AWS for Industries
Turning Price/Performance Upside Down: Ansys RedHawk-SC™ and Amazon Web Services
Introduction
This blog discusses the insights Ansys and AWS were able to gain by scaling Ansys RedHawk-SC on the AWS Cloud. The joint investigation outlines how to right-size AWS compute and storage resource for optimal price/performance results while running at scale. By combining the capabilities of Ansys RedHawk-SC with being able to scale compute resources on AWS, customers can reduce the overall cost of running sign-off while also accelerating the time to results.
Ansys and AWS Collaboration
With some modern semiconductor integrated circuits (IC) growing past 50 billion transistors, it is impossible for engineers to manage this level of complexity without the help of modern engineering tools. Electronic Design Automation (EDA) describes a category of tools that engineers used to help automate the development process and help manage that complexity.
One of the key elements in the EDA tool chain is Ansys RedHawk-SC. Ansys RedHawk-SC is the industry recognized leader in power integrity and reliability analysis which fills a vital role in the sign-off step of semiconductor development. Sign-off helps developers validate that their design will work as expected once manufactured. This is vital because errors in post-manufacturing functionality often lead to revisions and remanufacturing costs that can exceed $10M for an advanced chip design. Proper verification and sign-off are critical to the success of successful semiconductor IC development and RedHawk-SC is one of the most trusted solutions for design authentication.
Given the complexity of modern semiconductor ICs, sign-off analysis is extremely resource intensive. Analysis tools must simulate the interaction of billions of electrical nodes and interconnects in detail. This requires thousands of CPU core hours, hundreds of gigabytes of RAM, and terabytes of high-performance shared file storage.
Since semiconductor development teams are often under very tight schedule restrictions, reducing the time spent running analysis is key to meeting the manufacturing deadline date, also known as the tape-out date. Being able to scale this workload to more systems with the appropriate configuration can help development teams reduce the amount of time spent in sign-off. However, because of the demanding requirements of compute for sign-off, even the larger semiconductor development teams can find it challenging to acquire sufficient compute resources to efficiently run this workload at scale.
Designed for the cloud
The scale and complexity of sign-off makes it an ideal candidate to run on the AWS Cloud. RedHawk-SC was architected on a purpose-built, cloud-friendly analysis platform called Ansys SeaScape™. RedHawk-SC’s SeaScape database is fully distributed and thrives on distributed disk access across a network. The large chip dataset is automatically sectioned into chunks for various design views, avoiding network loading and latency effects.
Distribution of the computational workload is extremely memory efficient, allowing the optimal utilization of over 2,500 CPUs. This is not an issue for RedHawk-SC which delivers faster runtimes supported by efficient yet massive parallelization. There is also no need for a heavy head-node because the distribution is orchestrated by an ultra-light scheduler consuming less than 2GB for even the largest chips. The same is true for loading and viewing results data with multiple users attaching to a single, thin-client graphical user interface (GUI) for debug.
