AWS Startups Blog
Meet Cleo, the Chatbot Giving Personal Wealth Management an AI-powered Facelift

Guest post by Matt Piatkus, Data Scientist, Cleo
Our mission at Cleo is to radically improve everyone’s relationship with money. Our chatbot allows user to interact with their finances – and our features – in natural language through an app on Android and IOS or through Facebook messenger. Cleo isn’t a bank, and she doesn’t want your money. She is great at getting an overview from multiple accounts and showing you the bigger picture on your spending habits. She’s also great at translating data into meaningful, useful objectives.
Natural Language Understanding: Model Training
Cleo’s users use a casual language style to communicate with her, much as if they were talking to a friend, and it’s important that Cleo understands and responds helpfully. We use a machine learning classifier to interpret users’ intents so that Cleo can give relevant, conversational responses.
We had already built a basic classifier using regular expressions on users’ requests. We wanted to use the outcomes of this classifier as training data for a machine learning classifier, which would be more robust to typos, synonyms, and changes of wording. This approach had the disadvantage of using imperfect training data, but the advantage of having huge amounts of it with excelling coverage of our users’ requests. Because the training data was imperfect, we also built a smaller, manually classified test set to compare models.
With this strategy, we needed SageMaker to be able to train a classifier on millions of training samples. We started with SageMaker’s notebook service: a notebook hosted on a small instance for initial analysis and preprocessing code creation. The notebook uses the same environment as the final model training, minimizing deployment issues.
Having figured out the best transformations on the data, we used SageMaker’s training feature to build our classifier. This service automatically launches an instance for training, trains the model, serializes the result to S3, and then tears down the training instance. SageMaker comes with a menu of prebuilt models, and we were able to get up and running in hours with SageMaker’s Blazingtext model, a quick-to-train text classification algorithm. It’s a very cost-efficient way of training because the instance is only open for only the time it needs to be, which in turn means there’s little downside to using a powerful instance and training quickly.
Hyper-parameter training is the same but scaled up. SageMaker will start multiple instances simultaneously, train a single model on each of them, and proceed to optimize hyperparameters automatically by Bayesian search, within the limits given by the user. Although for our application most of the benefit comes from improving the training data quality, the quick hyperparameter training adds a few much-appreciated percentage points to our accuracy.
Real-time Natural Language Understanding
Of course, Cleo needs to respond to users immediately, which is where SageMaker’s automatic deployment comes in handy. Once we have a model trained, we can deploy it as a microservice, which our backend can then query.
Here’s how it works: when a user makes a request, it gets delivered to our backend. Some common requests such as single words or emojis are handled there and then, but more complicated language is sent simultaneously to two APIs owned by our data science team. One extracts the intent from the request. For example, a user might ask a summary of their transactions or to turn on our autosave feature. A second API extracts keywords from the string, such as dates, times and merchants.
These APIs return their opinions to the backend, which then fetches the data it needs to handle the request and constructs a suitable response.
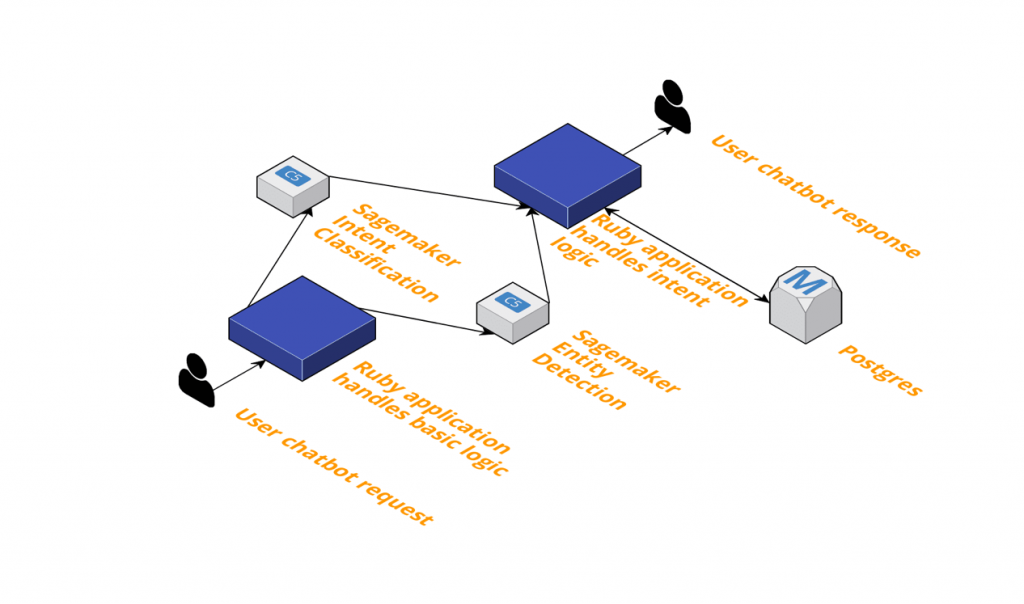
These microservices have simplified project management at Cleo. After we’ve built the tools to query the API from the backend, the data science team has no more dependencies on the developers. Data scientists are free to iterate on our models and redeploy on our own schedules. This freedom to move quickly has resulted in a much faster turnaround of models, as we’ve been able to release a new model every week since the first one was fully implemented.
