AWS Open Source Blog
Leveraging Open Source at Barclays to Enable Lambda Event Filtering with AWS Glue Schema Registry
Barclays is a British, multinational universal bank. Its businesses include consumer banking and a top-tier global investment and corporate bank that deploys finance responsibly to support people and their businesses.
Engineering teams at Barclays strive to provide a best-in-class user experience to their customers, irrespective of their devices, platforms, or channels for different products. To meet changing customer expectations and business requirements, Barclays has partnered with AWS and adopted cloud native, event-driven systems that scale to millions of transactions per day. Barclays is leveraging modern serverless technologies like Amazon DynamoDB, AWS Lambda, Amazon Kinesis Data Streams, and others to build the solution from the ground-up.
When operating at such a large scale, in the event driven system, messages pass through numerous internal and third-party systems, which increases the risk of data corruption and loss. As a result, ensuring message integrity becomes crucial, and implementing a schema to validate incoming and outgoing events becomes mandatory. Moreover, a centralized source of schemas should exist for all systems to access and follow a consistent set of rules. Hence, Barclays engineering teams decided to adopt AWS Glue Schema Registry, which lets you centrally discover, control, and evolve schemas. Glue Schema Registry is a part of the AWS serverless data integration service called AWS Glue that makes it easy for analytics users to discover, prepare, move, and integrate data from multiple sources.
During the initial implementation of the AWS Glue Schema Registry integration, however, Barclays engineers observed that certain Lambda functions were discarding messages. On further analysis, engineers discovered that impacted AWS Lambda functions were using AWS Lambda event filtering, which currently doesn’t support an AWS Glue Schema Registry integrated payload. Nonetheless, AWS Lambda event filtering was a critical feature for Barclays in ensuring that AWS Lambda functions only listen to the relevant records, thereby decreasing unnecessary invocations and lowering overall costs.
Barclays reached out to AWS Enterprise Support for their guidance. While AWS Enterprise Support agreed that the use case was valid and could be added to the product roadmap, it would take time and impact Barclays’ adoption and overall time-to-market.
Fortunately, the AWS Glue Schema Registry integration library is open source. Barclays engineering teams decided to create a wrapper around the AWS library to customize their solution. In this post, we’ll dive into how Barclays achieved AWS Glue Schema Registry integration with AWS Lambda event filtering by leveraging the open source library.
Overview
We will use an example of event driven architecture for a generic customer onboarding flow presented in Figure 1 for the purpose of this blog post.
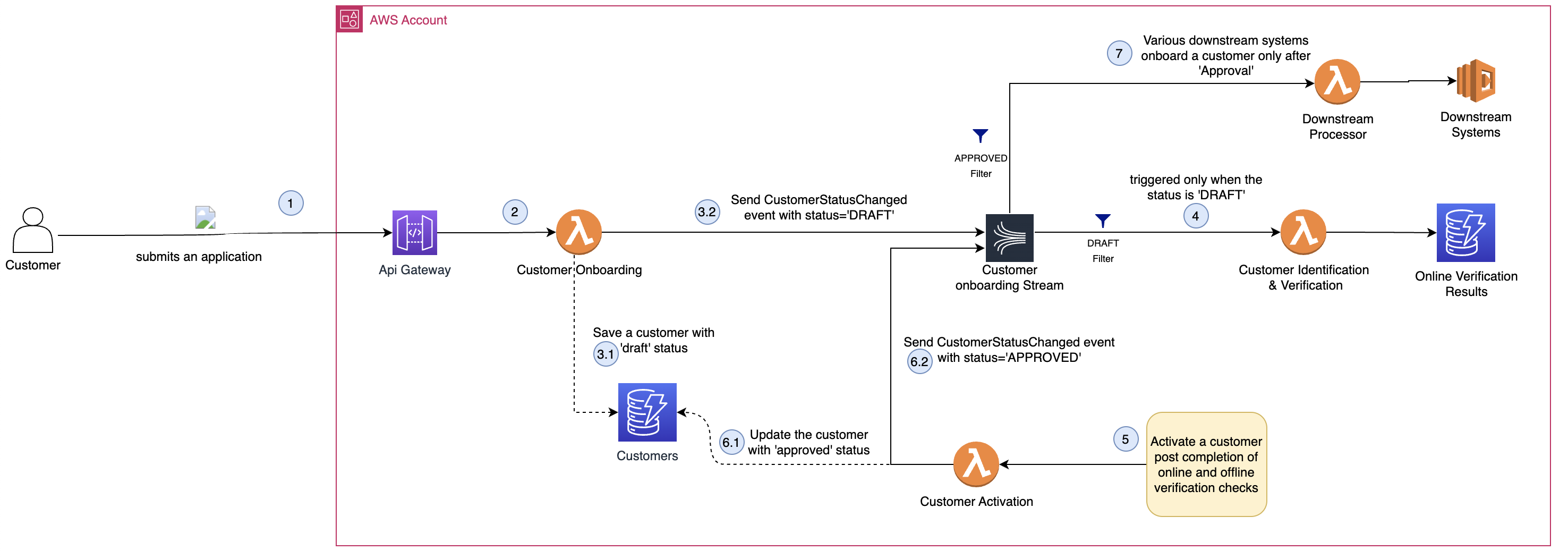
Figure 1: Sample onboarding architecture.
