AWS for Industries
Philips Prototypes a Large-scale, Near-real-time Inference Platform to Extend Medical Imaging Using AWS
Image-guided therapy solutions provide visual guidance during minimally invasive therapies. However, with interventional systems located within hospitals, enabling faster innovation and a roll-out of new technologies to the field has been a significant challenge. To solve this, Philips has prototyped a large-scale, near-real-time inferencing platform on Amazon Web Services (AWS) to extend the capabilities of interventionalists performing these procedures.
Integrating technological improvements for hospital-based systems, in areas such as machine learning is dependent upon expensive hardware replacements, upgrades, and application modernization. Additionally, safety-critical components of systems must stay close to the patient. With those factors in mind, enabling new features and services by first utilizing hybrid architectures that extend on-premises platforms is often the fastest way to cloud adoption and innovation.
Moving machine learning algorithms for hybrid healthcare systems into the cloud introduces several challenges: high-performance requirements, demanding availability, cost-effectiveness, and medical device regulation. With thousands of systems located in hospitals around the world, there is often unpredictable demand with near-real-time latency requirements. Implementing new features should not significantly increase costs and cloud resources must have higher levels of utilization than on-premise systems for efficiency. And, adhering to the applicable medical device regulations should still allow for achieving a high velocity of innovation and releasing of novel functionalities to the field.
By leveraging AWS IoT and Amazon Elastic Kubernetes Service (EKS), the strict requirements for availability and performance are met while driving the overall solution cost down when compared to modifying on-premises deployments. These technologies also enable the decoupling of non-critical components of the existing platform which permits a modern way to meet regulatory requirements.
Philips Use Case

Figure 1 – Philips Image Guided Therapy Azurion System
Philips has image-guided systems deployed in thousands of hospitals around the world that provide real-time imaging capabilities for minimally invasive interventional procedures. To provide the best possible experience for their customers, Philips has designed a data ingestion and inferencing platform that enhances successful patient outcomes all while meeting the strict reliability and response times required for patient care.
Enhancements are achieved by leveraging the platform to execute new and existing computationally-intensive algorithms against incoming imaging data. For example, one of the algorithms used is for key event detection during angioplasty procedures. A machine learning model is used to detect when an event occurs, such as cardiovascular balloon inflation. The algorithm executes against the images that are generated when an interventionalist radiates a patient and subsequently uploaded to the cloud. It then automatically logs the event to offload tasks from the interventionalist. Feedback from the algorithm back to the hospital takes no longer than 5 seconds end-to-end.
Implementation
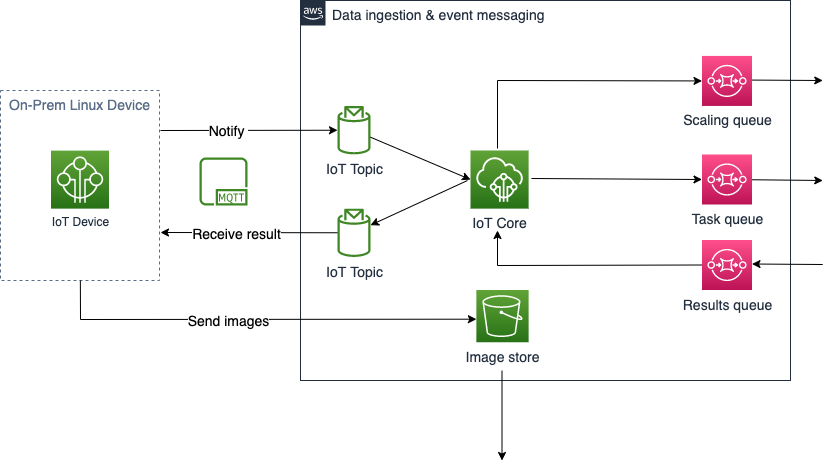
Figure 2 – Local Management, Data Ingestion and Event Messaging Architecture (Continued with Figure 3)
Local Management
Hospital-based image-guided therapy systems are extended to the cloud by utilizing AWS IoT. A lightweight, on-premise Linux device acts as a gateway for imaging data and an event generator to kickoff backend AWS processes. Additionally, AWS IoT enables remote management capabilities of the device allowing for future enhancements, including new algorithms and use cases.
Data Ingestion & Event Messaging
To meet the strict low-latency requirements for the interventional healthcare workload, data ingestion and event messaging capabilities were decoupled, allowing for a more resilient and elastic system, as the storing of images was separated from backend processing.
Several data ingestion and storage techniques can be used depending on payload and latency requirements of the workload. However, for medical imaging with file sizes between a hundred megabytes and several gigabytes, uploading to Amazon S3 using S3 Upload APIs meets the strict performance requirements and connections are stabilized further when enabling S3 Transfer Acceleration, which moves traffic off the public internet and onto the AWS edge networking backbone.
Event messaging is a critical path for developing low-latency solutions. How backend processing should be triggered by an event and how messages should be transmitted from distributed systems to the cloud are key questions to consider. Leveraging the lightweight messaging protocol, MQTT, natively supported by AWS IoT services, enables secure and reliable transmission of data. With a publish/subscribe model and small packet size, it minimizes network bandwidth usage, reduces network latency and provides low-level security required for sensitive data. Messages with information containing the location of data and how the data should be processed can be sent as IoT topics and published immediately to an Amazon Simple Queue Service (SQS) queue for backend mechanisms to consume. An additional benefit exists for backend processing if an algorithm requires multiple file locations as a topic could contain the necessary information.
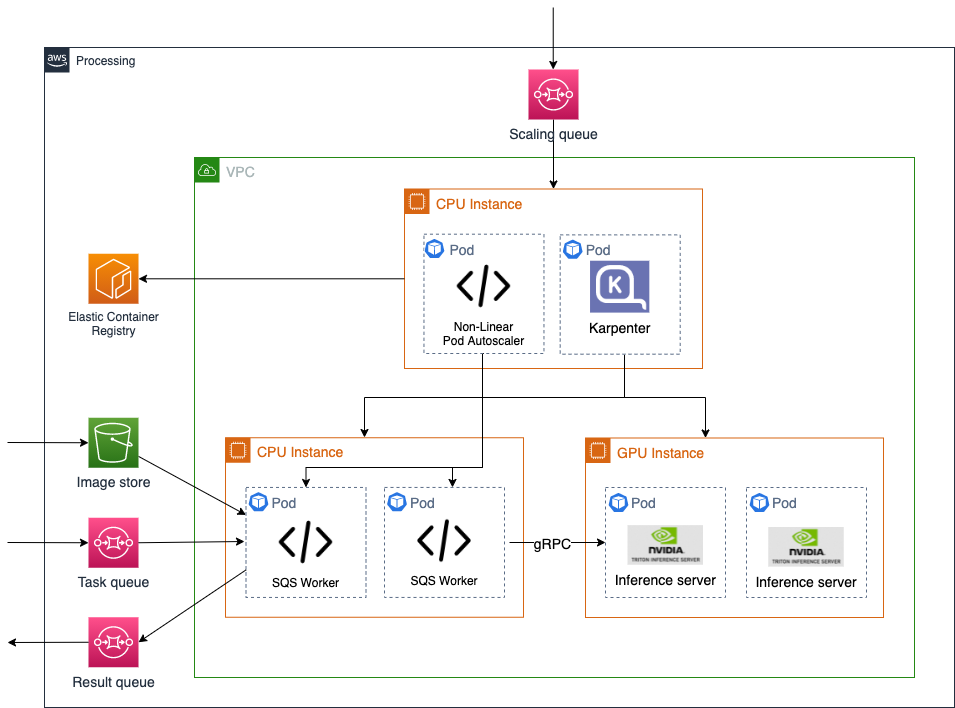
Figure 3 – Backend Processing Architecture (Continued from Figure 2)
Processing
The processing backbone of the platform is built on Amazon Elastic Kubernetes Service (EKS) as a scalable and high-performant compute platform supporting various algorithms and machine learning use cases. Containers are deployed to monitor the Amazon SQS queue for incoming requests. Once obtaining algorithm and data location information from the task, containers responsible for computation are provisioned, utilizing the instructions to pull the required algorithm container image from an Amazon Elastic Container Registry (ECR) and the image data from Amazon S3. For machine learning-based algorithms, Nvidia Triton is leveraged for optimization and performance. Scaling of Amazon EKS nodes and pods is proactively achieved by monitoring the size of the request queue and adding additional compute capacity as necessary utilizing a custom Non-linear Pod Autoscaler and Karpenter.