Insight & Overnight Jobs: SageMaker Batch Transforms
We’re not just using SageMaker for real-time responses, though. In many cases, we have a business need to apply a model to a dataset regularly. For example, we have a segmentation of Cleo users built using a clustering algorithm, and we want to segment new users soon after they join. For this we use the SageMaker batch transform service on a schedule.
This is a service that applies a model to data in chunks. Like the hyperparameter training, it launches multiple instances simultaneously; but on each it installs two docker containers: one with the code we want to apply to the data, and another that will pass data into the model and collate the output. The service splits the dataset across all the instances, feeds the data into the model, and combines the output back into a single file in S3.
Our analytics database is a Redshift cluster updated frequently from our primary database, so we simply extract data to S3, call SageMaker batch transform on it, and reimport into Redshift. The results of the model can then be used for visualizations, insight, or applications.
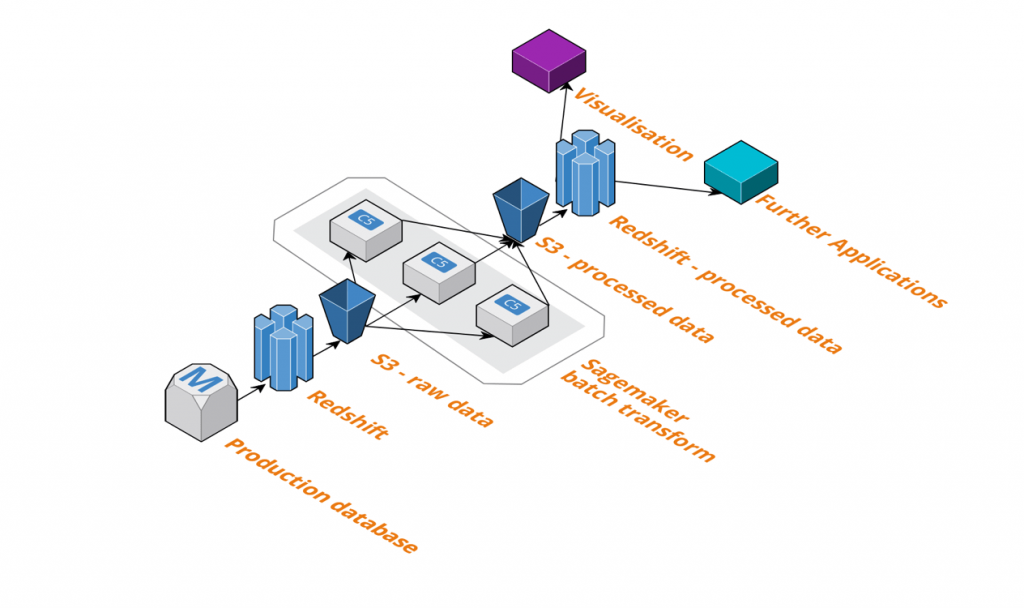
As with the model training described above, it’s a very cost-efficient service because instances are only open for as long as they’re needed.
Conclusion
As a rapidly growing startup, Cleo needs its tooling to be quick to set up, flexible, and scalable, and SageMaker has proven invaluable in achieving these goals. Its frictionless model training and deployment have allowed engineers and data scientists to focus on our users’ needs, rather than infrastructure.