Ansys RedHawk-SC on AWS
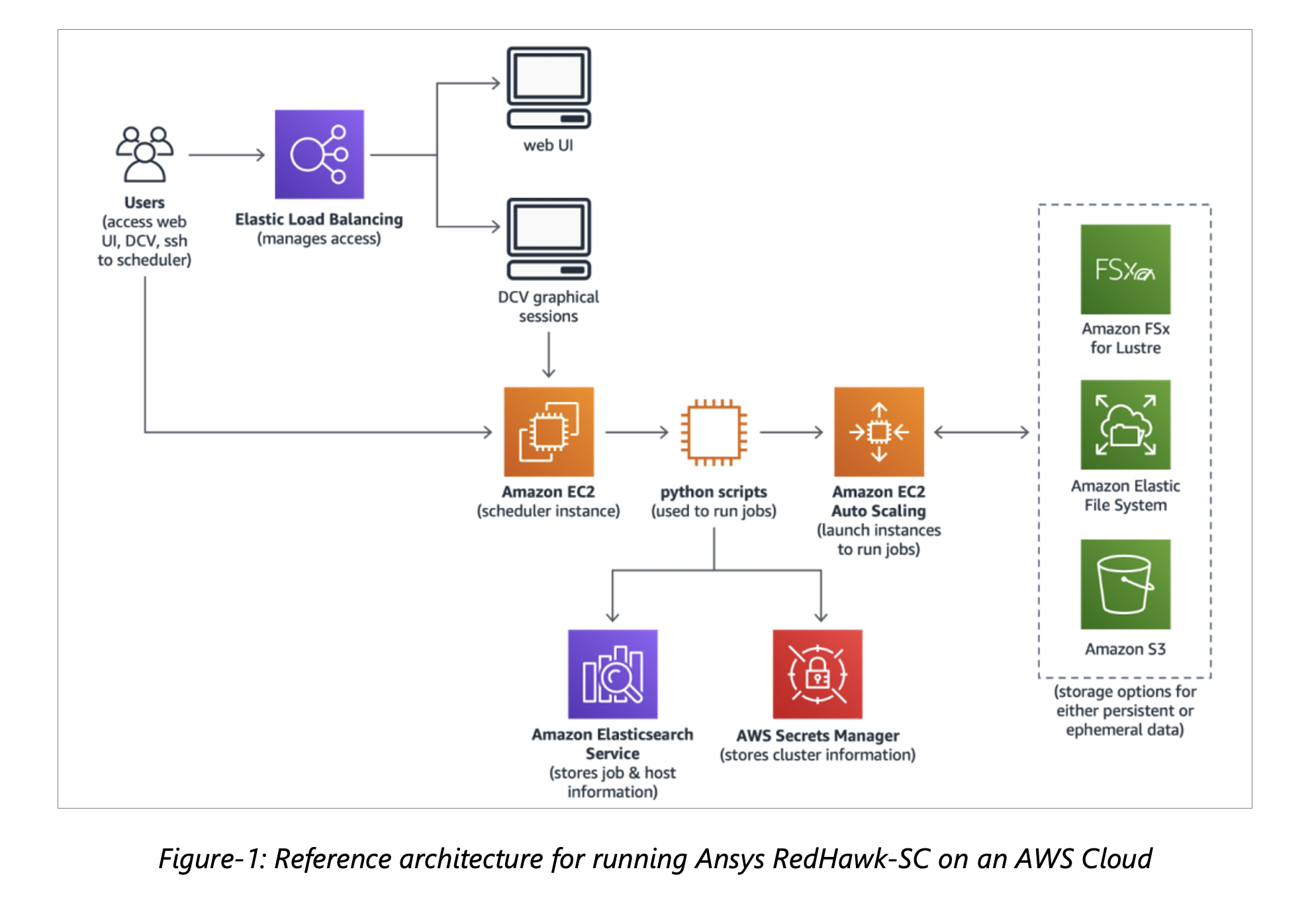
To provide an easy to deploy, EDA ready cloud environment to run RedHawk-SC, we used the Scale-Out Compute on AWS (SOCA) solution to create a cloud environment that provides scalability of compute and storage, budget monitoring, job scheduling, etc. (For guidance on how to set up SOCA for an EDA workload, see Scaling EDA Workloads using Scale-Out Computing on AWS.)
During testing on AWS, we maintained the distribution of the data by enabling persistent storage on a shared file system using Amazon FSx for Lustre. RedHawk-SC distributes the computational workload across “workers” – typically one worker per CPU core – that have memory requirement ranging from 16GB to 32GB per worker. This elastic compute architecture allows for instant start as soon as just a few workers become available and adapts to the instantaneous availability and need for workers.
As semiconductor design grows in size and complexity, the following infrastructure demands should be considered for sign-off.
