The Internet of Things on AWS – Official Blog
Training the Amazon SageMaker object detection model and running it on AWS IoT Greengrass – Part 3 of 3: Deploying to the edge
Post by Angela Wang and Tanner McRae, Senior Engineers on the AWS Solutions Architecture R&D and Innovation team
This post is the third in a series on how to build and deploy a custom object detection model to the edge using Amazon SageMaker and AWS IoT Greengrass. In the previous 2 parts of the series, we walked you through preparing training data and training a custom object detection model using the built-in SSD algorithm of Amazon SageMaker. You also converted the model output file into a deployable format. In this post, we take the output file and show you how to run the inference on an edge device using AWS IoT Greengrass.
Here’s a reminder of the architecture that you are building as a whole:
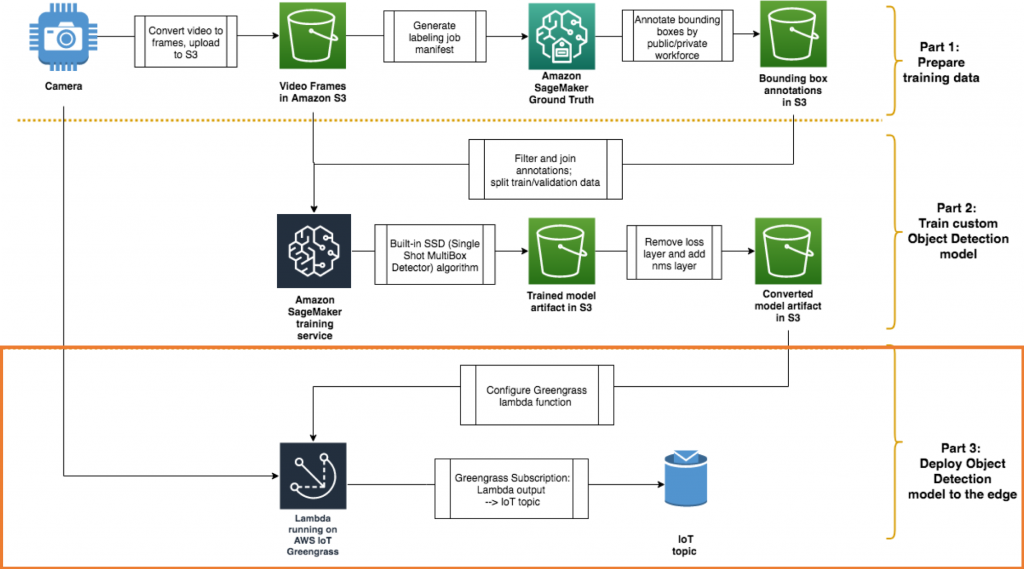
Following the steps in your AWS account
You are welcome to follow the upcoming steps in your own AWS account and on your edge device. Parts 1 and part 2 are not prerequisites for following this section. You can use either a custom model that you have trained or the example model that we provided (under the CDLA Permissive license).
Set up environment and AWS IoT Greengrass Core on an edge device
Before you get started installing AWS IoT Greengrass core on your edge device, make sure you check the hardware and OS requirements. For this post, we used an Amazon EC2 instance with the Ubuntu 18.04 AMI. Although it’s not a real edge device, we often find it helpful to use an EC2 instance as a testing and development environment for AWS IoT use cases.
Device setup
For GPU-enabled devices, make sure you have the GPU drivers, such as CUDA, installed. If your device only has CPUs, you can still run the inference but with slower performance.
Also make sure to install MXNet and OpenCV, which is required to run the model inference code, on your edge device. For guidance, see documentation here.
Next, configure your device, and install the AWS IoT Greengrass core software following the steps in Set up environment and install AWS IoT Greengrass software.
Alternately, launch a test EC2 instance with the preceding setup completed by launching this AWS CloudFormation stack:
![]()
Create an AWS IoT Greengrass group
Now you are ready to create an AWS IoT Greengrass group in the AWS Cloud. There are few different ways to do this and configure AWS Lambda functions to run your model at the edge:
- Using Greengo, an open-source project for defining AWS IoT Greengrass resources in a config file and managing deployment through command line: this is the option detailed in this post.
