AWS for Industries
How to analyze well drilling reports using natural language processing
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Eighty percent of all company data is unstructured. Energy companies are not the exception. One example is weekly and daily reports for drilling and production activity. These reports include information about actions performed in the field to remediate common issues during drilling operations. Extracting information about problems and remediations from the unstructured data can help reduce the risk of drilling operations by leveraging historical events when deciding where and how to drill. This post shows how AWS services can combine to create an automated pipeline to extract insights from unstructured data in well activity reports.
Overview of solution
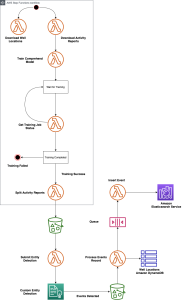
To accomplish our task, we use a combination of AWS services to create an automated serverless analytics pipeline. This extracts well control events from weekly activity reports as reported to the Bureau of Safety and Environmental Enforcement (BSEE), and presents them in an application that drill engineers can use to interrogate and visualize those events.
Operators record well activity reports into Form 133 to BSEE. This form includes key information like the company name, contact, well identifier (API number), and the depth of the drilling operations during the week reported. It also includes a text remark area where operators describe the activities that were performed during the week. These activities include events where they encountered a problem, for example, a well control problem. BSEE provides access to these reports in PDF and text formats on their website. For our solution, we use Natural Language Processing (NLP) against the text remark field to detect key events by searching for key words that can flag a well control problem. Once a problem has been identified, we extract other key entities and store the information into a database that engineers can interact with.
Prerequisites
The solution must be executed in an AWS Region that supports all of the services in the diagram above. At the time of this posting, the following regions are supported: us-east-1 (Virginia), us-east-2 (Ohio), us-west-2 (Oregon), ca-central-1 (Montreal), eu-west-1 (Ireland), eu-central-1 (Frankfurt), eu-west-2 (London), ap-southeast-1 (Singapore), ap-northeast-1 (Tokyo), ap-southeast-2 (Sydney), ap-northeast-2 (Seoul), and ap-south-1 (Mumbai). Please refer to the AWS Region Table for more information.
Before you deploy the solution’s resources, clone the solution’s GitHub repository.
Walkthrough
Amazon Comprehend is a Natural Language Processing (NLP) service provided by AWS. It allows you to detect entities in your unstructured data from a range of default entities or to train the service to detect entities that are customized to your environment and domain. You can do this without having to learn the intricacies of optimizing an NLP machine learning model. In our case, we train Amazon Comprehend to detect key events on the text remark field from Form 133.
Before we can execute our pipeline, we need to train Amazon Comprehend to detect our custom entities. You can train Amazon Comprehend to detect your custom entities by providing the mapping of entities and key words, along with a labeled training dataset where your key words exist. AWS Step Functions lets you coordinate multiple AWS services into serverless workflows so you can build and update apps quickly. We will use an AWS Step Functions state machine to orchestrate downloading the raw data to Amazon S3, creating a training dataset and submitting a custom entity training job. We provide an entity list of key words that map to a well control event to Amazon Comprehend for training.
The state machine leverages AWS Lambda functions for each step. With AWS Lambda, you write your application logic into a function in one of the supported runtimes and AWS handles loading and running your code into a compute environment when your function gets called or triggered. This eliminates the need for you to focus on maintaining the underlying server, container, and runtime environments. The data is downloaded into Amazon S3 which is a scalable, serverless object store platform. It provides cost-optimized storage classes to map to your use case.
Once our training completes successfully, the last step of our workflow starts our automated pipeline by triggering an AWS Lambda function. The data flow for our pipeline starts by reading the text data made available by BSEE that was downloaded in the workflow from Amazon S3.
At the time of this writing, Amazon Comprehend has a maximum input file size of 100 MB for jobs that detect custom entities. Because our dataset can be larger, we use an AWS Lambda function to split the raw dataset into smaller segments that we can then individually pass to Amazon Comprehend. The AWS Lambda function Split SNWAR splits the raw file and writes the segments into another folder in our bucket.
Uploading the divided files into a bucket generates an event that triggers a second AWS Lambda function, Submit-Comprehend, to submit custom entity detection jobs asynchronously to Amazon Comprehend. Upon completion, Amazon Comprehend asynchronous jobs generate a file in Amazon S3 marking the location of detected custom entities in the source data.
We can use this file generation event to trigger a third Lambda function, process-events, that processes each event detected as a custom entity by Amazon Comprehend. Because events can happen in different years and geo-locations, it is important that we store the events in a platform that allows free-form text searches on our data. Visualizing the data based on the coordinates for the wells is important to allow engineers to drill down into particular areas of interest. Elasticsearch is a popular open-source database based on the Lucene project that is optimized for text searches. Kibana is a visualization tool optimized for visualizing data in Elasticsearch format. AWS offers a managed service called Amazon Elasticsearch Service that allows you to run an Elasticsearch database cluster without worrying about the heavy lifting of maintaining the infrastructure or database software. The service includes a Kibana interface that goes along with your domain. For our solution, we store events in an Elasticsearch domain.
Each event is stored in a document that includes the event type, well location, depth, date, and text remark fields. Our third Lambda function creates these documents by calling other AWS services to complete each record. The mapping of a well and its location is not provided in the weekly activity report. This reference data is provided in raw format by the Bureau of Ocean Energy Management (BOEM). We have pre-loaded this reference data into Amazon DynamoDB. Amazon DynamoDB is a serverless, NoSQL key-value store. For our use case, it provides an optimal response time during the execution of the AWS Lambda function. Once all of the elements of the record are acquired, the AWS Lambda function stores the record into a queue in Amazon Simple Queue Service (SQS). Amazon SQS is a serverless queue management system that allows you to decouple a process or a workflow without having to maintain the infrastructure and software that implements your queue.
The insertion of records into an SQS queue creates an event that triggers our fourth and final AWS Lambda function, ingest-es. This function inserts each event document record into the Elasticsearch domain. Decoupling the inserts into the database through a queue provides a scalable pattern. This allows each function to focus on a small task, following the microservices pattern.
Once our data lands in Elasticsearch, we create an index pattern in Kibana that allows engineers to visualize events by well and well location.
Cost
You will incur AWS usage charges when deploying resources and executing the AWS Step Function state machine. Please review the pricing page for the services discussed to get familiar with their cost structure. A deployment of type test is approximately $4.80 based on pricing at the time of this writing. Note that you can deploy resources without executing the state machine.
Create resources
Create an AWS CloudFormation stack using the CFN-Pipeline.yaml template that is included in the top folder of your local clone of the repository. As parameters, select the deployment type of Test as well as an email address to use as your username to access the Kibana application.
After the template creation completes, copy the contents of the Code folder (not the folder itself) along with the ‘buildspec.yml’ and ‘WellAnalytics-CFN.zip’ files from your local clone of the repository to the top-level directory of the provisioned S3 bucket. You can navigate directly to the S3 bucket by reviewing the Resources tab of your stack.