Upon receiving the registration details (1), the “onboarding” AWS Lambda Function processes this request (2) and stores the customer’s data with an initial ‘draft’ status (3.1). Then, this onboarding AWS Lambda Function acts as a producer (an application that sends records in Amazon Kinesis Data Streams) and sends a ‘CustomerStatusChanged’ event on the stream (3.2).
The “identification and verification” AWS Lambda Function consumes (acting as consumer – an application that processes all data from Amazon Kinesis Data Streams) this event (4), applies a set of rules and saves the outcome.
After checks are completed, the “activation” AWS Lambda Function (5) is marking the customer as ‘approved’ (6.1) and produces another ‘CustomerStatusChanged’ event on the stream (6.2) that will be consumed by the “downstream processer” AWS Lambda Function (7) to onboard the customer on different downstream platforms.
Let’s understand the event structure of this ‘CustomerStatusChangedEvent’.
Here is the sample event in the JSON format:
{
"metadata": {
"type": "CustomerStatusChangedEvent",
"correlationId": "d8ff771f-da02-4a7a-aa47-72f3b22c5641"
},
"body": {
"id": "customer-123",
"name": "Mr Sample Customer",
"oldStatus": "DRAFT",
"newStatus": "APPROVED"
}
}
The event is divided into two parts: (1) metadata and (2) body. The metadata contains details related to this event, and the body contains relevant information about the business domain.
You can see that there are some processes which get activated when the status is ‘draft’ (like identification and verification) and there are others which get activated when the status is ‘approved’ (like downstream systems).
AWS Lambda-based consumers use event filtering to ensure that the consumer Lambda Functions only get triggered when the customer is in the applicable state. This is shown in the diagram presented in Figure 2.

Figure 2. AWS Lambda based consumers with AWS Lambda based filtering.
An AWS Lambda event filter for consumers acting on the status of DRAFT is represented here.
{
"data": {
"body": {
"newStatus": [
"DRAFT"
]
}
}
}
Consumers acting on the status of APPROVED are represented here.
{
"data": {
"body": {
"newStatus": [
"APPROVED"
]
}
}
}
Challenge
As shown in Figure 1, the messages in the Amazon Kinesis Data Streams traverse through multiple systems. To ensure data integrity, every producer must validate the outgoing message before publishing it to the Amazon Kinesis Data Stream, while every consumer service must ensure that the incoming message has been validated.
Addressing this challenge requires the adoption of schemas on a large scale with AWS Glue Schema Registry. The introduction of the AWS Glue Schema Registry doesn’t require architectural changes (Figure 3) – this adoption process faced a roadblock when internal AWS Lambda-based consumers started dropping the payload when event filtering was enabled. Engineers discovered that AWS Lambda event filtering doesn’t support a glue schema registry integrated payload.

Figure 3. AWS Lambda based filtering with AWS Glue Schema Registry
On the producer side, the open source library fetches the schema from the AWS Glue Schema Registry and validates the outgoing message. Before putting the message on the stream, the producer encodes the message by pre-pending the magic number of schema version id from the deployed schema of the registry. The consumer uses the same schema version id prefix to retrieve the producer schema to deserialize the message.
In this process, the message becomes a non-JSON payload. The message fails the Lambda filtering on the consumer side (if we are using the Amazon Kinesis Stream filtering criteria) and gets dropped by the consumer.