- Using the AWS IoT Greengrass console: For steps, see Configure AWS IoT Greengrass on AWS IoT.
- Using AWS CloudFormation: For an example setup, see Automating AWS IoT Greengrass Setup With AWS CloudFormation.
In this post, we walk you through setting up this object detection model using Greengo. Our team prefers the Greengo project to manage AWS IoT Greengrass deployment, especially for use in a rapid prototyping and development setting. We recommend using AWS CloudFormation for managing production environments.
On a macOS or Linux computer, use git clone to download the sample code that we provided if you haven’t done so already. The commands shown here have not been tested on Windows.
In the greengrass/ folder, you see a greengo.yaml file, which defines configurations and Lambda functions for an AWS IoT Greengrass group. The top portion of the file defines the name of the AWS IoT Greengrass group and AWS IoT Greengrass cores:
Group:
name: GG_Object_Detection
Cores:
- name: GG_Object_Detection_Core
key_path: ./certs
config_path: ./config
SyncShadow: TrueFor the initial setup of the AWS IoT Greengrass group resources in AWS IoT, run the following command in the folder in which you found greengo.yaml.
pip install greengo
greengo createThis creates all AWS IoT Greengrass group artifacts in AWS and places the certificates and config.json for AWS IoT Greengrass Core in ./certs/ and ./config/.
It also generates a state file in .gg/gg_state.json that references all the right resources during deployment:
Copy the certs and config folder to the edge device (or test EC2 instance) using scp, and then copy them to the /greengrass/certs/ and /greengrass/config/ directories on the device.
sudo cp certs/* /greengrass/certs/
sudo cp config/* /greengrass/config/On your device, also download the root CA certificate compatible with the certificates Greengo generated to the /greengrass/certs/ folder:
cd /greengrass/certs/
sudo wget -O root.ca.pem https://www.symantec.com/content/en/us/enterprise/verisign/roots/VeriSign-Class%203-Public-Primary-Certification-Authority-G5.pemStart AWS IoT Greengrass core
Now you are ready to start the AWS IoT Greengrass core daemon on the edge device.
$ sudo /greengrass/ggc/core/greengrassd start
Setting up greengrass daemon
Validating hardlink/softlink protection
Waiting for up to 1m10s for Daemon to start
...
Greengrass successfully started with PID: 4722Initial AWS IoT Greengrass group deployment
When the AWS IoT Greengrass daemon is up and running, return to where you have downloaded the code repo from GitHub on your laptop or workstation. Then, go to the greengrass/ folder (where greengo.yaml resides) and run the following command:
greengo deployThis deploys the configurations you define in greengo.yaml to the AWS IoT Greengrass core on the edge device. So far, you haven’t defined any Lambda functions yet in the Greengo configuration, so this deployment just initializes the AWS IoT Greengrass core. You add a Lambda function to the AWS IoT Greengrass setup after you do a quick sanity test in the next step.
MXNet inference code
At the end of the last post, you used the following inference code on a Jupyter notebook. In the run_model/ folder, review how you put this into a single Python class MLModel inside model_loader.py:
class MLModel(object):
"""
Loads the pre-trained model, which can be found in /ml/od when running on greengrass core or
from a different path for testing locally.
