AWS Startups Blog
How Signal Media uses EC2 Spot and ECS

Guest post by Frederico Marques, Senior Site Reliability Engineer, Signal Media
Every day, Signal ingests millions of documents from a growing number of publishers, including online media, print newspapers, broadcast, regulation and legislation. Our text analytics pipeline processes these documents in real time, applying our own AI algorithms and machine learning, preparing them to be searched from our application and distributed via our alerts system.
The entire Signal platform is built on a large number of microservices running on Docker containers deployed to Amazon ECS. In fact, we run almost all of our workloads on top of several ECS clusters including ingestion, processing and consumption. With the hyper growth of our platform we have started to face several challenges, primarily on efficiency and capacity planning. We had a lot more questions than answers. What is the best way to use available capacity in a given cluster? Are we over provisioning on peak times for too long when we shouldn’t? Can we run our data pipeline at a better cost while still being able to scale and guarantee the expected service availability for our customers, 24/7? We had an interesting journey in finding answers for these questions and I would like to share how we were able to reduce up to 70% our EC2 computing costs without any impact on service uptime and scalability.
EC2 Spot instances and ECS
When we think about the running costs of ECS, what really matters is EC2 instance costs. The easy and obvious path would be to forecast future growth, using reserved instances for predictable workloads and leaving “on demand” to be only used on busy periods via autoscaling. We’ve been doing this for quite some time, but we were looking for other ways to more efficiently acquire compute capacity for our ECS clusters. One of the features of EC2 we didn’t investigate was Spot instances. These are EC2 instances offered from spare capacity at a steep discount (usually up to 90% off the “on demand” price). From our impression and to our knowledge, due to the bid price competition causing unexpected variations, there were a lot of instance terminations, making it not very well suited for web applications. However, they were acceptable for HPC batch processing jobs and general workloads where terminations wouldn’t be a problem because you could reprocess the interrupted batch later. With the announcement late last year of the EC2 spot instance price change we could observe that it has now a slow variation, with prices changing only over weeks or even months. This massively reduces price volatility. The instance price calculation is now based solely on supply and demand of available pool capacity over a given period and not on real-time market price biding. We also learned that if we are willing the pay the “on demand” price for each spot instance type, we further minimize terminations. Why not using it with ECS, then? We thought this would be a great opportunity to use it in production. Since our applications are stateless, by running each service on several containers running on different instances we were able to get less disruption of our workloads running on ECS with Spot instances.
EC2 Spot Fleet
Using EC2 Spot Fleet made our life easier as we diversified our allocation strategy by using different instance types spread on several availability zones to minimize pool exhaustion. This way, we are less likely to be affected if a given instance type becomes unavailable in a particular pool from a total of 30. This works well with ECS as it provides a layer of abstraction for containers where available CPU and memory at a cluster level is more important then what instance type we’re using. To achieve the same diversification without Spot Fleet, you would need to create one spot instance request for each type and availability zone, making things more complex to manage.
