Microsoft Workloads on AWS
Modernizing legacy .NET applications: DraftKings’ principles for success
This is a guest post from David Musicant, Director of Architecture from DraftKings. DraftKings Inc. is a digital sports entertainment and gaming company created to fuel the competitive spirits of sports fans with products that range across daily fantasy, regulated gaming, and digital media.
A little over a year ago, we laid out a path to lower costs, increase scalability, application flexibility and improve developer efficiency. We identified an opportunity to get started on this path by modernizing our legacy .NET applications, with step one being a conversion to .NET Core.
When DraftKings merged with SB Tech, we became the only vertically-integrated pure-play sports betting and online gaming company. Based in the United States, DraftKings needed to integrate our software, platform, and people. We knew it required more than just code changes to turn this into an enterprise solution. If we tried to tackle all issues at once, we’d fail and stunt the engineering organization’s growth. After a deeper dive, we learned we would have to focus significantly on improving not only the technology, but our developer experience to achieve our objectives.
This post outlines the best practices that DraftKings accumulated while we modernized hundreds of our applications from .NET Framework to .NET Core on AWS.
Pre-migration research
We quickly identified our starting point as the core technologies underlying all of our micro-services: .NET Framework and NServiceKit. With our target identified, we started doing some research on what had been done throughout the industry by reading articles and speaking with engineers who had converted some code. This got us excited — almost every article on migrating to .NET Core indicated it was relatively straightforward and the engineers indicated converting their .NET Framework code had been simple as well. There were a few deprecated packages but otherwise, transitioning a service would take an hour or so.
In a large engineering organization, however, you end up with hundreds of services with custom code, varying patterns and libraries. This happens when you need to move fast and have self-enabled autonomous teams. That autonomy is powerful, helping to drive fast delivery and expansion, but it has the cost of complexity and a lack of standards and commonality. Adding to that complexity, our teams have packed roadmaps. Our products evolve very quickly and our engineers do not have much time to take on large technology shifts. We also operate in a highly regulated environment. We cannot simply update code and deploy it. We have to go through a rigorous testing process and in some cases get approvals for releases from regulators. These challenges required a more intentional plan and a step-by-step approach to a technology upgrade.
Best practices for large-scale modernization
1. Get buy-in from stakeholders and leadership
For an initiative to succeed, support from other stakeholders in the organization is mission critical, given the dependencies and impact on the business or technology investments. The project should seek the support of leadership by showing a strong business case. Other teams across the engineering organization will also want to know the benefits, whether technological or business related, and how they could contribute.
At a high level, the steps and tools we used to put together the business case were as follows:
- Determine the impacted areas of the business (e.g. developer pipeline, production scale, etc)
- Collect the current costs of the impacted areas (AWS has some great tools in the console for helping determine the costs of our services)
- Determine the effort for “X” people to implement each project and time to realize savings
- Break out hard savings (direct savings such as cheaper licenses) vs soft savings (non-direct monetary savings such as dev efficiency gains)
- Chart across time to show the path to break even
For DraftKings, .NET Core had technological benefits such as the ability for better efficiency with “async-all-the-way-down.” For the business, it was an important and necessary step towards other initiatives that would save us a significant amount of hardware and compute in the cloud. It enabled a move to Linux, containers and later Kubernetes. We then utilized metrics such as hardware utilization, time and effort to scale and time spent delivering code to production, to build those cases showing gains in developer efficiency, cloud cost savings, better flexibility and scalability.
2. Update with a purpose
Refactors can frequently become massive projects that grow in scope with every piece of code touched. As we started down the path towards .NET Core, we saw numerous flaws we wanted to fix in our internal SDK and framework code. For example, the way we handled dependency injection did not use the newer .NET standard IServiceProvider/IServiceCollection. The temptation to fix this and many other areas of technical debt was strong.
