AWS Cloud Operations Blog
Migrate from mainframe CA7 job schedules to Apache Airflow in AWS
When you migrate mainframe applications to the cloud, you will usually have to migrate mainframe job schedules too. In this post, I’ll show you how to migrate mainframe CA7 job schedules to a cloud native job scheduler in AWS, how to trigger off event-based jobs, how to run streaming jobs, how to migrate CA7 database, and how to use external calendar management services to manage job schedules.
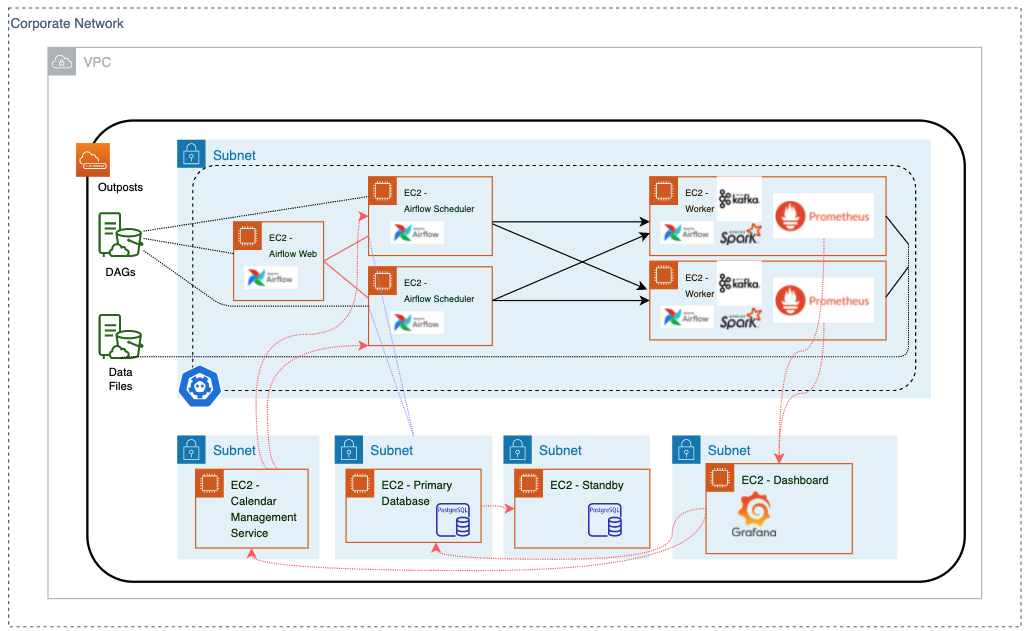
The main service used is Apache Airflow. You can use either Amazon Managed Workflows for Apache Airflow (MWAA), or run Apache Airflow in an Amazon Elastic Compute Cloud instance, or even deploy it in an instance within AWS Outposts for a hybrid cloud solution. The architecture diagram shown in the following figure depicts that an AWS Outposts rack is deployed in a customer’s corporate network due to the data residency requirement of the customer for which the solution was provided. Amazon Simple Storage Service (Amazon S3) on Outposts is used to store Apache Airflow’s Directed Acyclic Graph (DAG) objects and data files. A Kubernetes cluster of Apache Airflow is deployed on a subnet. From left to right, you see the Airflow web server, Airflow schedulers, and the Airflow workers. The Airflow worker nodes have Apache Kafka, Apache Spark, and Prometheus built in. Prometheus sends metrics/logs to a Grafana dashboard. From the dashboard, the administrator can interface with the database and work on a calendar management service. In turn, the database and calendar management service can send schedule changes to schedulers.
Mainframe CA7 scheduler assessment
To understand the scope of migration, we assessed the functionalities offered by mainframe CA7 scheduler and the capabilities noted below are covered in this post:
Scheduling
- Run, Rerun, Pause/Hold, Kill, or Override
- Retry
- Concurrent Jobs
- Job Dependency
- Job Statistics
- Job History
Triggers
- File Triggers
- Calendar Based
- Time Based
- Dependency Based
- Online Triggers
Calendar Management
- Processing/Non-Processing Days (NPD)
- Periodic Schedules
- Special Day Processing
For capabilities not covered in this post, such as monitoring and alerts, client onboarding, and reporting, we will cover it in a future blog.
Apache Airflow implementations
We used the open-source workflow management platform Apache Airflow to achieve the scheduling capabilities, including the abilities to run, retry, pause, kill, and override jobs; to run concurrent jobs; to define the dependency of jobs; to view the job execution status; and to allow values to be passed between tasks and the templating of jobs.
As mentioned above, we have a use case of AWS Outposts deployment, so Amazon MWAA is not used.
Implementations to work with Amazon S3
We used Amazon S3 for the storage of Airflow DAGs and data files. Amazon S3 is available on AWS Outposts as a new storage class called “S3 Outposts”. Although it delivers object storage on the customer’s premises, Amazon S3 is still a fully managed service and designed to provide high durability and redundancy.
We implemented Apache Airflow’s S3KeySensor as our S3 poller to respond to S3 events.
Since Apache Airflow doesn’t have a “Move Object” operator, we implemented Apache Airflow’s S3CopyObjectOperator and S3DeleteObjectOperator to move the S3 Object, so that an incoming file can be moved to a different folder to avoid repeated processing.