"""
def __init__(self, param_path, label_names=[], input_shapes=[('data', (1, 3, DEFAULT_INPUT_SHAPE, DEFAULT_INPUT_SHAPE))]):
# use the first GPU device available for inference. If GPU not available, CPU is used
context = get_ctx()[0]
# Load the network parameters from default epoch 0
logging.info('Load network parameters from default epoch 0 with prefix: {}'.format(param_path))
sym, arg_params, aux_params = mx.model.load_checkpoint(param_path, 0)
# Load the network into an MXNet module and bind the corresponding parameters
logging.info('Loading network into mxnet module and binding corresponding parameters: {}'.format(arg_params))
self.mod = mx.mod.Module(symbol=sym, label_names=label_names, context=context)
self.mod.bind(for_training=False, data_shapes=input_shapes)
self.mod.set_params(arg_params, aux_params)
"""
Takes in an image, reshapes it, and runs it through the loaded MXNet graph for inference returning the top label from the softmax
"""
def predict_from_file(self, filepath, reshape=(DEFAULT_INPUT_SHAPE, DEFAULT_INPUT_SHAPE)):
# Switch RGB to BGR format (which ImageNet networks take)
img = cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_BGR2RGB)
if img is None:
return []
# Resize image to fit network input
img = cv2.resize(img, reshape)
img = np.swapaxes(img, 0, 2)
img = np.swapaxes(img, 1, 2)
img = img[np.newaxis, :]
self.mod.forward(Batch([mx.nd.array(img)]))
prob = self.mod.get_outputs()[0].asnumpy()
prob = np.squeeze(prob)
# Grab top result, convert to python list of lists and return
results = [prob[0].tolist()]
return resultsTest inference code on device directly (optional)
Although optional, it’s always helpful to run a quick test on the edge device to verify that the other dependencies (MXNet and others) have been set up properly.
We have written a unit test test_model_loader.py that tests the preceding MLModel class. Review the code in this GitHub repository.
To run the unit test, download the code and machine learning (ML) model artifacts to the edge device and kick off the unit test:
git clone https://github.com/aws-samples/amazon-sagemaker-aws-greengrass-custom-object-detection-model.git
cd amazon-sagemaker-aws-greengrass-custom-object-detection-model/greengrass/run_model/resources/ml/od
wget https://greengrass-object-detection-blog.s3.amazonaws.com/deployable-model/deploy_model_algo_1-0000.params
cd ../../..
python -m unittest test.test_model_loader.TestModelLoaderAfter the unit tests pass, you can now review how this code can be used inside of an AWS IoT Greengrass Lambda function.
Creating your inference pipeline in AWS IoT Greengrass core
Now that you have started AWS IoT Greengrass and tested the inference code on the edge device, you are ready to put it all together: create an AWS IoT Greengrass Lambda function that runs the inference code inside the AWS IoT Greengrass core.
To test the AWS IoT Greengrass Lambda function for inference, create the following pipeline:

- A Lambda function that contains the object detection inference code is running in AWS IoT Greengrass core BlogInfer.
- The AWS IoT topic blog/infer/input provides input to the BlogInfer Lambda function for the location of the image file on the edge device to do inference on.
- The IoT topic blog/infer/output publishes the prediction output of the BlogInfer Lambda function to the AWS IoT message broker in the cloud.
Choose lifecycle configuration for AWS IoT Greengrass Lambda function
There are two types of AWS IoT Greengrass Lambda functions: on-demand or long-lived. For doing ML inference, you must run the model in a long-lived function because loading an ML model into memory can often take 300 ms or longer.
Running ML inference code in a long-lived AWS IoT Greengrass Lambda function allows you to incur the initialization latency only one time. When the AWS IoT Greengrass core starts up, a single container for a long-running Lambda function is created and stays running. Every invocation of the Lambda function reuses the same container and uses the same ML model that has already been loaded into memory.
Create Lambda function code
To turn the preceding inference code into a Lambda function, you created a main.py as the entry point for Lambda function. Because this is a long-lived function, initialize the MLModel object outside of the lambda_handler. Code inside the lambda_handler function gets called each time new input is available for your function to process.
import greengrasssdk
from model_loader import MLModel
import logging
import os
import time
import json
ML_MODEL_BASE_PATH = '/ml/od/'
ML_MODEL_PREFIX = 'deploy_model_algo_1'
# Creating a Greengrass Core sdk client
client = greengrasssdk.client('iot-data')
model = None
# Load the model at startup
def initialize(param_path=os.path.join(ML_MODEL_BASE_PATH, ML_MODEL_PREFIX)):
global model
model = MLModel(param_path)
def lambda_handler(event, context):
"""
Gets called each time the function gets invoked.