An engineer’s first thought is usually, “as long as I’m in here, I might as well fix this to do it the right way.” However, all that does is make a three-month project take a year and add additional moving parts that make regression testing more difficult. The end result is that it’s impossible to verify the application has the same expected behavior as the existing implementation. We instead used an Epics approach, which is the agile methodology of breaking a large task into smaller functions, and our backlog to help keep the migration scope under control.
a. Legacy Patterns vs Modern Approach
There were some cases where it was not just our outdated external dependencies that gave us pause, but the capabilities we’d built on top of them in our SDK and micro-services. This included things like circuit breaking, database access and cloud communication. We had to change the underlying implementation in many of these cases which actually led to some nicer interfaces and patterns. However, if we’d exposed these nicer patterns in our SDK, the impact on our micro-services would be immense. We made the compromise to wrap these in legacy interfaces in many cases to ease the transition to .NET Core for our engineers. For example, we switched from our legacy Http library built on top of HttpWebRequest to one built on top of the newer HttpClient but kept our old interfaces as well.
3. Modernize incrementally
Our end goal for the team was to create automation that could do 90% of the work for converting a micro-service to .NET Core. However, if we’d started there, we would have created a script that frustrated engineers and didn’t handle the majority of the code. This is due in part to our teams being very autonomous with a high level of variation in how they implement their micro-services. It was important to first prove out and fine tune the conversion mechanisms manually, multiple times to cover the majority of cases before building automation.
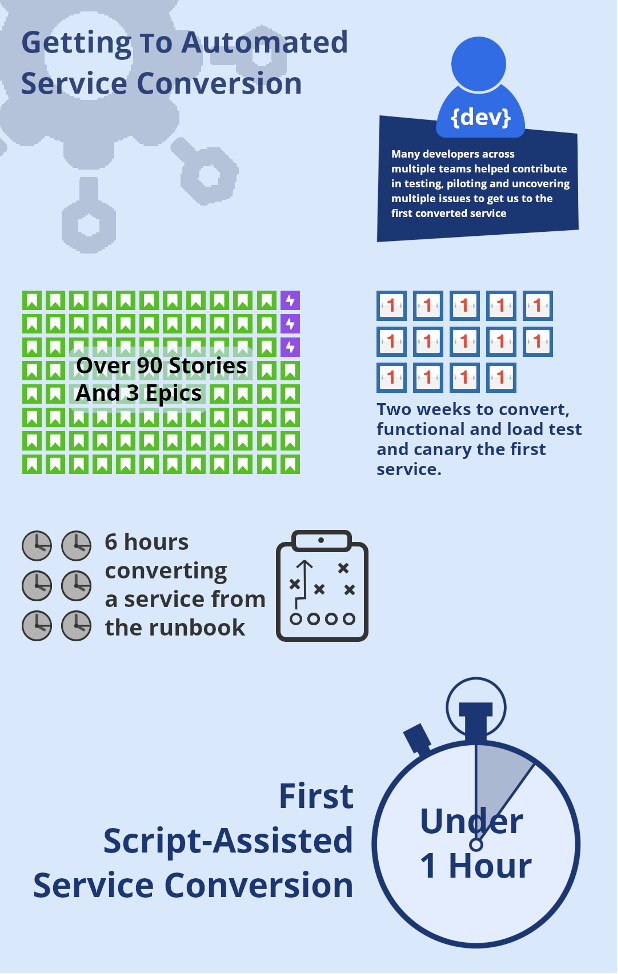
It took us two weeks to migrate our first service as we worked through everything from .NET Core API changes, to third party library upgrades and required code changes. From there we created an initial Runbook for all the necessary, known steps. Our next few services took us about six hours each to convert. We then created an automated script that could do 90% of all the conversion needed for a service. The remaining 10% accounted for the variation between our services. Our next service conversion took under an hour, not including load testing. The majority of the time was no longer in the service’s code, but the tests. The tests’ code was much harder to fully convert using an automated script.
a. Automation
We ended up with a useful and powerful script that enabled developers to convert the majority of their service’s code, configuration and build scripts. The script not only converted their code, but had the flexibility to also create a new git branch and separate all changes into different commits, if desired. This helped engineers understand exactly how the service was changing and review the Pull Request more safely.