- Increasing complexity drives the need for more CPU time. Large designs often require tens of thousands of CPU hours
- Large design sizes necessitate persistent, shared, POSIX-compliant storage for data and results
- Workers need to communicate with each other regularly, best served by a high-bandwidth network (10Gbps or more)
Ansys and AWS worked together to evaluate the performance of realistic RedHawk-SC workloads on AWS, and how to optimally configure the infrastructure.
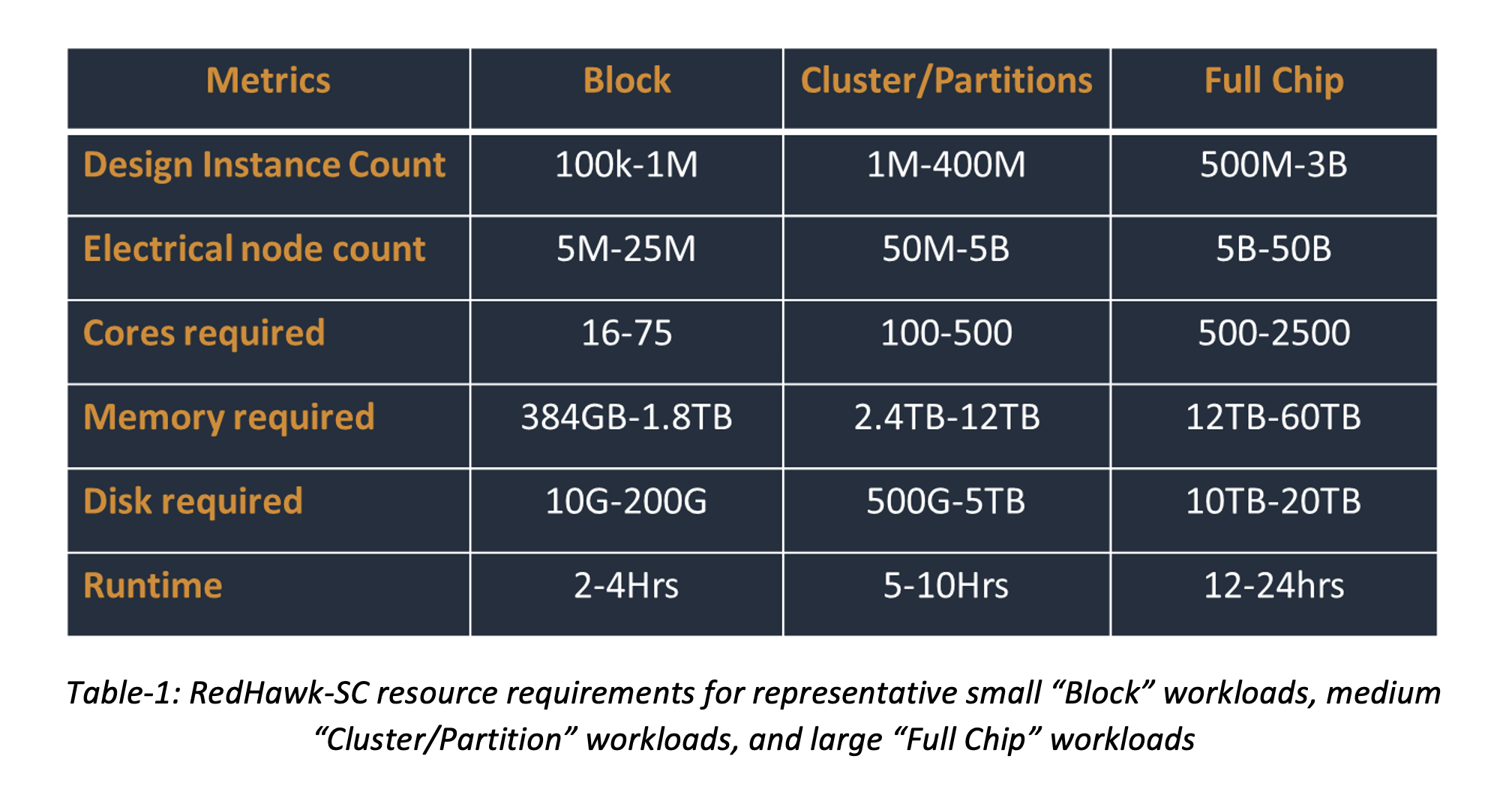
Table-1 lists the resources required to run RedHawk-SC on a variety of workload sizes. The nature of power integrity analysis is inter-related across the whole design, which means that the entire design must be loaded into memory, requiring up to 10TB or more for a complete chip.