You can see an example of the payload before serialization here:
{
"metadata": {
"type": "CustomerStatusChangedEvent",
"correlationId": "d8ff771f-da02-4a7a-aa47-72f3b22c5641"
},
"body": {
"id": "customer-123",
"name": "Mr Sample Customer",
"oldStatus": "DRAFT",
"newStatus": "APPROVED"
}
}
And then after serialization here:
8f7083ec-652c-4e01-917e-0098aee57b5e{
"metadata": {
"type": "CustomerStatusChangedEvent",
"correlationId": "d8ff771f-da02-4a7a-aa47-72f3b22c5641"
},
"body": {
"id": "customer-123",
"name": "Mr Sample Customer",
"oldStatus": "DRAFT",
"newStatus": "APPROVED"
}
}
Based on the documentation for properly filtering Kinesis and DynamoDB messages, this was an expected behaviour. As highlighted in the below table, when the message is a non-JSON payload, the filtering action is to drop the record.

Solution
Barclays engineering teams support both JSON and Apache AVRO as acceptable message formats for their event-driven systems. However, JSON is more ubiquitous. It’s easy for developers to work with and is one of the most common data serialization formats used on the web. JSON is readable by humans and allows fast adoption. One added advantage of using a JSON-based format is Lambda event filtering for messaging payloads, which lets Barclays reduce traffic and overall costs. To maintain integration with Lambda event filtering, Barclays needed to ensure that the payload followed the JSON structure while integrating with AWS Glue Schema Registry. The optimal option Barclays found was to add this schema version id as a JSON node rather than as a prefix.
This design served the following purposes:
- On the consumer side, Barclays can still identify the producer schema with which the original message was validated.
- The message is still JSON compliant. This ensures that AWS Lambda consumers can still use content-based message filtering while continuing to adopt the AWS Glue Schema Registry.
It was immensely helpful that AWS provided the Glue Schema Registry integration library as open source. Barclays engineering teams decided to create a wrapper around the AWS library to support this customization. The customized version of serialization and deserialization was added within this wrapper library. Barclays extended key classes to add schema version id as a separate JSON node on the producer side and retrieval/deserialization of the payload on the consumer side.
Because the schema id was meta information for the payload, it was logical to add it as a child of the metadata node. You can see the resulting payload here:
{
"metadata": {
"type": "CustomerStatusChangedEvent",
"correlationId": "d8ff771f-da02-4a7a-aa47-72f3b22c5641",
"schemaVersionId": "aa51c003-1384-4437-8c8d-835cb20d203e"
},
"body": {
"id": "customer-123",
"name": "Mr Sample Customer",
"oldStatus": "DRAFT",
"newStatus": "APPROVED"
}
}
Implementation guide
Let’s dive into how Barclays achieved AWS Glue Schema Registry integration with AWS Lambda event filtering. In the below examples, Barclays is using Java as the programming language. However, a similar implementation would be applicable to other languages as well.
Serialization

Figure 4: Serializer class diagram
Barclays decided to override GlueSchemaRegistrySerializer.java on the producer side. The default serialization process is responsible for adding schemaVersionId bytes as a prefix to the payload.
public interface GlueSchemaRegistrySerializer {
byte[] encode(String transportName, Schema schema, byte[] data);
}
The default implementation of GlueSchemaRegistrySeralizerImpl, as shown here, delegates a call to a facade. The facade is responsible for serializing the payload to add the schemaVersionId as a prefix in payload bytes.
public class GlueSchemaRegistrySerializerImpl implements GlueSchemaRegistrySerializer {
private final GlueSchemaRegistrySerializationFacade glueSchemaRegistrySerializationFacade;
@Override
public byte [] encode (@Nullable String transportName, Schema schema, byte[] data) {
return glueSchemaRegistrySerializationFacade.encode(
transportName,
schema,
data
);
}
}
This default facade GlueSchemaRegistrySerializationFacade, shown in here, is the main class where, in the encode() method, schemaVersionId is fetched and payload is serialized with using SerializationDataEncoder.write().
