AWS Open Source Blog
Scheduling Jupyter Notebooks with AWS Orbit Workbench
This post was contributed by Olalekan Elesin, Head of Data Platform & Data Architect at HRS Group and AWS Machine Learning Hero
The HRS Group, a market leader in the global business travel market, is scheduling Jupyter Notebooks with the open source solution AWS Orbit Workbench. HRS provides brokerage of hotel rooms for private and business customers. The technology provider for business travel leverages its unique lodging-as-a-service platform to oversee the totality of corporate hotel programs for its clients from continual procurement and rate assurance to booking, virtual payment, and expense management. With more than 60,000 hotels joining HRS’ Clean & Safe Protocol since 2020 and the recently launched Green Stay Initiative, HRS provides newly prioritized information on key decision factors impacting post-pandemic travel. HRS reinvents how organizations stay, work, and pay.
HRS is driven by data, cutting across all of its customer initiatives—Savings, Satisfaction, Sustainability, Safety, and Security. The company relies on data to support key initiatives such as making fast, accurate business decisions as well as product innovation and development. HRS created a data platform team to make data accessible to everyone at HRS, through decentralized data ownership and providing a data platform that is scalable and user-friendly for all data producers and consumers.
Having a small, central team enable data use across a global organization such as HRS can be challenging. For example, HRS’ data consumers span different personas, from technical users such as data analysts, software engineers, and data engineers, to nontechnical users. For technical users proficient in writing SQL, the company standardizes with Amazon Athena, a serverless interactive SQL engine. With Athena, HRS reduces time to explore data from weeks to minutes. To help these users query and visualize their data, as well as build dashboards, HRS uses open source Redash, secured with single sign-on (SSO) and only available within the HRS network. With this, new joiners and experience users can get access to their data from day one without accessing the AWS console; however, some of our data platform users wanted more. So, we asked ourselves, “What is more?”
Through the AWS ad hoc analysis with Athena and Redash, HRS discovered their internal data platform customers were finding insights but were struggling to operationalize and share these with others in the business. They wanted to automate their process, putting the latest data in the hands of decision makers by making it available through our MicroStrategy self-service reporting. However, operationalizing this work by creating new data pipelines can become a lot of work for a small, central data platform team. How could we reduce the time taken to deliver insights to our data consumers without an overwhelming engineering effort to build and maintain data pipelines?
At this point, HRS reached out to AWS and worked with the Data and Analytics AWS Professional Services team. Welcome AWS Orbit Workbench.
Introducing AWS Orbit Workbench
AWS Orbit Workbench is an open source framework for building a data analytics workbench on AWS. You can build a workbench that gives you access to the right tools for your use cases, either through the out-of-the-box integrations or through the extensible architecture. You also have control over the underlying infrastructure, whether your work needs extra graphics processing units (GPUs) or extra memory, or you could save money by running on the newest Graviton2 processors. AWS Orbit Workbench is built on Kubernetes, using the Amazon Elastic Kubernetes Service (Amazon EKS), making it easy to deploy, scale, and rapidly iterate.
As described, the HRS data platform team wanted a data analytics workbench in AWS with a unified experience that allowed the company’s internal data platform users to rapidly iterate on their data ideas. HRS’ starting point was standardizing data exploration and scheduling Jupyter notebooks to run on AWS Orbit Workbench. The data platform team wanted to remove the barrier data enthusiasts faced when operationalizing their analytic workloads by removing the need for HRS to build data pipelines.

Authoring, Scheduling Analytics Workloads in Jupyter Notebooks
When HRS started the data platform project, the central team was responsible for managing and maintaining the analytic workloads for all of HRS. A handful of data experts became a bottleneck serving data needs for more than 600 people. This approach did not scale; not only was the team busy with data engineering work, they also had to respond to tickets, emails, and instant messages as they worked with the business to define and validate requirements.
With AWS Orbit Workbench, HRS could start implementing its data platform vision: Decentralize responsibility for analytics innovation and centralize platform expertise. Data enthusiasts can now operationalize their analytics workloads without handoffs to another team. The data platform team supports the scalable infrastructure running on Amazon Elastic Kubernetes Service (EKS), freeing product teams to innovate on data without worrying about managing data analytics infrastructure. Software engineers, data analysts and data scientists simply login through the companywide SSO and they are immediately ready to build. Let’s go through a simple use case to show you how it works.
