Artificial Intelligence

Use the Amazon SageMaker and Salesforce Data Cloud integration to power your Salesforce apps with AI/ML
This post is co-authored by Daryl Martis, Director of Product, Salesforce Einstein AI. This is the second post in a series discussing the integration of Salesforce Data Cloud and Amazon SageMaker. In Part 1, we show how the Salesforce Data Cloud and Einstein Studio integration with SageMaker allows businesses to access their Salesforce data securely […]

Bring your own AI using Amazon SageMaker with Salesforce Data Cloud
This post is co-authored by Daryl Martis, Director of Product, Salesforce Einstein AI. We’re excited to announce Amazon SageMaker and Salesforce Data Cloud integration. With this capability, businesses can access their Salesforce data securely with a zero-copy approach using SageMaker and use SageMaker tools to build, train, and deploy AI models. The inference endpoints are […]

Enhancing AWS intelligent document processing with generative AI
Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. AWS intelligent document processing (IDP), with AI services such as Amazon Textract, allows you to take advantage of industry-leading machine learning (ML) technology to quickly and […]
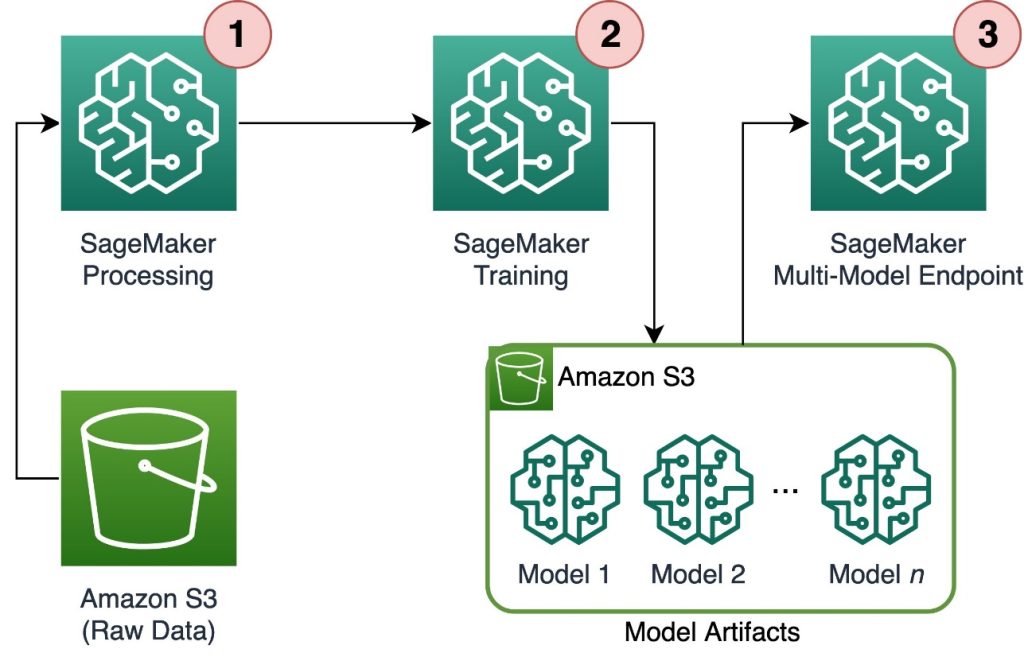
Scale training and inference of thousands of ML models with Amazon SageMaker
Training and serving thousands of models requires a robust and scalable infrastructure, which is where Amazon SageMaker can help. SageMaker is a fully managed platform that enables developers and data scientists to build, train, and deploy ML models quickly, while also offering the cost-saving benefits of using the AWS Cloud infrastructure. In this post, we explore how you can use SageMaker features, including Amazon SageMaker Processing, SageMaker training jobs, and SageMaker multi-model endpoints (MMEs), to train and serve thousands of models in a cost-effective way. To get started with the described solution, you can refer to the accompanying notebook on GitHub.

Accelerate business outcomes with 70% performance improvements to data processing, training, and inference with Amazon SageMaker Canvas
Amazon SageMaker Canvas is a visual interface that enables business analysts to generate accurate machine learning (ML) predictions on their own, without requiring any ML experience or having to write a single line of code. SageMaker Canvas’s intuitive user interface lets business analysts browse and access disparate data sources in the cloud or on premises, […]

Build and train computer vision models to detect car positions in images using Amazon SageMaker and Amazon Rekognition
Computer vision (CV) is one of the most common applications of machine learning (ML) and deep learning. Use cases range from self-driving cars, content moderation on social media platforms, cancer detection, and automated defect detection. Amazon Rekognition is a fully managed service that can perform CV tasks like object detection, video segment detection, content moderation, […]
Build a personalized avatar with generative AI using Amazon SageMaker
Generative AI has become a common tool for enhancing and accelerating the creative process across various industries, including entertainment, advertising, and graphic design. It enables more personalized experiences for audiences and improves the overall quality of the final products. One significant benefit of generative AI is creating unique and personalized experiences for users. For example, […]

SageMaker Distribution is now available on Amazon SageMaker Studio
SageMaker Distribution is a pre-built Docker image containing many popular packages for machine learning (ML), data science, and data visualization. This includes deep learning frameworks like PyTorch, TensorFlow, and Keras; popular Python packages like NumPy, scikit-learn, and pandas; and IDEs like JupyterLab. In addition to this, SageMaker Distribution supports conda, micromamba, and pip as Python […]

Automate caption creation and search for images at enterprise scale using generative AI and Amazon Kendra
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines search for your websites and applications so your employees and customers can easily find the content they are looking for, even when it’s scattered across multiple locations and content repositories within your organization. Amazon Kendra supports a variety of document […]

Exploring summarization options for Healthcare with Amazon SageMaker
In today’s rapidly evolving healthcare landscape, doctors are faced with vast amounts of clinical data from various sources, such as caregiver notes, electronic health records, and imaging reports. This wealth of information, while essential for patient care, can also be overwhelming and time-consuming for medical professionals to sift through and analyze. Efficiently summarizing and extracting […]