For the smaller, block level jobs that complete more quickly, customers can consider leveraging Amazon EC2 Spot Instances to take advantage of unused EC2 capacity in the AWS Cloud at significantly reduced costs. However, longer running full-chip jobs that can take 10-24 hours are not recommended for use with EC2 Spot Instances.
Ansys RedHawk-SC on Scale-Out Computing on AWS
Setting up a distributed compute farm is capital-intensive. For many semiconductor start-ups, committing to such a long-term, depreciating expense doesn’t make sense. The cloud offers a better alternative enabling them to only spend what they need, when they need it. Also, it allows startups to temporarily scale up their resources well beyond what they could afford to by purchasing physical compute without having to worry about provisioning and housing the additional resources. Even for established semiconductor companies, scaling up resources for infrastructure intensive events such as accommodating the sign-off workloads near tape-out can be challenging.
For many semiconductor customers, the barrier to migrating their resource intensive workloads to the cloud is the lack of practical experience with setting up cloud infrastructure. To address this, AWS released the previously mentioned, Scale-Out Computing on AWS (SOCA) solution that provides an easier way for customers with limited experience on the cloud to deploy an EDA ready cloud environment on AWS.
Performance Testing of RedHawk-SC on AWS
The joint testing of RedHawk-SC performance on AWS for this article was done using all Intel-based compute platforms. But AMD-based hardware is equally well supported and Ansys is porting RedHawk-SC and other products to support the Arm64 architecture on Amazon’s Graviton2 chip.

In these tests, RedHawk-SC shows near-linear runtime scaling as the number of CPU cores is increased to over 250 CPU cores. Graph-1 above shows the results for the small, medium, and large workloads described earlier in Table-1. The favorable scaling reflects the efficient distribution technology underlying RedHawk-SC’s SeaScape architecture.
