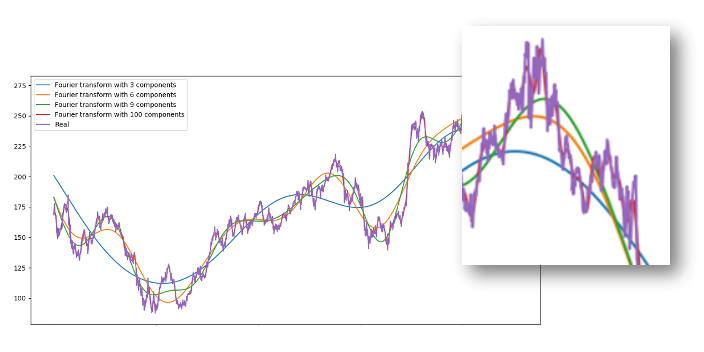 Figure 2: Asset denoising by extracting short- and long-term trends. More components help approximate the actual signal.
Figure 2: Asset denoising by extracting short- and long-term trends. More components help approximate the actual signal.
- Anomaly detection on options pricing. Options pricing combines a lot of data as the prices of option contracts depend on the future value of the underlying assets. Using deep unsupervised learning (Amazon SageMaker Random Forest Cut) we will try to spot anomalies in everyday pricing, such as different prices of options with relatively similar “Greeks” (delta, gamma, etc.). These anomalies may indicate an event that the algorithm can use to learn the overall price pattern.
- Fundamental analysis. Analyzing stock performance and macroeconomic trends using fundamentals such as stock price-to-earnings ratio or return on investment can show whether an asset is correctly priced. Stock market and economic movements approximate the health of the economy, therefore indicate the yield of government bonds.
- Sentiment analysis on news reports can indicate that an asset will move in a certain direction. We will extract sentiment about each asset by reviewing economic news to determine whether the stories for each day were positive, neutral, or negative to extract sentiment about each asset. As investors closely follow daily economic news and analysis to make investment decisions, there is a high probability that if the news for a stock today is extremely positive, shortly thereafter the price of that stock will increase.
- Eigen portfolio – eigendecomposition of the returns covariance matrix using principal component analysis (PCA), a machine learning algorithm for dimensionality reduction.
- Extracting high level features using auto-encoders – most of the aforementioned features (fundamental analysis, technical analysis, denoising) were found after decades of research. Maybe, though, we have missed something and there are hidden correlations that people miss due to the vast amount of data points, events, assets, charts, etc. With stacked autoencoders (a type of neural networks) we can find new types of features and hidden correlations that affect stock movements.
With all the critical data collection and feature engineering complete, we can move to training the machine learning model. We will use the Amazon SageMaker DeepAR algorithm, a supervised learning algorithm for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNN). We use DeepAR because when our dataset contains hundreds of related time series, which is the case when predicting capital markets assets, DeepAR outperforms the standard ARIMA and ETS methods. Fitting DeepAR is easy, as we have a informative dataset, comprised of raw asset data and features, feeding the right information to the model. Finally, we use Amazon QuickSight, a cloud-powered business intelligence service to visualise the asset trends, predicted values, technical indicators, and previous trading history.
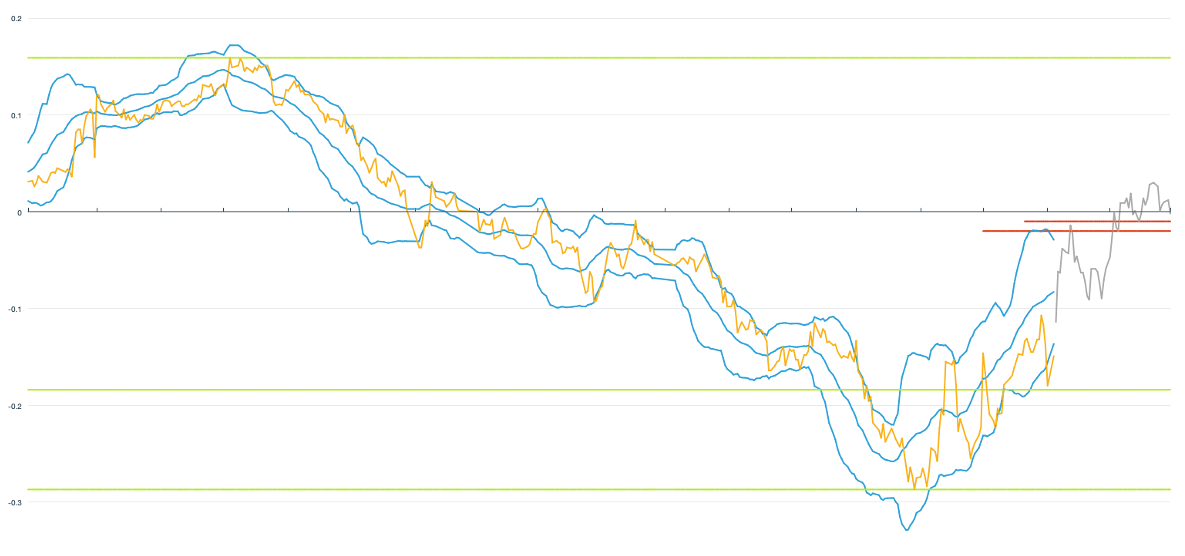 Figure 3: Shows the Japanese bond yield (yellow), Bollinger bands (blue), Fibonacci levels (in green) in the period Jan 1, 2018, to Nov 30, 2019. The predicted yield is shown in gray for the period Dec 1, 2019, to Dec 31, 2019.
Figure 3: Shows the Japanese bond yield (yellow), Bollinger bands (blue), Fibonacci levels (in green) in the period Jan 1, 2018, to Nov 30, 2019. The predicted yield is shown in gray for the period Dec 1, 2019, to Dec 31, 2019.
Watch this video, AWS Data Exchange, Find & Subscribe to Third-Party Data, and see a demo of what is contained within this blog post.
Capital markets companies using AWS to discover new opportunities and implement cost-saving measures that increase efficiency through machine learning and data lakes include Vanguard, Citadel, T. Rowe Price, and others. There are many other detailed use case examples.
Conclusion
In this blog post, we explored an approach to predicting future movements of Japanese bond yields using machine learning and advanced analytics. Through products including AWS Data Exchange and Amazon SageMaker, and utilising the compute power of cloud, investment professionals can easily gain new insights into the assets they trade and generate new investment strategies.
Among the benefits of this solution are the ability to:
- Merge external (market) and internal data in one centralised environment
- Quickly run and optimize machine learning models to predict future price levels of various assets
- Streamline the price/yields prediction process that links the trade-generating strategies with notifications and trade automation
- Visualize assets, technical indicators, internal data, and predictions in one place
This article provides a use case of the capabilities cloud and machine learning offer to investment professionals in their quest for uncovering hidden alpha. There are many other machine learning use cases across banks and insurers we help customers solve including extracting text automatically and data from scanned documents, prediction customer churn, fraud and anomaly detection, and claim automation. Learn more about other use cases and customer examples or about AWS for Financial Services.