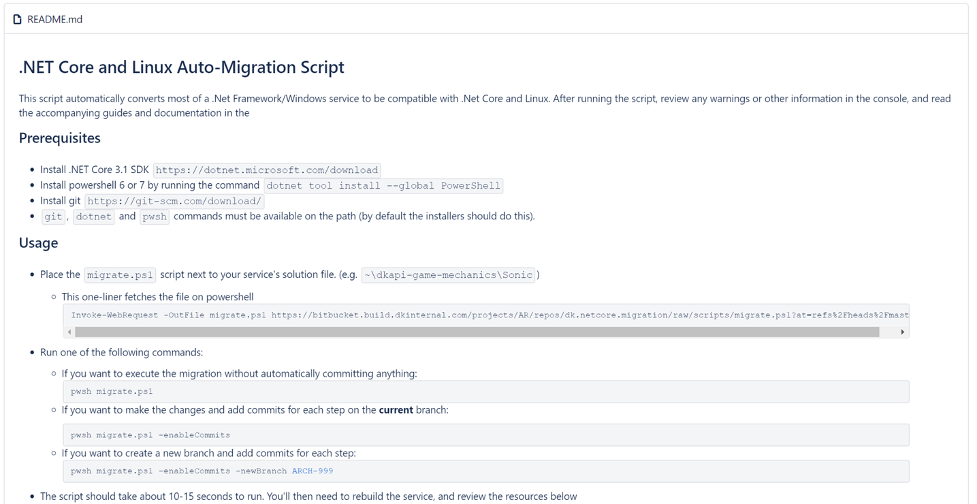
README instructions for our migration script
4. Trust but Verify
Although .NET Framework and .NET Core are both from Microsoft and share a fair amount of interfaces, there are a number of changes required that resulted in a different approach, API or library being used. It’s critical with any major technology shift to have good testing in place to ensure the behavior is the same. Good functional and integration tests were an important part of our criteria for choosing a pilot micro-service.
Some of the changes were due to previously unknown default behavior changes from .NET Framework to .NET Core or other third-party libraries. For example, some of our converted services threw the exception Request Header Fields Too Large. We discovered that the default number of allowed headers was much smaller in Kestrel than in the embedded web server we used previously for our micro-services. This was a quick fix of updating two settings:
KestrelServerOptions.Limits.MaxRequestHeaderCount
KestrelServerOptions.Limits.MaxRequestHeadersTotalSize
We were able to uncover a number of issues like this as we leaned on strong functional testing.
a. Load Testing
Once we had confidence that a microservice was functionally sound and exhibiting the same behavior as its .NET Framework version, we moved on to load testing. This is important, particularly for the first few critical services you convert. We uncovered an issue with our circuit breaking code during load testing. All other tests seemed to show no difference in behavior, but at high load we were seeing a growing amount of latency.
While we’d tried to keep our changes minimal, some interfaces had forced us to include some changes to asynchronous methods from previous synchronous ones. As a result, we’d missed that we were calling an externally facing ExecuteAsync(…) method on our circuit breaking HTTP library rather than the proper ExecuteAsyncInternal(…). This led to an infinite loop on some calls that showed up in our tests.
Proper load testing uncovered a number of issues and enabled us to have much greater confidence in deploying our micro-services.