Use Case
A business team need to create a report that shows their key metrics. Decision makers would like to visualize this data daily. They also want to be able to look back in time for historical views on specific dates.
Approach
This use case was assigned to one of HRS’ analysts, Alice, who is very proficient in SQL, but isn’t an expert in cloud infrastructure. She quickly prototypes a report using the company’s web-based SQL client, Redash, connected through Athena to HRS’ data lake (managed by AWS Lake Formation). Once the prototype is completed, she shares the link with a member of the decision-making team, Angela, who logs into Redash through HRS SSO and validates the numbers. The next step is to make this data available daily for decision making.
In the past, Alice had to create a ticket with the central data team, which had a long backlog of similar tickets. She then needed to create a solution design document that would be verified by an architect. After verification, Alice would have to wait for her request to be prioritized before it was worked on. The lead time to deliver analytic workloads was huge. But with AWS Orbit Workbench, the story is completely simplified.
Alice simply logs into the AWS Orbit Workbench environment, provisioned for her team, through HRS SSO. On successful login, she launches a notebook server.
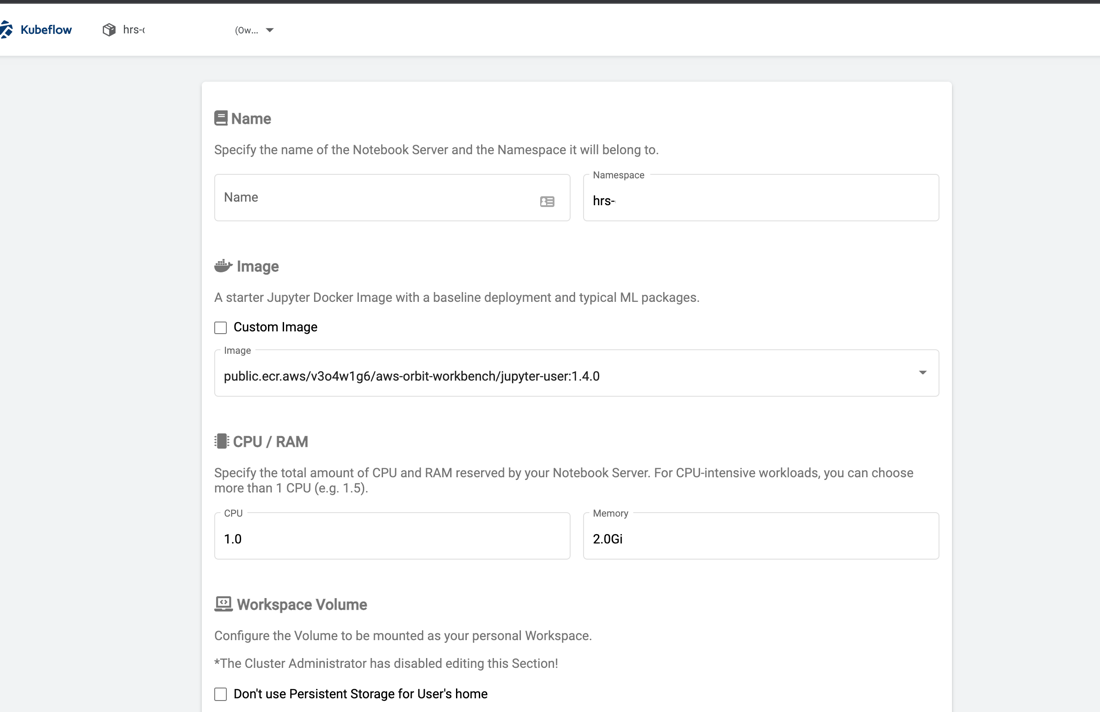
Once the notebook server has launched, she is able to open JupyterHub and start working from a Jupyter notebook. In there, Alice sees example Jupyter notebooks that show how to query the data lake with SQL through Amazon Athena.
Alice also sees an example notebook on how to schedule her notebook to run on a daily basis. With the notebook scheduled and executed successfully, the data is immediately available in the data lake, and she is able to access the report using Redash but more importantly, with MicroStrategy our BI tool where Angela can create MicroStrategy Dossiers.