Implementations to handle job dependencies
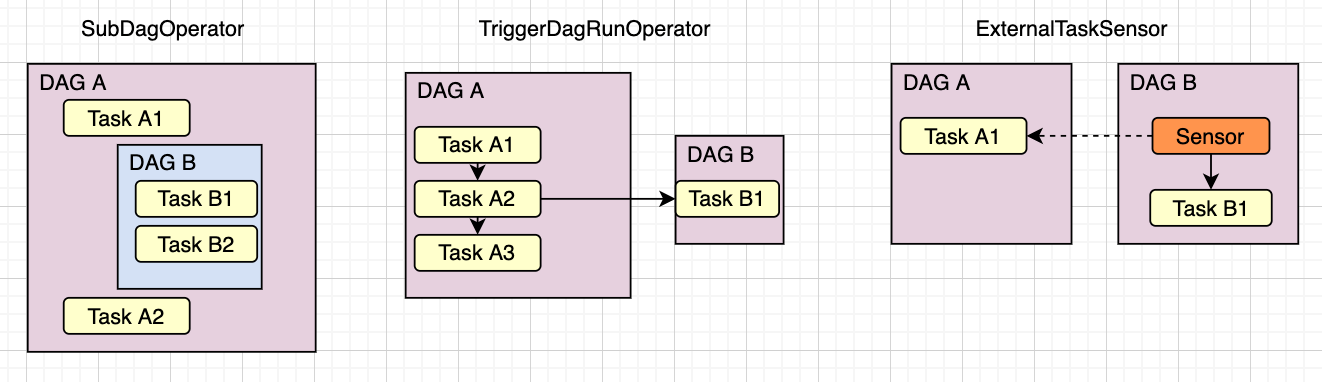
Depending on the use cases, you may try three different Airflow operators to handle job dependencies as shown in the following diagram. SubDagOperator lets us run a DAG with a separate set of tasks within another DAG.
TriggerDagRunOperator triggers another DAG from a DAG.
The ExternalTaskSensor sensor lets your task (B1) in DAG(B) be scheduled and wait for a success on task (A1) in DAG(A). This sensor will look up past executions of DAGs and tasks, and it will match those DAGs that share the same execution_date as our DAG. DAGs that are cross-dependent between them must be run in the same instance, or one after the other in a constant amount of time.
Implementations to trigger streaming jobs
Although AWS has Amazon Managed Streaming for Apache Kafka service, this deployment used the original Apache Kafka due to the AWS Outposts requirement. We implemented Kafka Producer in Airflow. When the S3 Poller detects a data file, Airflow runs a job that publishes a Kafka topic. The application consumes the topic and starts to process data. The application also publishes the processing status by sending out Kafka topics to notify the Airflow scheduler and Prometheus monitor.
We implemented Airflow’s SparkSubmitOperator in the DAGs to launch Spark jobs. Apache Spark is used in the applications to take advantage of Spark’s interface for programming the clusters with data parallelism and fault tolerance.
CA7 Database Migration
We excluded a big chunk of the CA7 database, such as the tables for automatic recovery and Job Control Language, because we won’t have the applications in the scheduler database. Therefore, only a small list of tables from CA7 were carried over:
- Job_Definition: the main fields include Job ID and Job description, plus the new field for Airflow – DAG Template. The Job ID is from the CA7 Job Definition table. You must migrate all of the jobs that are still valid as the result of the migration, and create new Job IDs for new jobs. The DAG Templates are the DAGs that must be created in Apache Airflow separately.
- Job_Schedule: the main fields include Schedule ID, Job ID from the Job Definition table, Customer Number from your customer table, Date/Time to run jobs, Job running intervals (weekly, monthly, quarterly, and yearly), and the Calendar ID from the Calendar table described in the following section.
- Job_Trigger: the main fields include Job Trigger ID, Triggered Schedule ID, and Triggering Schedule ID. A trigger is a form of scheduling – the main trigger that we used is the COMPLETION of a job which is identified by a Schedule ID.
- Job_Predecessor_Successor: the main fields are Schedule ID, predecessor Schedule ID, and Successor Schedule ID.
Calendar Management Service
Calendar Design
This customer has many clients across different countries and regions with different holidays and non-processing days, so their job schedules heavily depend on the calendars. In fact, calendar management is an integrated part of CA7 system. This customer has used more than 300 calendars, about one third of them are called as third-shift calendars. Third-shift calendars are used to schedule jobs that can span past midnight. One of our main design goals is to get rid of the third-shift calendars. We have designed the following tables for the cloud native scheduler to use:
- Calendar_definition – a table to record all unique holidays and non-processing days, with calendar name and calendar year.
- Client_calendar – a table to assign calendars to clients, with the calendar IDs and client number as the basic fields. The additional fields are the starting time and ending time of the processing day for a particular client’s jobs using the calendar. The example of the starting time and ending time of the processing day can be 8:00 PM and 6:00 AM, which means today’s 8:00 PM through tomorrow’s 6:00 AM is a valid job processing window using this calendar for this client. You can retire the third-shift calendars using this pair of fields.
- Emergency_non_processing_days – add any arbitrary dates to this table to let the client pause all of the jobs during emergencies.
Schedule Resolution Process
The schedule resolution process is created as a Java process to validate a job schedule. When an operator schedules a job for a client using a calendar, the schedule will be validated against the processing days on the calendar.
Schedule Scan and Job Submission to Apache Airflow
The schedule scan process is created as a Java process to search job schedules. The process will run the search periodically, typically one day or half of a day. It will find all of the valid job schedules for the next period and submit all of the job schedules to Apache Airflow —effectively triggering off DAG runs.
Conclusion
This post demonstrates how the mainframe job schedules can be migrated to Apache Airflow in AWS, how you can trigger off event-based jobs and streaming jobs in Airflow, how you can migrate CA7 database, and how you can use external calendar management services to manage job schedules.
Next step
If your solution doesn’t need to be in AWS Outposts, you may use more AWS services, such as Amazon MWAA, Amazon Managed Streaming for Apache Kafka, Amazon Elastic Kubernetes Service, Amazon S3 on Outposts, and Amazon CloudWatch.