"""
if 'filepath' not in event:
logging.info('filepath is not in input event. nothing to do. returning.')
return None
filepath = event['filepath']
logging.info('predicting on image at filepath: {}'.format(filepath))
start = int(round(time.time() * 1000))
prediction = model.predict_from_file(filepath)
end = int(round(time.time() * 1000))
logging.info('Prediction: {} for file: {} in: {}'.format(prediction, filepath, end - start))
response = {
'prediction': prediction,
'timestamp': time.time(),
'filepath': filepath
}
client.publish(topic='blog/infer/output', payload=json.dumps(response))
return response
# If this path exists, then this code is running on the greengrass core and has the ML resources to initialize.
if os.path.exists(ML_MODEL_BASE_PATH):
initialize()
else:
logging.info('{} does not exist and you cannot initialize this Lambda function.'.format(ML_MODEL_BASE_PATH))
Configure ML resource in AWS IoT Greengrass using Greengo
If you followed the step to run the unit test on the edge device, you had to copy the ML model parameter files manually to the edge device. This is not a scalable way of managing the deployment of the ML model artifacts.
What if you regularly retrain your ML model and continue to deploy newer versions of your ML model? What if you have multiple edge devices that all should receive the new ML model? To simplify the process of deploying a new ML model artifact to the edge, AWS IoT Greengrass supports the management of machine learning resources.
When you define an ML resource in AWS IoT Greengrass, you add the resources to an AWS IoT Greengrass group. You define how Lambda functions in the group can access them. As part of AWS IoT Greengrass group deployment, AWS IoT Greengrass downloads the ML artifacts from Amazon S3 and extracts them to directories inside the Lambda runtime namespace.
Then your AWS IoT Greengrass Lambda function can use the locally deployed models to perform inference. When your ML model artifacts have a new version to be deployed, you must redeploy the AWS IoT Greengrass group. The AWS IoT Greengrass service automatically checks if the source file has changed and only download the new version if there is an update.
To define the machine learning resource in your AWS IoT Greengrass group, uncomment this section in your greengo.yaml file. (To use your own model, replace the S3Uri with your own values.)
Resources:
- Name: MyObjectDetectionModel
Id: MyObjectDetectionModel
S3MachineLearningModelResourceData:
DestinationPath: /ml/od/
S3Uri: s3://greengrass-object-detection-blog/deployable-model/deploy_model.tar.gzUse the following command to deploy the configuration change:
greengo update && greengo deployIn the AWS IoT Greengrass console, you should now see an ML resource created. The following screenshot shows the status of the model as Unaffiliated. This is expected, because you haven’t attached it to a Lambda function yet.

To troubleshoot an ML resource deployment, it’s helpful to remember that AWS IoT Greengrass has a containerized architecture. It uses filesystem overlay when it deploys resources such as ML model artifacts.
In the preceding example, even though you configured the ML model artifacts to be extracted to /ml/od/, AWS IoT Greengrass actually downloads it to something like /greengrass/ggc/deployment/mlmodel/<uuid>/. To your AWS IoT Greengrass local Lambda function that you declare to use this artifact, the extracted files appear to be stored in/ml/od/ due to the filesystem overlay.
Configure the Lambda function with Greengo
To configure your Lambda function and give it access to the machine learning resource previously defined, uncomment your greengo.yaml file:
Lambdas:
- name: BlogInfer
handler: main.lambda_handler
package: ./run_model/src
alias: dev
greengrassConfig:
MemorySize: 900000 # Kb
Timeout: 10 # seconds
Pinned: True # True for long-lived functions
Environment:
AccessSysfs: True
ResourceAccessPolicies:
- ResourceId: MyObjectDetectionModel
Permission: 'rw'You didn’t specify the language runtime for the Lambda function. This is because, at the moment, the Greengo project only supports Lambda functions running python2.7.
Also, if your edge device doesn’t already have greengrasssdk installed, you can install greengrasssdk to the ./run_model/src/ directory and have it included in the Lambda deployment package:
cd run_model/src/
pip install greengrasssdk -t .Using GPU-enabled devices
If you are using a CPU-only device, you can skip to the next section.