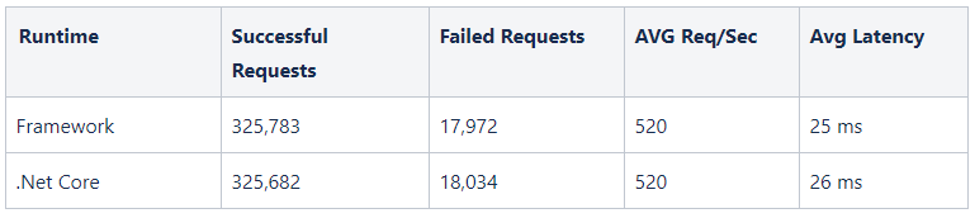
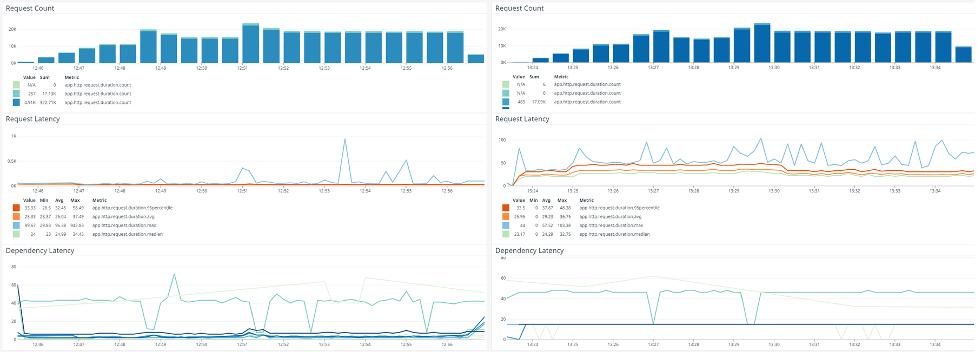
Load test results comparison dashboards
Not every micro-service needs to be load tested. Use your judgement based on the access patterns of that service in production. If your micro-service only has 100 concurrent users for example, load testing will offer you no usable information and waste your time.
b. Canary
Software is incredibly complex. Software in a micro-services world is orders of magnitude more complex. It’s impossible to predict every outcome or account for every variable. When you’re in a business where customers can lose money from buggy software, you have to be extremely careful in rolling out changes. For our software, this typically takes the form of feature rollouts and experiments. However, when an entire micro-service has changed its platform, you’re not rolling out a piece of functionality but an entire instance. The safe way to handle this is to use a canary-based approach. Using a load balancer, we can send a subset of the traffic to the new version of the service.
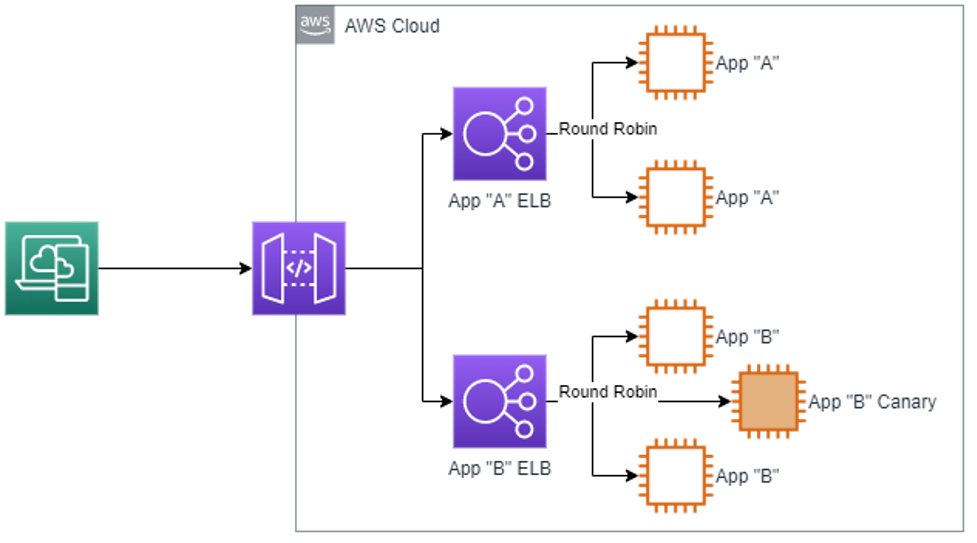
c. Feedback & Monitoring
Before you release a canary, make sure you have all your monitoring dashboards and logging set up so you can compare the health of the canary versus the other instances. You’ll want to monitor a number of areas such as:
- Instance & deployment logs
- Application logs (e.g. in ELK)
- Request metrics (latency, errors, database latency, etc) for the canary instance vs all others

5. Communicate often but deliberately
When you’re dealing with a large organization and many autonomous teams, no one team can do the project alone. It’s critical that you communicate to all stakeholders leading up to and throughout the entire project. You’ll also need to get some time on their roadmaps, such as within their sprints for agile teams as we did at DraftKings. We made sure to communicate regular updates, hold weekly meetings and keep people aware of everyone’s status on the “scoreboard.”