public class GlueSchemaRegistrySerializationFacade {
private AWSSchemaRegistryClient awsSchemaRegistryClient;
private SerializationDataEncoder serializationDataEncoder;
private GlueSchemaRegistryConfiguration glueSchemaRegistryConfiguration;
private GlueSchemaRegistrySerializerFactory glueSchemaRegistrySerializerFactory =
new GlueSchemaRegistrySerializerFactory();
public byte[] encode(String transportName,
Schema schema,
byte[] data) {
final String dataFormat = schema.getDataFormat();
final String schemaDefinition = schema.getSchemaDefinition();
final String schemaName = schema.getSchemaName();
GlueSchemaRegistryDataFormatSerializer dataFormatSerializer =
glueSchemaRegistrySerializerFactory.getInstance(
DataFormat.valueOf(dataFormat), glueSchemaRegistryConfiguration);
//Ensures the data bytes conform to schema definition for data formats like JSON.
dataFormatSerializer.validate(schemaDefinition, data);
UUID schemaVersionId = getOrRegisterSchemaVersion(AWSSerializerInput.builder()
.schemaDefinition(schemaDefinition)
.schemaName(schemaName)
.dataFormat(dataFormat)
.transportName(transportName)
.build());
return serializationDataEncoder.write(data, schemaVersionId);
}
}
The SerializationDataEncoder class shown in here prepends schema version id in bytes and is added as a prefix to the payload.
/**
* Schema Registry header consists of following components:
* 1. Version byte.
* 2. Compression byte.
* 3. Schema Version UUID Id that represents the writer schema.
* 4. Actual data bytes. The data can be compressed based on configuration.
*
* @param objectBytes bytes to add header to.
* @return Schema Registry header encoded data.
*/
public byte[] write(final byte[] objectBytes, UUID schemaVersionId) {
byte[] bytes;
try (ByteArrayOutputStream out = new ByteArrayOutputStream()) {
writeHeaderVersionBytes(out);
writeCompressionBytes(out);
writeSchemaVersionId(out, schemaVersionId);
boolean shouldCompress = this.compressionHandler != null;
bytes = writeToExistingStream(out, shouldCompress ? compressData(objectBytes) : objectBytes);
} catch (Exception e) {
throw new AWSSchemaRegistryException(e.getMessage(), e);
}
return bytes;
}
To change this default behaviour and add the schemaVersionId as a separate node, Barclays added a custom implementation of GlueSchemaRegistrySerializer, as shown here.
public class CustomGlueSchemaRegistrySerializerImpl implements GlueSchemaRegistrySerializer {
private final CustomGlueSchemaRegistrySerializationFacade customGlueSchemaRegistrySerializationFacade;
public CustomGlueSchemaRegistrySerializerImpl(
CustomGlueSchemaRegistrySerializationFacade customGlueSchemaRegistrySerializationFacade) {
this.customGlueSchemaRegistrySerializationFacade = customGlueSchemaRegistrySerializationFacade;
}
@SneakyThrows
@Override
public byte[] encode(String transportName, Schema schema, byte[] data) {
return customGlueSchemaRegistrySerializationFacade.encode(
transportName,
schema,
data
);
}
}
Barclays extended the default serialization facade with their own version, as shown here.
@Slf4j
public class CustomGlueSchemaRegistrySerializationFacade extends GlueSchemaRegistrySerializationFacade {
private final GlueSchemaRegistryConfiguration glueSchemaRegistryConfiguration;
private final GlueSchemaRegistrySerializerFactory glueSchemaRegistrySerializerFactory =
new GlueSchemaRegistrySerializerFactory();
@SneakyThrows
@Override
public byte[] encode(String transportName, Schema schema, byte[] data) {
final String dataFormat = schema.getDataFormat();
final String schemaDefinition = schema.getSchemaDefinition();
final String schemaName = schema.getSchemaName();
// in case of non JSON dataformat call super encode
if(! DataFormat.JSON.name().equals(dataFormat)) {
return super.encode(transportName, schema, data);
}
GlueSchemaRegistryDataFormatSerializer dataFormatSerializer =
glueSchemaRegistrySerializerFactory.getInstance(
DataFormat.valueOf(dataFormat), glueSchemaRegistryConfiguration);
//Ensures the data bytes conform to schema definition for data formats like JSON.