Graph-2 below plots the cost for running these tasks, normalized to the cost of running the job on just 8 CPU cores. In a surprising finding, the cost of running a RedHawk-SC job on AWS actually decreases as you increase the number of workers to the optimum number determined by RedHawk-SC. This contradicts the commonly held assumption that the total cost increases as you enlist more CPU cores.
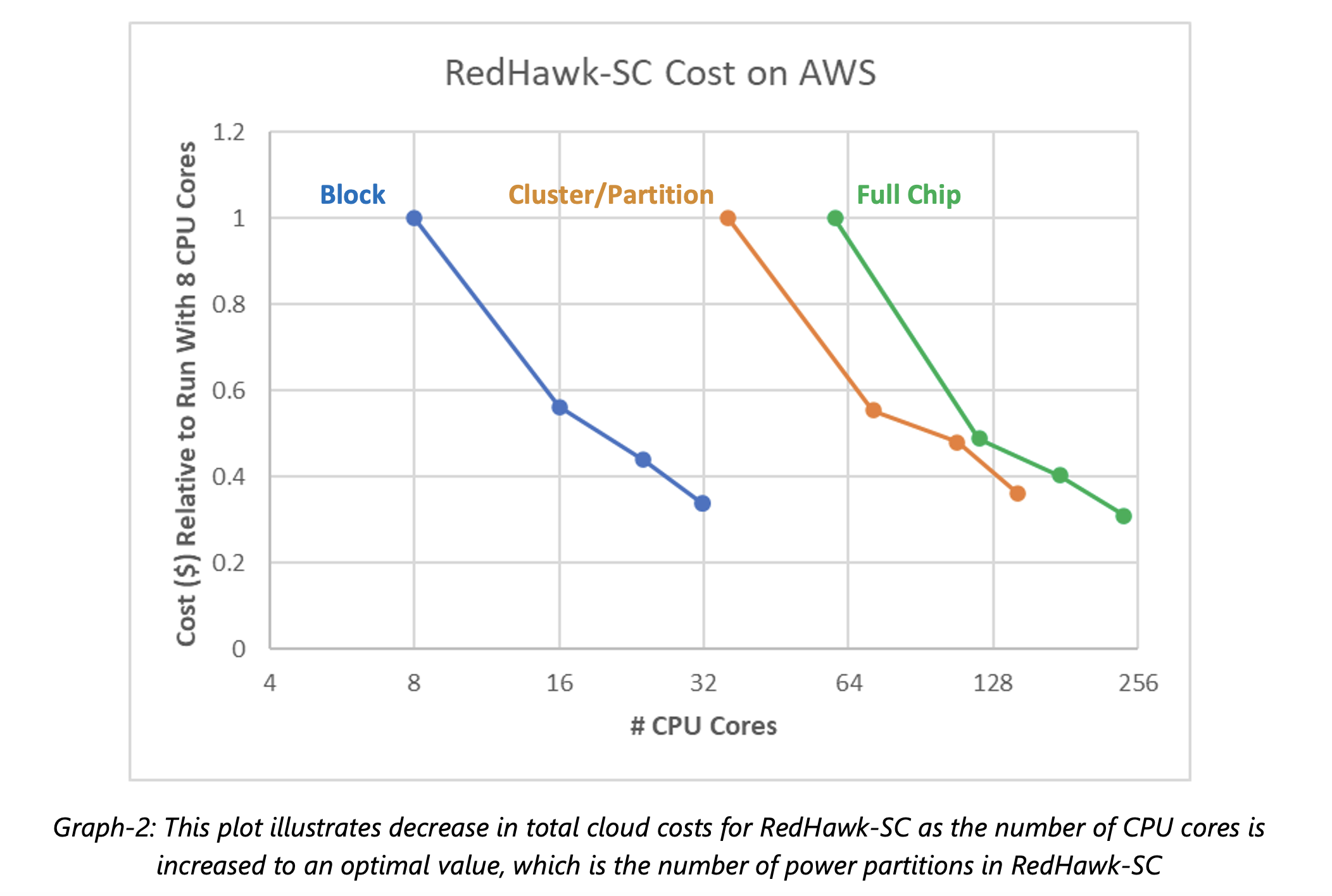
The reason for the decreasing cost curve is due to how efficiently RedHawk-SC runs on the AWS Cloud and the elasticity that AWS provides. As worker jobs finish, the resources are released and the customer is no longer charged for them. This optimal distribution and minimum cost are achieved when the number of CPU cores matches the number of power partitions created by RedHawk-SC. This number of partitions is based on an optimized partitioning strategy for each design and is calculated automatically. It has little significance from a user perspective but does determine the optimal number of CPU cores. Thus, optimal compute utilization minimizes the total runtime and hence the cost of the run.
This result is not obvious and indicates that customers should not try to reduce the CPU core count to save money. In fact, they should actually increase their CPU core count to the optimal value to achieve lower cost and a faster runtime.
Conclusion
Extensive testing of RedHawk-SC on AWS has allowed our joint team to identify an optimized EC2 instance configuration for cloud-based runs. This configuration demonstrates excellent scalability to over 250 CPU cores running on a range of realistic EDA workloads of enormous sizes. The testing further identified the optimal number of CPU cores to minimize the total cost for running RedHawk-SC on AWS. The result is that customers can easily set up their power integrity sign-off analysis jobs on AWS with optimal configurations for both throughput and cost.
For further information contact your Ansys or AWS sales representative. For more information about Ansys visit http://www.ansys.com and for more information about EDA workloads on AWS visit aws.amazon.com/semiconductor