The action to copy the content will trigger a pipeline in AWS CodePipeline that will create libraries, pre-requisites and launch our second AWS CloudFormation stack, Well-Analytics-CFN. Navigate to AWS CodePipeline and ensure a successful execution of the well-analytics-pipeline before proceeding. The average execution time for the pipeline is 20 minutes.

Navigate to AWS CloudFormation to review the execution of our second stack. The average execution time for the second stack is approximately 20 minutes. Once your second stack completes successfully, start your data analysis pipeline by navigating to the AWS Step Functions console and starting a new execution of the DataCollectionStateMachine.

Review the logs for each element of the state machine to ensure a valid execution. The pipeline executed successfully when you can see indexed documents in your Elasticsearch domain by navigating to the Amazon Elasticsearch service console. The average deployment time is around 45 minutes from the start of the AWS Step Functions execution.

Search events and visualize solution
Login to the Kibana instance for your Elasticsearch domain. You can find the URL from the Amazon Elasticsearch console. Use the email provided as parameter for your stack as the username and the temporary password received via email. Note that the email with your temporary password might be directed to your Junk Folder.

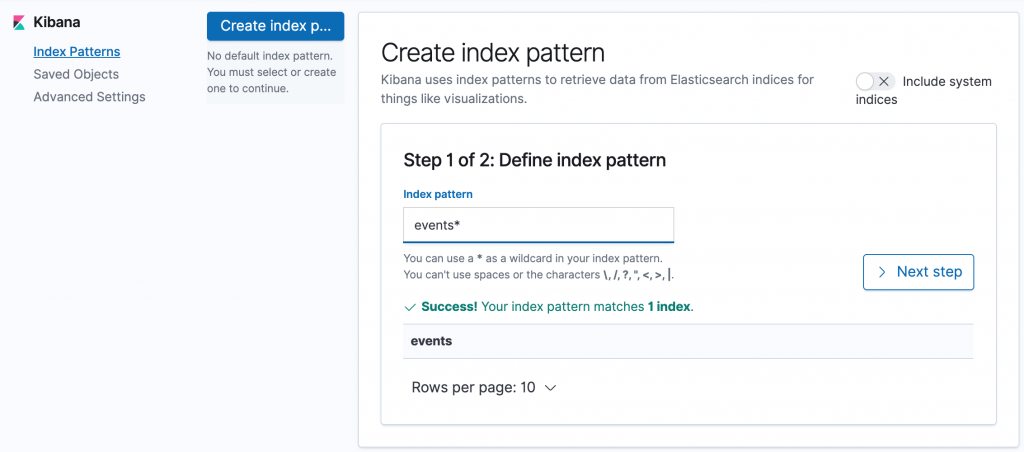
Index patterns guide Kibana to the indices you want to investigate. In Kibana, open Management and then click Index Patterns. Enter events* in the Index pattern field and click Next Step. In Step 2, select EVENT_DATE on the Time Filter field name and click Create index pattern.
Navigate to the discovery tab and search for a key word e.g. influx. Update the date period to show past years e.g. Last 45 years.

A good next step would be to create a dashboard in Kibana with the format and information of your liking.
Clean up
When you are done exploring the solution, you can clean up your resources. First navigate to S3 and empty the buckets created e.g. 123456-bsee-well-analytics, 123456-bsee-sourcecode. Once completed, delete the AWS CloudFormation stacks in reverse order of deployment. Namely, first delete the WellAnalytics-CFN stack, wait for the action to complete and then delete the stack that deployed the AWS CodePipeline resources.
Conclusion
Extracting information about problems from unstructured data can help reduce the risk of drilling operations by leveraging historical events when deciding where and how to drill. This post showed how AWS services can combine to create an automated pipeline to extract insights from unstructured well activity reports.
Also, it showed how serverless services allow you to focus on the solution that you are trying to build instead of the undifferentiated heavy lifting of maintaining and scaling individual technology components including storage, computing, database, queue, and natural language processing capabilities.
Try custom entities now from the Amazon Comprehend console and get detailed instructions in the Amazon Comprehend documentation.