dataFormatSerializer.validate(schemaDefinition, data);
UUID schemaVersionId = getOrRegisterSchemaVersion(AWSSerializerInput.builder()
.schemaDefinition(schemaDefinition)
.schemaName(schemaName)
.dataFormat(dataFormat)
.transportName(transportName)
.build());
return addSchemaVersionId(data, schemaVersionId);
}
private byte[] addSchemaVersionId(byte[] data, UUID schemaVersionId) throws JsonProcessingException {
final String payload = new String(data, StandardCharsets.UTF_8);
log.info("Payload received : {} ", payload);
ObjectMapper mapper = new ObjectMapper();
JsonNode jsonRequest = mapper.readTree(payload);
JsonNode metadataNode = jsonRequest.get("metadata");
JsonNode schemaVersionIdNode = mapper.readTree(mapper.writeValueAsString(schemaVersionId.toString()));
((ObjectNode) metadataNode).set("schemaVersionId", schemaVersionIdNode);
log.info("schemaVersionId added to Payload : {} ", jsonRequest);
return jsonRequest.toString().getBytes(StandardCharsets.UTF_8);
}
}
Deserialization

Figure 5. Deserializer class diagram
Barclays followed the same approach with the deserialization process that they did for the serialization process. They changed the GlueSchemaRegistryDeserializer.java interface on the consumer side to identify the schema version id to retrieve the schema from the registry and deserialize the incoming message.
The custom implementation of GlueSchemaRegistryDeserializer shown in the first code block here can similarly delegate calls to custom facade implementations, as presented in the second code block, following.
public class CustomGlueSchemaRegistryDeserializerImpl implements GlueSchemaRegistryDeserializer {
private final CustomGlueSchemaRegistryDeserializationFacade glueSchemaRegistryDeserializationFacade;
@Override
public byte[] getData(final byte[] encodedData) {
Object data = glueSchemaRegistryDeserializationFacade.deserialize(
AWSDeserializerInput.builder().buffer(ByteBuffer.wrap(encodedData)).build());
if(data instanceof JsonDataWithSchema) {
JsonDataWithSchema jsonDataWithSchema = (JsonDataWithSchema)data;
return jsonDataWithSchema.getPayload().getBytes(StandardCharsets.UTF_8);
} else {
try {
return new ObjectMapper().writeValueAsString(data).getBytes(StandardCharsets.UTF_8);
} catch (JsonProcessingException e) {
throw new AWSSchemaRegistryException(e);
}
}
}
@Override
public Schema getSchema(final byte[] data) {
return glueSchemaRegistryDeserializationFacade.getSchema(data);
}
@Override
public boolean canDeserialize(final byte[] data) {
return glueSchemaRegistryDeserializationFacade.canDeserialize(data);
}
}
The GlueSchemaRegistryDeserializationFacade class contains the default implementation which deserializes the payload and removes schemaVersionId prefix from the payload.
@Slf4j
public class CustomGlueSchemaRegistryDeserializationFacade extends GlueSchemaRegistryDeserializationFacade {
private final AWSSchemaRegistryClient schemaRegistryClient;
private final GlueSchemaRegistryConfiguration glueSchemaRegistryConfiguration;
private GlueSchemaRegistryCache<UUID, Schema, CacheStats> cache;
@Override
public Schema getSchema(@NonNull byte[] data) {
ByteBuffer byteBuffer = ByteBuffer.wrap(data);
AwsDeserializerSchema awsDeserializerSchema = getAwsDeserializerSchemaObject(byteBuffer);
return awsDeserializerSchema.getSchema();
}
@Override
public Object deserialize(@NonNull AWSDeserializerInput deserializerInput) throws AWSSchemaRegistryException {
ByteBuffer buffer = deserializerInput.getBuffer();
AwsDeserializerSchema awsDeserializerSchema = getAwsDeserializerSchemaObject(buffer);
Schema schema = awsDeserializerSchema.getSchema();
CustomJsonDeserializer customJsonDeserializer = CustomJsonDeserializer.builder()
.configs(glueSchemaRegistryConfiguration)
.build();
return customJsonDeserializer.deserialize(buffer, schema.getSchemaDefinition());
}
@Override
public boolean canDeserialize(final byte[] data) {
if (data == null) {
return false;
}
boolean canDeserialize = true;
JsonNode jsonNodeTree = getMetadataNodeFromPayload(data);
if(! jsonNodeTree.getClass().isAssignableFrom(ObjectNode.class)
|| jsonNodeTree.get("schemaVersionId") == null) {
canDeserialize = false;
}
return canDeserialize;
}
private JsonNode getMetadataNodeFromPayload(byte[] data){
try {
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(data);
return jsonNode.get("metadata");
} catch (IOException e) {