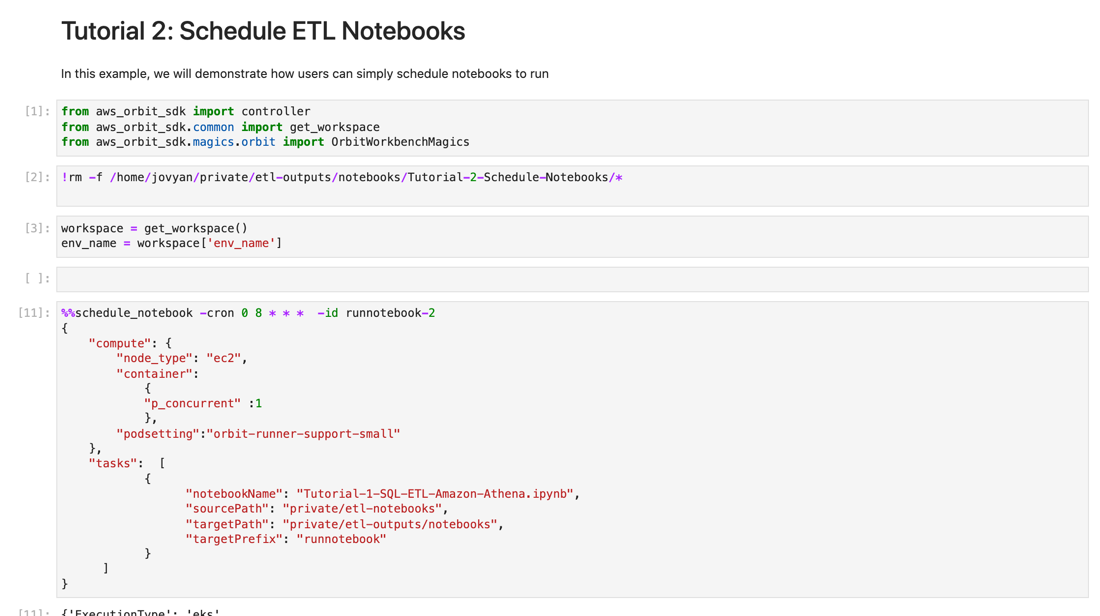
Without any tickets, extensive solution design document or prioritization discussions, Alice is able to operationalize report in a few hours as opposed to weeks. She also did not have think about any infrastructure details or how her analytics workload would run.
To further complete the data workload cycle, Alice logs into the HRS data discovery tool to document information about this newly created data asset. This simplifies work for other colleagues who may want to leverage the data in future.
Next Steps
For HRS, this is only the beginning. With AWS Orbit Workbench being an integral part of our data platform, the company is now able to provide a simplified experience from data exploration to productionizing data workloads. In addition, HRS is providing a paved path for its data analysts and data enthusiasts within the company to consume data and become more data-driven. In the coming months, HRS hopes to drive the adoption of AWS Orbit Workbench first with its central data analysts and then product teams with analytic needs. Here is what one HRS data analyst had to say after first glance.
“AWS Orbit is the perfect companion, as it helps to create tables/reports that can be created based on individual SQL scripts and can be scheduled. Finally, using this tool, we are able to make data available via Redash or IDeAS and replace on-premise workflows.” – Data Analyst, HRS Group
However, HRS is far from done. There is still a lot of work to do to improve development experience and ease of adoption. The company wants a better scheduling experience directly from JupyterHub UI, better cost allocation and transparency on compute resource usage, and observability (monitoring and alerting) for failed jobs. These, and many more, useful improvements will help make notebooks a common and easy entry point for data consumption through cross-functional development at HRS Group.

Olalekan Elesin
Olalekan Elesin is an engineer at heart, with a strong technical background and an obsession for solving customer problems. He has a proven record of leading successful machine learning projects as a data science engineer and a product manager, including using Amazon SageMaker to deliver an AI enabled platform for Scout24, which reduced productionizing ML projects from at least 7 weeks to 3 weeks. He is currently the Director, Data Platform at HRS Group, where he leads teams federating data usage and building intelligent products with advanced analytics. He has given several talks across Germany on building machine learning products on AWS, including Serverless Product Recommendations with Amazon Rekognition. For his machine learning blog posts, he writes about automating machine learning workflows with Amazon SageMaker and Amazon Step Functions. He also works on promoting continuous deployment for automated machine learning on AWS, where he coined the word CD4AutoML – Continuous Delivery for AutoML.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.