AWS Open Source Blog
Better Random Number Generation for OpenSSL, libc, and Linux Mainline
In 2015, AWS introduced s2n, a new open source implementation of the TLS/SSL protocols that protect the privacy and integrity of data moving over a network. s2n was designed to be secure, simple, small, and fast.
The project is thriving, and we use it extensively. In February, our CISO Stephen Schmidt shared that “we have replaced OpenSSL with s2n for all internal and external SSL traffic in Amazon Simple Storage Service (Amazon S3) commercial regions.” We’ll also have more announcements over the coming months on other applications where we’re using s2n.
![]()
A critical foundation of any cryptographic protocol is the ability to generate secure random numbers. With the TLS/SSL protocols, random numbers are used to establish the encryption keys that secure the data being transferred. If the random numbers are predictable, then it doesn’t matter how strong the encryption itself is, because the key itself can become compromised. Over the years, many random number generators have been created, and, unfortunately, several have been found to be unsafe, either because the algorithms were compromised and inherently predictable or biased, or because the random number generators were poorly initialized from a seed value (a.k.a. “entropy”) that could be guessed or leaked in some way.
When we built s2n, we had to choose a secure random number generator to use. After evaluating many for both security and performance, we chose AES_CTR_DRBG (that’s short for “Advanced Encryption Standard Counter Mode Deterministic Random Bit Generator”) in prediction-resistant mode. This generator has a written specification, it’s simple, easy to understand and based on the security of AES, it has reference test vectors, and it was something we would be able to formally verify.
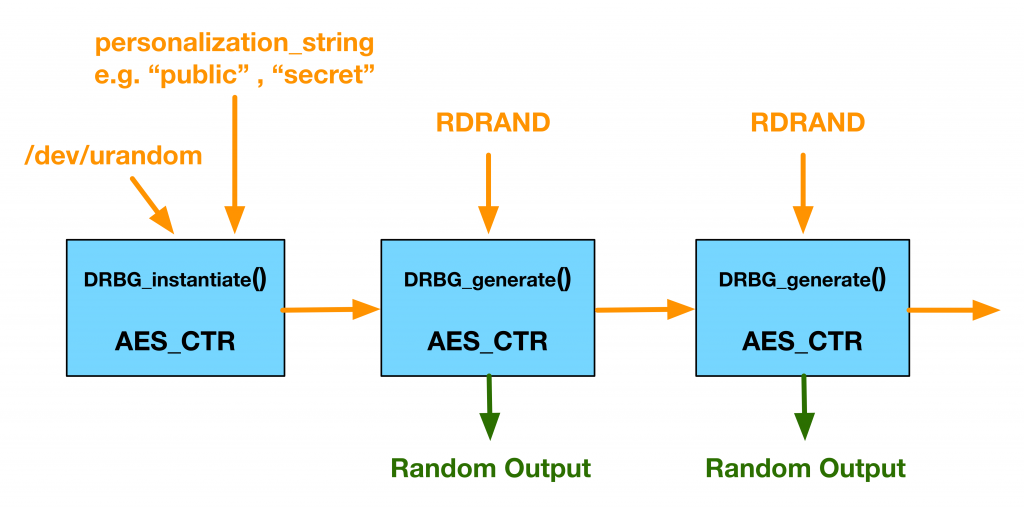
Earlier this year, with Galois, we completed a proof of our implementation of AES_CTR_DRBG, and formally verified that our code in s2n is equivalent to the written specification.
Recently, both the OpenSSL and glibc projects have been looking to replace their random number generators. They, too, are going with AES_CTR_DRBG, based in some part on the work in s2n and the availability of formal verifications that can be applied to code. That’s pretty sweet.
But what’s really exciting for us is that, in the course of working on libc, we were also able to get traction on another important change, in Linux itself. Last year, we suggested a new madvise() option for the Linux kernel. Based on OpenBSD’s MINHERIT_ZERO, the option marks memory regions as WIPEONFORK, which means that those regions are zeroed in a child process immediately after a fork() call.
The fork() call copies a process: this is how servers (and other things) scale themselves. For example, web server software will commonly call fork() to make several copies of itself, each handling one or more different connections, and each capable of running on its own CPU core. Normally when software calls fork(), a kind of mitosis happens: one process becomes two, with both processes being virtually identical, including the same memory.
That makes scaling fast and reliable, but it’s dangerous for random number generators. The reason is that, after a fork, both processes could have the same generators running, initialized with the same seeds, capable of producing the same series of numbers. One process might use those random numbers in a public context, for example in the series of random bytes that starts every TLS “hello” message, while the other might use them in a secret context, like generating a key. That’s really bad for security, because the key is now effectively public.
s2n has long included three “defense in depth” mitigations for this problem. Firstly, as mentioned, s2n uses the so-called “Prediction resistant” mode, which means that s2n feeds the random number generator with more entropy (from hardware) on every call, as long as the right hardware is available. Secondly, s2n’s random number generators are typed: every thread has a “public” generator, and a “secret” generator, each initialized separately. Lastly, s2n uses the “pthread_atfork” call to detect fork() calls and to reset the random number generators.
The new WIPEONFORK option is designed to do a more robust job than that last mitigation, because in some cases the pthread_atfork call can be bypassed. If you were running an application that bypasses pthread_atfork, on a platform that also lacks hardware entropy, you would have just one layer of defense in place against a broken random number generator. Those circumstances are rare: few applications bypass pthread_atfork, and hardware entropy is now common, but we prefer to have at least two layers of defense even in uncommon cases.
WIPEONFORK can’t be bypassed, because the kernel itself wipes the random number generator memory as the fork() call is occurring. The new process will then re-initialize the random number generator, secure in the knowledge that there is no risk of duplication.
This was truly a community effort. Florian Weimer of Red Hat reached out to Rik Van Riel, who did most of the work in getting the patch together and shepherding it through the contribution process. The work of Rich Salz from OpenSSL was also critical. Thanks to their help, the patch has been in Linus’ tree and the kernel manpages since early September. It is now available for everyone to use in the Linux 4.14 release.
This means that we’ll be able to get more robust random number generation – a foundation of cryptographic security – on the platform that we and our customers use.
These are just two examples of how we participate in the open source community. We’ll have a lot more to say about this in the future.
Learn more about s2n and how to use it and contribute to it.
Colm is a Senior Principal Engineer at AWS, and a long time member of the Apache Software Foundation. Colm works on EC2, Cryptography, Apache httpd, and plays Irish music in his spare time.
Follow us @AWSOpen for the latest news! And also visit opensource.amazon.com and aws.github.io.