GitOps
With EKS as the core orchestration and compute platform, ArgoCD was chosen for cluster management with its intuitive GUI and dashboard. The software development lifecycle framework leverages the GitOps operational framework with the use of tools like GitHub, GitHub Actions, and ArgoCD. Infrastructure provisioning remains largely on Infrastructure as Code (IaC) functionality and resource modules, which helps with speed, scaling, and effective management. Continuous integration and delivery are managed by GitHub Actions workflows configured to automatically trigger a workflow and ensure commits are secure, syntactically correct, and pass all the pre-defined checks before merging into the main branch, thereby reducing efforts in code peer review. Error handling is directly managed from the GitHub runner, and fixed by the developer.
High Performance at Scale
Most user interactions with image guided therapy systems demand near real-time end-to-end response times. The challenge with near real-time requirements, is that networking and service-introduced latencies must be consistently low, and they must remain low at scale. By leveraging the ability to test at scale, it was validated that by using Amazon S3 for its throughput and scalability, combined with AWS IoT for fast notifications to inference servers, performance requirements are able to be exceeded.
The required throughput for data ingestion with Amazon S3 is met by uploading medical images asynchronously. Once the medical images are uploaded, AWS IoT Greengrass sends an immediate MQTT message as an IoT topic and publishes to an SQS queue. An active SQS worker continually polls the SQS queues for tasks that contained algorithm requirements and image location information. This design allows the backend inference servers to start processing with minimal delay. The most important finding when designing this architecture was that technology would not be a prohibiting factor for extending an on-premise system with high performance requirements. The only remaining limiting factor was the last-mile network connection of hospitals.
The processing of medical imagery was also marked as a potential bottleneck. However, by leveraging the flexibility of Amazon EKS to deploy both CPU and GPU based nodes, processing time is minimized by applying the proper computational footprint based on algorithm requirements. For machine learning algorithms, utilizing Nvidia Triton as the inference server optimizes performance even further by streamlining model execution for any framework on any compute infrastructure. In the future, by leveraging technology such as NVIDIA TensorRT and Amazon SageMaker Neo, algorithms can be compiled and additionally optimized to perform best on specific hardware for additional performance benefits.
The final performance results of the solution were determined only after rigorous testing at scale. Assumptions and system properties that hold true for a single user do not always remain true at load. Testing at scale highlighted several opportunities to tune the platform and remove any unforeseen issues that were not accounted for during design, highlighting the importance of this process.
Cost Management
With thousands of devices in the field, remaining cost-efficient at scale is a significant challenge. If a GPU node is not available to process an incoming image request on-demand, the strict latency requirements for the solution will not be met. As a result, scaling is required before existing resources are fully utilized, balancing against the cost of overprovisioning resources. By applying statistical modelling and scaling GPU instances non-linearly with the number of devices, costs can be reduced by a factor of 30 as compared to utilizing a single GPU instance for every system in the field.
A 1:1 scaling approach that guarantees availability results in provisioning thousands of GPU nodes per region that would likely sit idle 99% of the time. One philosophy that can be utilized to scale more cost efficiently is the acceptance of rare impact on performance. While the solution is designed for 7 nines of availability while ensuring that images are not dropped, there may be limited events at the ends of the statistical spectrum that can simply be processed with a longer than usual delay. Given that the algorithms being deployed to AWS are not in the critical path of patient safety, this is usually an acceptable user experience.
Another method that greatly reduces costs is understanding the distribution of load on the platform. As most devices in the field only intermittently send images for analysis, it is possible to serve more than one system with a single GPU. By applying non-linear scaling and the sharing of computational resources, the number of nodes required to meet the demand is exponentially reduced.
Regulation for Healthcare Workloads
Life-critical medical devices are highly regulated. This is important and guarantees an appropriate level of safety for patients, but the validation processes can slow down the rate of innovation. By decoupling non-critical components from on-premise medical device monoliths, the validation effort remains local to the device, while infrastructure in the cloud benefits from a non-medical-device categorization, and algorithms that have a medical categorization can be isolated and released independently. This principle makes it possible to leverage new technologies and drive inventive improvements at a faster rate by allowing rapid development without having to revalidate the whole system for each incremental change.
Conclusion
Using AWS, Philips was able to demonstrate that extending mission critical workloads to the cloud enables faster innovation that improves patient care and staff experience at a lower cost. It was also demonstrated that technology would not be a blocker for meeting strict performance and cost requirements, enabling an entirely new connected ecosystem of cloud-based technologies to enhance hospital-based systems. And, with the flexibility and portability of the platform, it can be adapted to support other modalities across the medical imaging business in the future.