Additionally, communication is important for discovering good partners for pilots and to help uncover differences between different microservices. This offers an opportunity to bring in a diversity of perspectives and experience, leading to greater success and learning for the team. We started by holding weekly status meetings and recruiting a lot of amazing volunteer help from engineers around the organization. This not only helped with our progress, but with prioritizing some applications to convert and uncover issues that made our eventual automated script more powerful.
a. Education
An important part of communication is education as well. We spent a lot of time putting together documentation that helped engineers convert their services without a need for training. We had instructions, guides and numerous examples. We made sure it was a painless process and have received feedback from engineers across the organization on how smooth the process was due to the automation and documentation.
b. Documentation
Make sure to develop a Runbook for teams that covers some key aspects. A runbook is a compilation of routine procedures that a system admin carries out, which we used as a reference for our operations. :
Conversion of the micro-service
- Troubleshooting
- Building the micro-service
- Functional and load test guides (how to load test, how to compare the results with those of the non-converted service and covering different tuning configurations)
- Deployment
Our Runbook for micro-service migration to .Net Core
6. Expect unforeseen problems
No amount of planning, static analysis, or research can find every issue that arises during a large project—especially during a major technology shift. For all your diligence, you should still expect something to go wrong, be missed or forgotten. Just have a good process for dealing with it.
Many of these issues dealt with third party API changes, such as AutoMapper. We created documentation that was easy to follow and read like a git pull request.
a. Example Migration Issue Entry

7. Plan for support
We knew it would take a lot of time and effort beyond just the initial conversion, documentation and automation development. Our team planned for a significant amount of time to be spent supporting other teams converting their services. We found it to be a lot of fun and helped us learn more about how different teams tackled a wide variety of functionality. Mitigating the impact on the team was important, so our product owner worked with other teams to coordinate and plan for their transitions and ensure there was an engineer available to help.
a. Managing A Mixed Environment
We also recognized that there would be a long period of time when we were living in a mixed environment of converted and non-converted services. Our services made good use of strongly typed contracts for compile-time validation. This meant we had to develop some software for the non-converted services to make use of any contracts developed in .NET Core. We also built some core libraries to help the communication in the other direction as well. Most of the .NET Framework services did not have .NET Standard contracts and we did not want to force a chain of required updates just to convert a service.
We handled this by building compatibility into both “sides” of our SDK: an updated Framework version and our new .NET Core version. We added support in the Framework SDK to handle the existing NServiceKit contract types while adding overloaded support for the newer ServiceStack types. On the .NET Core side, we were able to continue using the non-migrated micro-services’ contracts since the .NET Core CLR is generally bytecode compatible with the Framework CLR. POCOs defined in Framework assemblies work fine in the .NET Core CLR.
Conclusion
One of the key learnings from this initiative is that it is imperative to build clear path to modernization, with a direction and philosophy. You cannot simply define a few steps and expect that to be successful for a large body of work implemented across an organization. This approach will enable your engineering organization to pivot in response to lessons learned on the way.
You can use the basic principles we’ve laid out here to develop your own direction and philosophy in a way that fits your company’s culture and structure and drives your next initiative to success.
AWS can help you assess how your company can get the most out of cloud. Join the millions of AWS customers that trust us to migrate and modernize their most important applications in the cloud. To learn more on modernizing Windows Server or SQL Server, visit Windows on AWS. Contact us to start your migration journey today.