AWS for M&E Blog
Choosing the right Amazon EC2 instance types for rendering with Thinkbox Deadline (Part 1)
Thinkbox Deadline 10 introduced the AWS Portal Panel, which helps you scale up your render farm with Amazon EC2 Spot Instances. You can get started with AWS Portal by following the instructions at AWS Portal Setup.
After you’ve launched your infrastructure, you’re ready to start your Spot Fleet requests. You’ve chosen the software to render with, and now it’s time to choose an instance type.
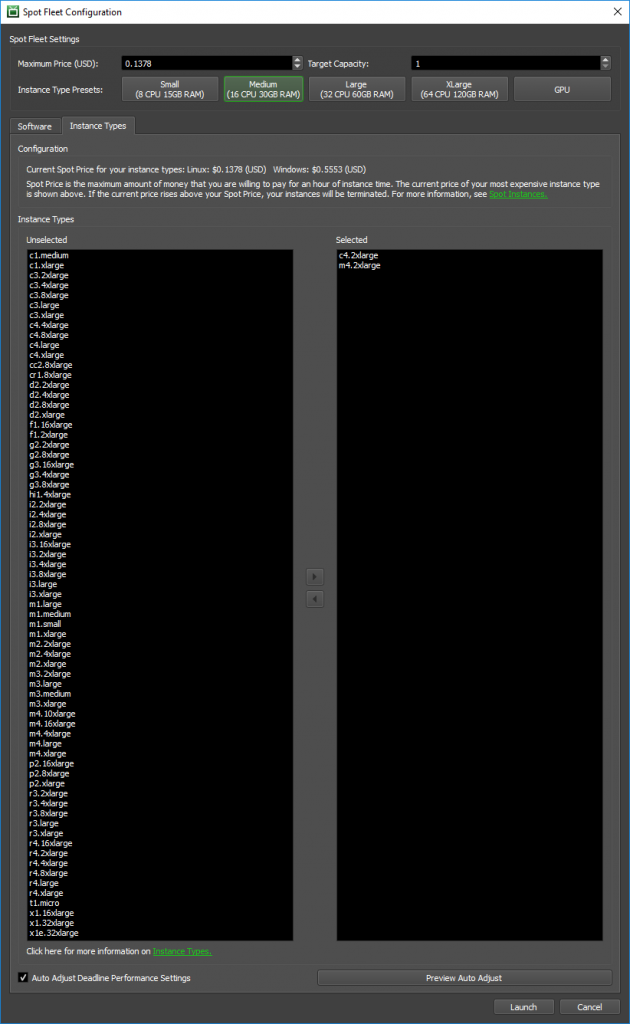
Golly! That’s a lot of options. Where do you even start? In this post, I give you tips to make your instance decisions.
Anatomy of an instance type name
All instance types names consist of a letter, number, and size. The letter at the beginning of the name is what the instance is suited for, and the available types are as follows:
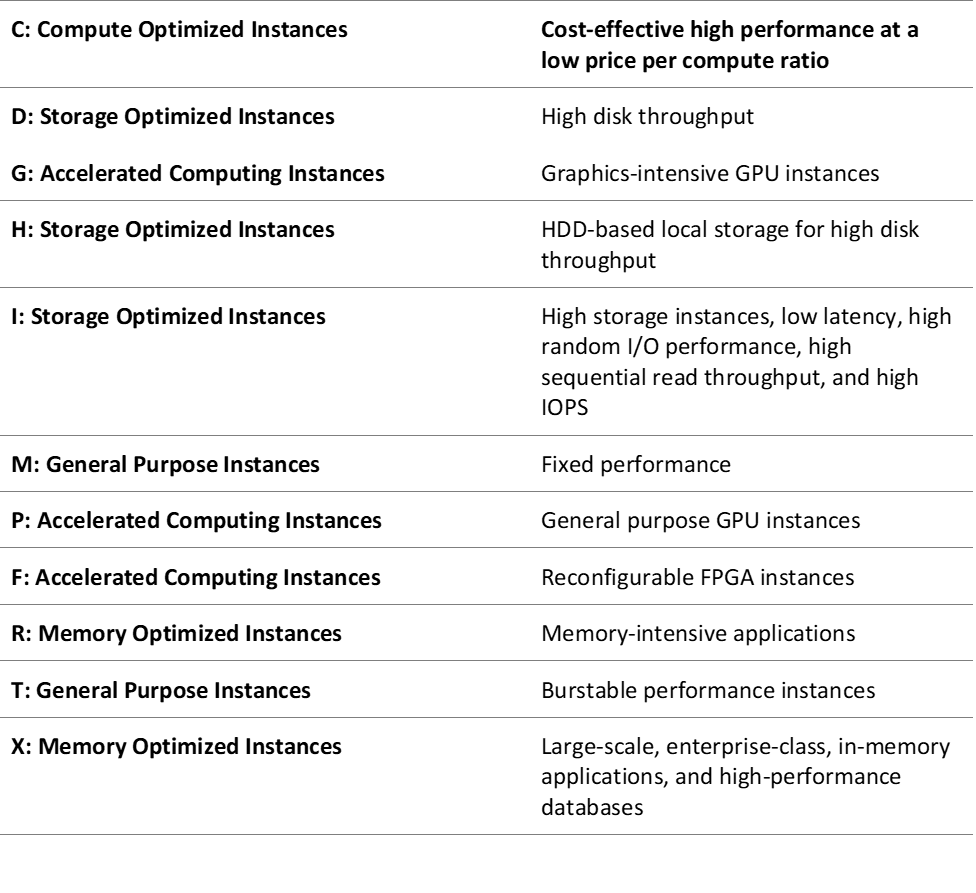
The number is the generation. The higher the number, the newer the generation. For example, C5 instances are the fifth generation of the Compute optimized instances and M5 instances are the fifth generation of the General purpose instances.
The size is how powerful the instance type is, and can be one of the following:
- nano
- micro
- small
- medium
- large
- xlarge
- #xlarge (where # is a number)
Each size has twice the vCPUs and RAM of the size before it. For example:
- c4.large has 2 vCPU and 3.75 GB of RAM
- c4.xlarge has 4 vCPU and 7.5 GB of RAM
- c4.2xlarge has 8 vCPU and 15 GB of RAM
- and so on
Not all instance types include all sizes. For example, T2 instances go from nano to 2xlarge but C4 instances only go from large to 8xlarge.
For more information about the various instance types that are available, see Amazon EC2 Instance Types.
What’s a vCPU?
At this point, you may be asking yourself what a vCPU is. Each vCPU is a hyperthread of an Intel Xeon core, except for T2 instances and M3.medium instance types. As mentioned earlier, T2 instances are burstable performance instances that provide a baseline level of CPU performance with the ability to burst above the baseline. These are more appropriate for applications that don’t use the full CPU often, but occasionally need a burst of performance. Recommendations on choosing the appropriate instance type are covered later.
Presets
A great place to start in Thinkbox Deadline is to select a preset. At the top of the Spot Fleet Configuration window, there are five buttons with five different presets from which to choose.

When you press one of the buttons, all of the instances that meet the specs of the preset are automatically added to your selected instance types.
- Small — All available instance types that have 8 vCPUs and at least 15 GB of RAM.
- Medium — All available instance types that have 16 vCPUs and at least 30 GB of RAM.
- Large — All available instance types that have 32 vCPUs and at least 60 GB of RAM.
- XLarge — All available instance types that have 64 vCPUs and at least 120 GB of RAM.
- GPU — All available GPU instances types.
How to pick the right instance type
If you are using a CPU biased renderer for Autodesk Maya, such as Arnold, or Chaos Group V-Ray, then C4 instances are a great choice because they have the lowest price/compute of any instance type. The minimum requirement for Maya is 8 GB of RAM, with 16 GB being recommended. As a result, the minimum C4 instance type you should use is c4.2xlarge, which has 8 vCPUs and 15 GB of RAM.
When rendering with AWS Portal in Deadline 10, you aren’t using the user interface component of Maya, so 15 GB of RAM should be fine. To be safe, you could go with c4.4xlarge, which features 16 vCPUs and 30 GB of RAM, giving you the benefit of having twice the vCPUs! At the time of publication, c4.4xlarge is a little over twice the price* of c4.2xlarge, so that should be considered as well.
Another instance type to consider in this situation is M4, which is made for General purpose. These have a more balanced RAM-to-vCPU ratio, so you can get a cheaper minimum RAM option in exchange for longer render times. The minimum recommended M4 instance would be m4.large, which has 2 vCPUs and 8 GB of RAM. To match the recommended specs for Maya, go with m4.xlarge, which has 4 vCPUs and 16 GB of RAM.
Now consider the cost difference. For the minimum RAM requirement for Maya, you can go with the following:
- m4.large, which as of publication is $0.0275 per hour*
- c4.2xlarge, which as of publication is $0.0619 per hour*
With M4 instances, you can meet the minimum required specs for 44% of the price of the C4 instances. So why would you want to go for c4.2xlarge? Keep in mind that c4.2xlarge has four times the vCPUs, which typically means faster rendering times, which could lead to a lower cost overall.
For example, a render that would take three hours on m4.large will cost you $0.0825. If that render takes an hour on c4.2xlarge because of the increased number of vCPUs, it will only cost you $0.0619. The longer your renders take, the more apparent this will be. If your renders are relatively quick though, the m4.large could be a better deal.
* These prices are in USD and are the On-Demand Instance price in the US East (Ohio) region. Spot prices are set by Amazon EC2 and fluctuate periodically depending on the supply of and demand for Spot Instance capacity. Spot Instances are available at a discount of up to 90% compared to On-Demand Instance pricing. To compare the current Spot prices against standard On-Demand Instance rates, see the Spot Bid Advisor and review the On-Demand prices.
Choosing multiple instance types
Because AWS Portal uses Spot Instances, you don’t have to only choose one instance type. If you only want to pay m4.large prices, you can select m4.large and c4.2xlarge and use the m4.large Spot price as your maximum price.

If the Spot price of the c4.2xlarge instance type falls below your maximum, the Spot Fleet request could spin up a c4.2xlarge instance and you’d pay m4.large prices for c4.2xlarge performance. However, just because the c4.2xlarge price drops below your maximum, doesn’t guarantee one will spin up instead of m4.large.
Another thing to keep in mind is that there is a risk to adding more expensive instance types with lower instance prices. If the Spot price for the more expensive instance types goes above your maximum price, then those instances could be terminated in the middle of rendering. The good news is that if this happens, Deadline recovers so that new instances can restart the task when they start up again.
What about GPUs?
With AWS Portal and Spot Instances, you also have access to GPU instances, which allow you to use GPU renderers like Redshift without the expense of having to pay for costly GPUs yourself. The G3 instances type is recommended for rendering, and they feature NVIDIA ® Tesla M60 GPUs, each with 2048 CUDA ® cores and 8 GB of GPU memory.
The following G3 instance types are currently available:
- g3.4xlarge has 1 GPU with 8 GB of GPU RAM, and 16 vCPUs with 122 GB of RAM
- g3.8xlarge has 2 GPUs with 16 GB of GPU RAM, and 32 vCPUs with 244 GB of RAM
- g3.16xlarge has 4 GPUs with 32 GB of GPU RAM, and 64 vCPUs with 488 GB of RAM
There are also the P3 instance types, which are designed for general-purpose GPU computing, such as machine learning and computational fluid dynamics. They feature NVIDIA ® Tesla V100 GPUs, each with 5,120 CUDA cores and 640 Tensor Cores.
The following P3 instance types are currently available:
- p3.xlarge has 1 GPU with 16 GiB of GPU RAM, and 8 vCPUs with 61 GiB of RAM
- p3.8xlarge has 4 GPUs with 64 GiB of GPU RAM, and 32 vCPUs with 244 GiB of RAM
- p3.16xlarge has 8 GPUs with 128 GiB of GPU RAM, and 64 vCPUs with 488 GiB of RAM
The P3 instance types have CUDA Compute Capability 7.0 and G3 instance types have CUDA Compute Capability 5.2. The latter is recommended for Redshift rendering.
Conclusion
As you can see, there are many things to consider when choosing an instance type, including price and the minimum or recommended specs of the applications to use with AWS Portal.
A good approach is to determine how you want to meet or exceed the minimum required specs, and review all of the instance types that fit that criteria. While I focused on Maya for this post, the same approach can be applied to other content creation software and renderers.