Artificial Intelligence
Use AutoGluon-Tabular in AWS Marketplace
AutoGluon-Tabular is an open-source AutoML framework that requires only a single line of Python to train highly accurate machine learning (ML) models on an unprocessed tabular dataset. In this post, we walk you through a way of using AutoGluon-Tabular as a code-free AWS Marketplace product. We use this process to train and deploy a highly accurate ML model for a tabular prediction task.
Overview of AutoGluon-Tabular
Tabular data prediction, which includes both classification and regression, is the most prevalent class of prediction problems in business. If you’ve worked on this type of prediction problem before, you know that it’s a vast field with extreme diversity of data. Businesses want to build predictive models on top of data obtained through a wide array of sources, such as purchase histories, insurance claims, medical reports, and sensor readings streamed from IoT devices. This diversity has resulted in an enormous variety of modeling techniques.
Classical approaches have typically been dominated by domain expertise and careful, time-consuming feature engineering. However, if you follow data science competitions like those hosted by Kaggle, you may have noticed a transition happening. Lately, the most competitive approaches haven’t been encapsulated by domain experts with careful feature engineering, but instead by ML architecture experts, with large ensembles of models. Over time, the ML community has discovered that models that are worse in isolation are often superior in combination. This idea is sometimes known in other contexts as the diversity prediction theorem, or wisdom of the crowd. This effect is typically greatest when individual models are diverse and have errors in different ways.
This idea is at the core of AutoGluon-Tabular. AutoGluon-Tabular is designed to be straightforward, robust, efficient, accurate, and fault tolerant, returning to the latest checkpoint in the event of a failure. As a library, all the complexity has been abstracted away so that results can often be achieved with only three lines of code.
We’ve taken this one step further and launched AutoGluon-Tabular in the AWS Marketplace as one way of using AutoGluon-Tabular on AWS. It’s possible to build world-class models without a single line of code! In addition, you can take advantage of powerful Amazon SageMaker features. Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to prepare build, train, and deploy machine learning models quickly. It makes it easy to deploy your trained model to production with a single click.
Solution overview
The following sections step you through how to use AutoGluon-Tabular in AWS Marketplace on the SageMaker console. If you want to use AutoGluon-Tabular in the AWS Marketplace in SageMaker notebooks, you can refer the following sample notebook.
We walk through the following steps:
- Subscribe to AutoGluon-Tabular in AWS Marketplace.
- Create a SageMaker training job.
- Create a model package.
- Deploy an endpoint.
- Create a SageMaker batch transform job.
Subscribe to AutoGluon-Tabular in AWS Marketplace
The first step is to subscribe to AutoGluon-Tabular in AWS Marketplace.
- Navigate to AutoGluon-Tabular in AWS Marketplace.

- Choose Continue to Subscribe.

- Choose Accept Offer.
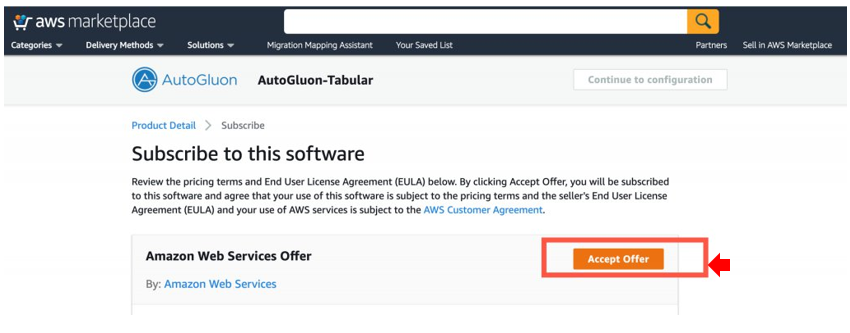
- Choose Continue to configuration.
- For Software Version, choose version 3.5.
- For Region, choose a Region.
- Choose View in Amazon SageMaker.
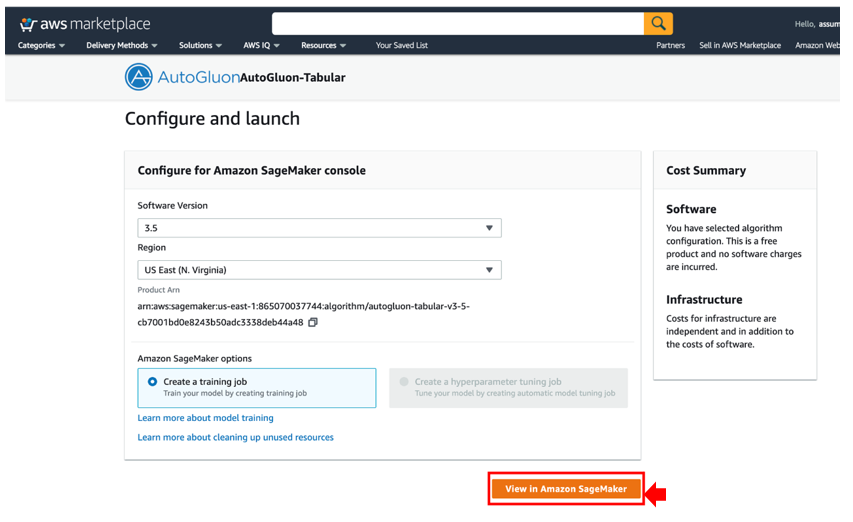
You’re redirected to the SageMaker console.
Create a SageMaker training job
To create a training job, complete the following steps:
- On the SageMaker console, create a new training job.
- For Job name, enter a name (for this post,
autogluon-demo). - For IAM role, choose an AWS Identity and Access Management (IAM) role.
- For Instance type, choose your instance size.
- For Additional storage volume per instance, enter your volume size.
We recommend using the m5 instance type and a volume size of more than 30 GB.

- In the Hyperparameters section, you can pass
argsfor AutoGluon-Tabular.
The minimum requirement is to set the name of the label column to predict.

- In the Input data configuration section, for S3 location, enter the Amazon S3 location of your CSV file for training.
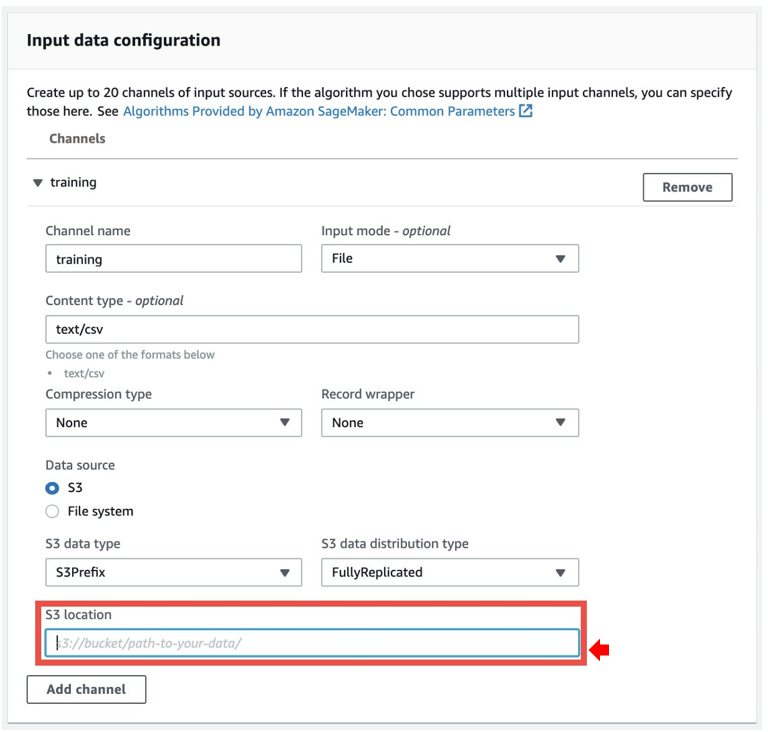
- Optionally, specify the Amazon S3 location of your testing file.
- Specify the Amazon S3 location for your output data.
- Choose Create training job.
Create a model package
When training is complete, you can create a model package.
- On the Training jobs page on the SageMaker console, select your training job.
- On the Actions menu, choose Create model package.

- For Model package name, enter a name (for this post,
autogluon-demo). - Select Provide the algorithm used for training and its model artifacts.

- Choose Next.
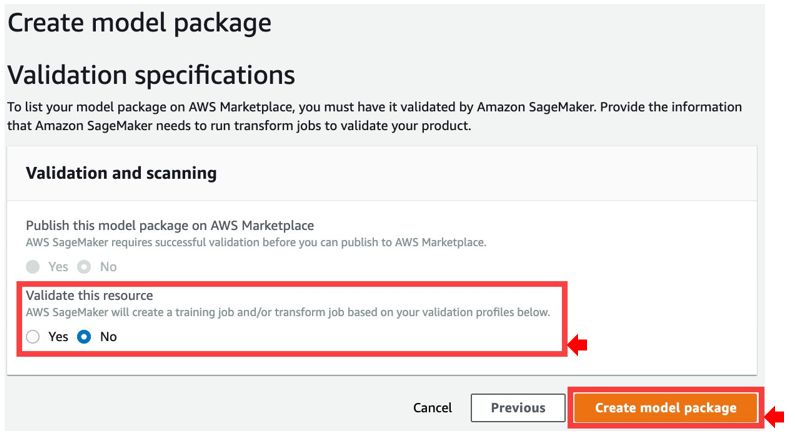
- For Validate this resource, select No.
- Choose Create model package.
Deploy an endpoint
To deploy your endpoint, complete the following steps:
- On the SageMaker console, choose the model package you created.
- Choose Create endpoint.

- Choose Next.
- For Model name, enter a name (for this post,
autogluon-demo). - For Container input options, select Use a model package subscription from AWS Marketplace.

- On the next page, for Endpoint name, enter a name (for example,
autogluon-demo). - Select the instance type.
- Choose Create endpoint configuration, then choose Submit.

Create a SageMaker batch transform job
To create a batch transform job, complete the following steps:
- On the SageMaker console, navigate to the model you created.
- Choose Create batch transform job.

- For Job name, enter a name (for this post,
autogluon-demo). - For Instance type, choose an instance type.

- In the Input data configuration section, for Split type, choose Line.
- For Content type, enter
text/csv. - For S3 location, enter the S3 path of your CSV file.

- For S3 output path, enter the S3 path for your output data.
- Choose Create job.

Clean up resources
Finally, delete the endpoint when you’re done so you don’t incur further charges.
Conclusion
In this post, we walked you through how to train ML models and make predictions using AutoGluon-Tabular in AWS Marketplace via the SageMaker console. You can use this code-free solution to use the power of ML without any prior programming or data science expertise. Try it out and let us know how it goes in the comments!
About the Authors
 Yohei Nakayama is a Deep Learning Architect at the Amazon ML Solutions Lab. He works with customers across different verticals to accelerate their use of artificial intelligence and AWS Cloud services to solve their business challenges. He is interested in applying ML/AI technologies to the space industry.
Yohei Nakayama is a Deep Learning Architect at the Amazon ML Solutions Lab. He works with customers across different verticals to accelerate their use of artificial intelligence and AWS Cloud services to solve their business challenges. He is interested in applying ML/AI technologies to the space industry.
 Austin Welch is a Data Scientist at the Amazon ML Solutions Lab, where he helps AWS customers across different industries accelerate their AI and cloud adoption.
Austin Welch is a Data Scientist at the Amazon ML Solutions Lab, where he helps AWS customers across different industries accelerate their AI and cloud adoption.
 Tatsuya Arai Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon ML Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.
Tatsuya Arai Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon ML Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.