throw new AWSSchemaRegistryException(ERROR_DESERIALIZING_JSON, e);
}
}
private AwsDeserializerSchema getAwsDeserializerSchemaObject(ByteBuffer buffer){
final String payload = new String(buffer.array(), StandardCharsets.UTF_8);
log.debug("Payload received : {} ", payload);
JsonNode jsonNodeTree = getMetadataNodeFromPayload(buffer.array());
JsonNode schemaVersionIdNode = jsonNodeTree.get(SCHEMA_VERSION_ID_NODE_KEY);
UUID schemaVersionId = UUID.fromString(schemaVersionIdNode.asText());
log.debug("schemaVersionId retried from payload : {} ", schemaVersionId);
Schema schema = retrieveSchemaRegistrySchemaBySchemaVersionId(schemaVersionId);
return new AwsDeserializerSchema(schemaVersionId, schema);
}
private Schema retrieveSchemaRegistrySchemaBySchemaVersionId(UUID schemaVersionId) throws AWSSchemaRegistryException {
Schema schema = cache.get(schemaVersionId);
if (schema != null) {
return schema;
}
GetSchemaVersionResponse response =
this.schemaRegistryClient.getSchemaVersionResponse(schemaVersionId.toString());
log.debug("Retrieved writer schema from Amazon Schema Registry for message: schema version id = {}, ", schemaVersionId);
schema = new Schema(response.schemaDefinition(), response.dataFormat()
.name(), getSchemaNameFromARN(response.schemaArn()));
cache.put(schemaVersionId, schema);
return schema;
}
private String getSchemaNameFromARN(String schemaArn) {
Arn arn = Arn.fromString(schemaArn);
String resource = arn.resourceAsString();
String[] splitArray = resource.split("/");
return splitArray[splitArray.length - 1];
}
}
Barclays extended the default deserialization facade to provide their own version of the implementation. It uses the JSON node to identify whether the incoming message is integrated with the glue schema registry. CustomJsonDeserializer, shown here, retrieves the schemaVersionId added by the producer in the payload.
@Slf4j
public class CustomJsonDeserializer implements GlueSchemaRegistryDataFormatDeserializer {
private final ObjectMapper objectMapper;
@Override
public Object deserialize(@NonNull ByteBuffer buffer, @NonNull String schema) {
try {
byte[] data = buffer.array();
log.debug("Length of actual message: {}", data.length);
Object deserializedObject;
String payload = removeSchemaVersionIdFromData(data);
JsonNode schemaNode = objectMapper.readTree(schema);
JsonNode classNameNode = schemaNode.get("className");
if (classNameNode != null) {
String className = classNameNode.asText();
deserializedObject = objectMapper.readValue(payload, Class.forName(className));
} else {
deserializedObject = JsonDataWithSchema.builder(schemaNode.toString(), payload)
.build();
}
return deserializedObject;
} catch (IOException | ClassNotFoundException e) {
throw new AWSSchemaRegistryException("Exception occurred while de-serializing JSON message.", e);
}
}
private String removeSchemaVersionIdFromData(byte[] data) throws IOException {
JsonNode dataNode = objectMapper.readTree(data);
JsonNode metadataNode = dataNode.get("metadata");
if(metadataNode == null || metadataNode.get("schemaVersionId") == null) {
throw new AWSSchemaRegistryException("Payload metadata is missing or schemaVersionId is missing in metadata");
}
// Remove added schemaVersionId field in payload
((ObjectNode) metadataNode).remove("schemaVersionId");
return dataNode.toString();
}
}
Conclusion
With the implemented solution, the payload is still formatted in JSON and AWS Lambda filtering works appropriately. It allows only applicable events to be passed from the producers to the consumers. Using the schemaVersionId node, a consumer can identify that the incoming payload is integrated with AWS Glue Schema Registry and use its value to load producer-side schema to deserialize the payload.
With AWS open source libraries, Barclays managed to address the challenge with AWS Lambda and Amazon Kinesis integration when they adopted AWS Glue Schema Registry. By customizing an open source library Barclays improved their business delivery safely and helped continue their schema registry adoption without impacting AWS Lambda based functions using event filtering.
The code samples in this blog are for educational purposes only and may not reflect the actual production code. If you’d like to learn more about how Barclays manages tech and innovation, please check their innovation page.
This article was written by Barclays consumer banking team in collaboration with AWS.