If you are using an edge device or instance with GPU, you must enable the Lambda function to access the GPU devices, using the local resources feature of AWS IoT Greengrass.
To define the device resource in greengo.yaml, uncomment the section under Resources:
- Name: Nvidia0
Id: Nvidia0
LocalDeviceResourceData:
SourcePath: /dev/nvidia0
GroupOwnerSetting:
AutoAddGroupOwner: True
- Name: Nvidiactl
Id: Nvidiactl
LocalDeviceResourceData:
SourcePath: /dev/nvidiactl
GroupOwnerSetting:
AutoAddGroupOwner: True
- Name: NvidiaUVM
Id: NvidiaUVM
LocalDeviceResourceData:
SourcePath: /dev/nvidia-uvm
GroupOwnerSetting:
AutoAddGroupOwner: True
- Name: NvidiaUVMTools
Id: NvidiaUVMTools
LocalDeviceResourceData:
SourcePath: /dev/nvidia-uvm-tools
GroupOwnerSetting:
AutoAddGroupOwner: TrueTo enable the inference Lambda function to access the device resources, uncomment the following section inside the ResourceAccessPolicies of the Lambda function.
- ResourceId: Nvidia0
Permission: 'rw'
- ResourceId: Nvidiactl
Permission: 'rw'
- ResourceId: NvidiaUVM
Permission: 'rw'
- ResourceId: NvidiaUVMTools
Permission: 'rw'Configure topic subscriptions with Greengo
Lastly, to test invoking the inference Lambda function and receiving its outputs, create subscriptions for inputs and outputs for the inference Lambda function. Uncomment this section in your greengo.yaml file:
Subscriptions:
# Test Subscriptions from the cloud
- Source: cloud
Subject: blog/infer/input
Target: Lambda::BlogInfer
- Source: Lambda::BlogInfer
Subject: blog/infer/output
Target: cloudTo deploy these configurations to AWS IoT Greengrass, run the following command.
greengo update && greengo deployWhen the deployment is finished, you can also review the subscription configuration in the AWS IoT Greengrass console:

And if you check the Lambda function that was deployed, you can see that the ML resource is now affiliated with it:

Test AWS IoT Greengrass Lambda function
Now you can test invoking the Lambda function. Ensure that you download an image (example) to your edge device, so that you can use it to test the inference.
{kind=link}
In the AWS IoT Greengrass console, choose Test, and subscribe to the blog/infer/output topic. Then, publish a message blog/infer/input specifying the path of the image to do inference on the edge device:

You should have gotten back bounding box prediction results.
Take it to real-time video inference
So far, the implementation creates a Lambda function that can do inference on an image file on the edge device. To have it perform real-time inference on a video source, you can extend the architecture. Add another long-lived Lambda function that captures video from a camera, extracts frames from video (similar to what we did in part 1), and passes the reference of the image to the ML inference function:

Resource cleanup
Keep in mind that you are charged for resources running on AWS, so remember to clean up the resources if you have been following along:
- Delete the AWS IoT Greengrass group by running
greengo remove. - Shut down the Amazon SageMaker notebook instance.
- Delete the AWS CloudFormation stack if you used a test EC2 instance to run AWS IoT Greengrass.
- Clean up S3 buckets used.
Conclusion
In this post series, we walked through the process of training and deploying an object detection model to the edge from end to end. We started from capturing training data and shared best practices in selecting training data and getting high-quality labels. We then discussed tips for using the Amazon SageMaker built-in object detection model to train your custom model and convert the output to a deployable format. Lastly, we walked through setting up the edge device and using AWS IoT Greengrass to simplify code deployment to the edge and sending the prediction output to the cloud.
We see so much potential for running object detection models at the edge to improve processes in manufacturing, supply chain, and retail. We are excited to see what you build with this powerful combination of ML and IoT.
You can find all the code that we covered at this GitHub repository.
Other posts in this three-part series: