AWS for M&E Blog
Iterations of a live workflow from space – SMPTE 2019
In 2017 the world watched as we made history delivering the first live 4K broadcast from space with the help of our partners at NASA. That event spurred many discussions, presentations and inspired others to take a look at how they can deliver 4K content with a hybrid cloud approach. When I say “hybrid cloud” I mean a workflow that utilizes both on-premise hardware as well as cloud tools to encode, package and securely deliver content to viewers around the world. In that time, as new services have been made available on AWS we have worked to improve this solution and migrate more of the work to the cloud. In this post, I will cover our first design for the NASA 4K broadcast and how we updated it for today’s revisit with the International Space Station.
The first 4K broadcast was a game changer from numerous angles. It was the first time 4K content was transmitted down and broadcast live to an audience. And it was the first time we used a 4K hybrid workflow to accommodate the packaging needs in that manner. As you take a look at the 2017 workflow you see we utilized two GPU Elemental Live encoders at the venue to generate our SD-4K ABR stack and delivered that HLS stream to our cloud packager via two very large ISP drops at the venue.
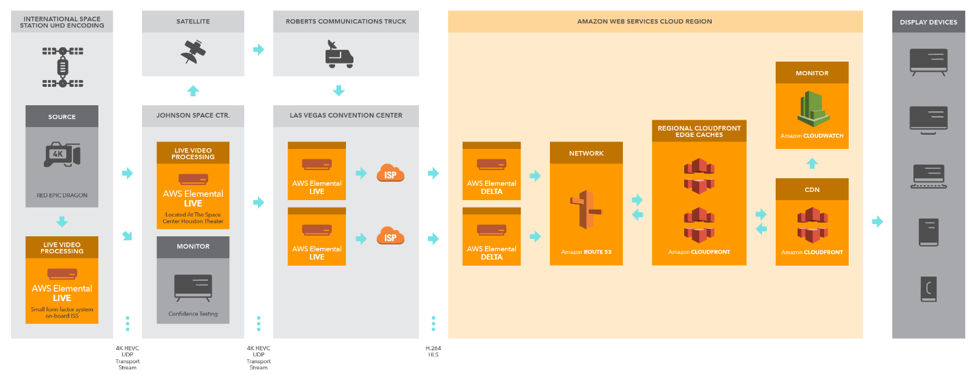
Once in the AWS Elemental Cloud Delta packager, I was able to ensure our origin server would scale to the demand on the fly and without the restriction of venue internet limitations or traditional hardware limitations. We also had redundancy built in, thanks to the AWS cloud.
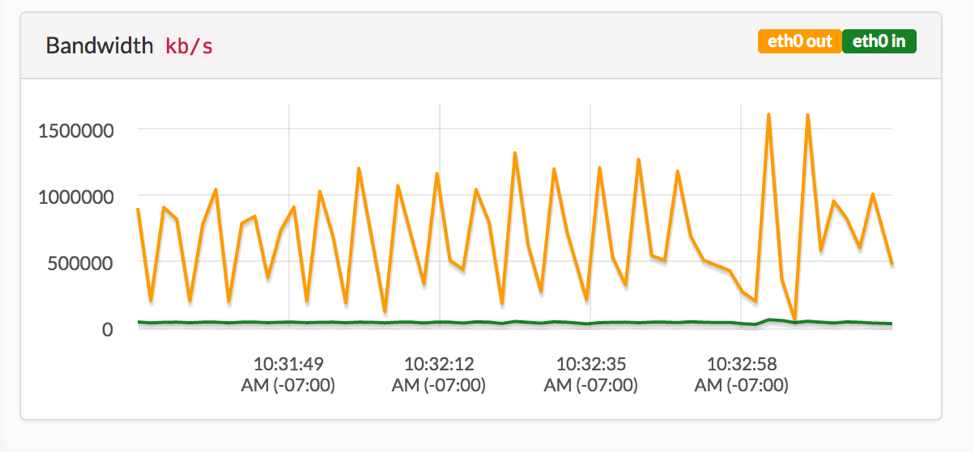
As you can see from the chart, the cloud packager ended up exceeding 1.5Gbps due to viewership demand. This far exceeded our expectations in viewership because it shows that a request was being made from every CloudFront region around the world. If we were relying on hardware origin servers at an event venue, we would not have been successful due to the demand. The cloud service saved the day and provided a flawless delivery of our live show.
Updates for 2019
Based off of that exciting event, we have continued to work with our great partners at NASA to bring other events to life. The event today, at the SMPTE 2019 conference, is another example of iterations in this workflow and how we are continuing to improve the process of content delivery.
The biggest change from 2017 to today is that 90% of the entire workflow is now in the AWS cloud with AWS Elemental Media Services!
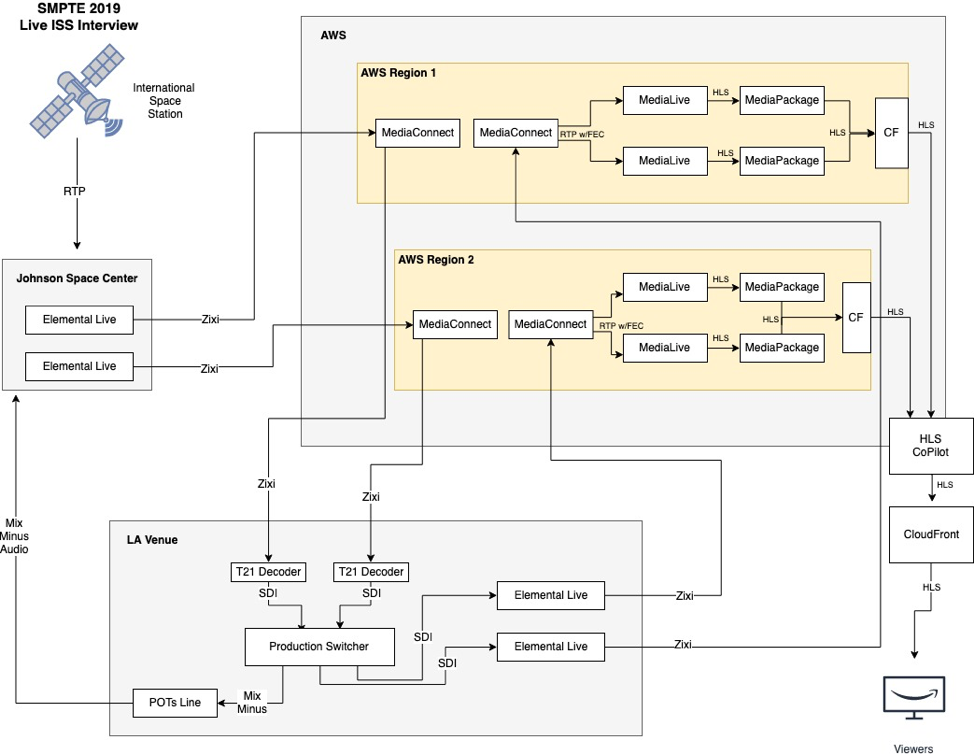
Let me walk you through what we setup for this event. First, we were able to remove the need for satellite transmission from Johnson Space Center (JSC) to our venue thanks the MediaConnect. MediaConnect allows us to send a lower latency, mezzanine quality Zixi stream JSC to the AWS cloud, then transit it to us in LA at the venue, reliably and securely. At the event venue, I am able to pull the Zixi stream and decode it with the T21 decoder and insert the baseband audio and video into the production plant.
Once we produce the show, the baseband output of the switcher is sent to our two onsite AWS Elemental Live encoders where we send another mezzanine quality Zixi stream to our second MediaConnect deployments in our respective regions. Now, if you did not notice, there are regions we’re working in within the AWS cloud. This ensures delivery of my event in the event that we were to lose connectivity to one region. To learn more about AWS regions and how they are setup click here.
With my program now streaming back into AWS, I am able to take the MediaConnect outputs and send the stream via RTP with FEC into my AWS Elemental MediaLive transcoder where I generate my ABR stack. By using MediaLive, I’m able to offload the resource demand for on-site encoding to the AWS cloud. This reduces my venue cost because I can order less bandwidth and use smaller encoders onsite. Once my ABR stack is generated in MediaLive, we send that (via HLS) to AWS Elemental MediaPackage. MediaPackage is one of two origin services and the just in time packager in the Media Services suite. If you notice in the diagram there are two MediaLive and MediaPackage deployments in each region. That’s because I chose to use the Standard pipeline setup which means that multiple instances of my MediaLive and MediaPackage deployments reside in different Availability Zones within that region, providing redundancy within the region itself. If you want to reduce cost and the risk is acceptable to you, you can choose to operate MediaLive with a single-pipeline workflow as well.
After MediaPackage, we route the HLS stream to be pulled through CloudFront and into our new tool that we are still developing that allows us to monitor the health of and seamlessly switch between our multi-region HLS stream sources. This means we can switch between which regional stream is sent to the player with minimal interruption if there is a problem. After that, the stream is routed through CloudFront and delivered to the player.
By offloading most of our workflow into the AWS cloud, we’re able to reduce my operational cost, increase the redundancy and improve the viewing experience for our customers. All wins at the end of the day for another successful show. You too can utilize these tools for your next live event with this easy to create and tear down (when you are complete) architecture!