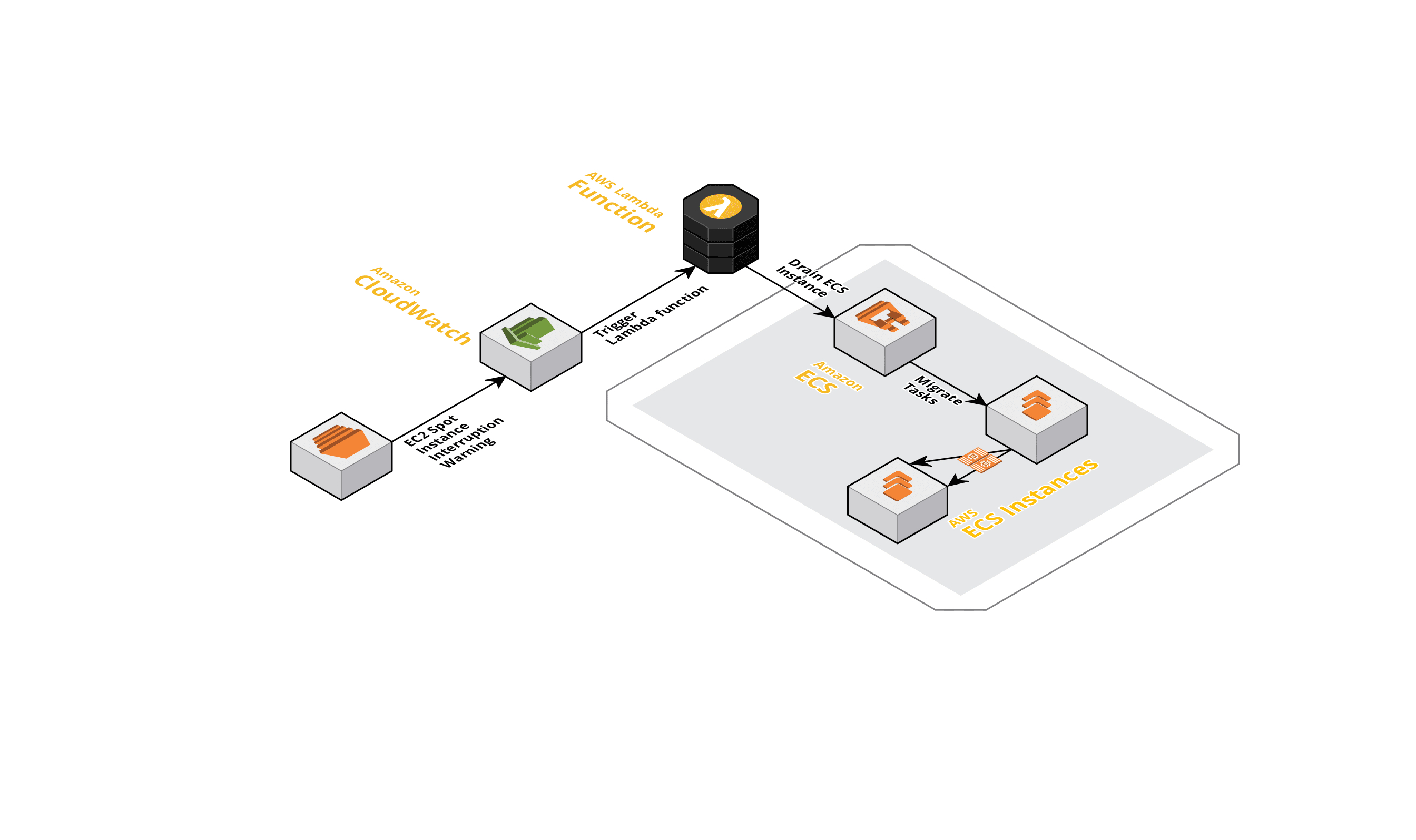
Using CloudWatch and Lambda to drain ECS instances
Still, instances are terminated from time to time so what can we do to further minimize the impact on our services? We now capture an EC2 spot instance interruption warning using a CloudWatch Event rule that triggers a Lambda function to automatically drain all running ECS tasks from the instance (if you decide to experiment and spin up a cluster using Spot through the AWS Console, there is a bash daemon providing the same functionality as our Lambda). This gives us two minutes to prevent any new tasks to run on that instance and offload all running tasks elsewhere. Once the instance gets terminated, the impact is very low. At the moment, we’re running most of our workloads on this setup with very similar stability compared to running exclusively with “on demand” instances.
Further optimizations and cost savings
We’re also continuing to optimize our reserved capacity and decided to merge and consolidate several clusters. As we are CPU bound, at peak times we can achieve 70 to 80% CPU utilization per ECS Cluster using a task deployment strategy of spreading by different availability zones and then apply binpacking by CPU. We decided to extend and simplify our deployment process by using a mix of both “on demand” and spot instances for the same Cluster allowing certain applications to run only on top of on-demand instances through a different placement constraint, so we can deploy using a specific instance type. We do this by creating a custom ECS attribute for each instance, ec2.instance-spot. It gets written into the instance user data via the launch specification at the Spot Fleet Request (set to true) and Autoscaling Group for “on demand” instances (set to false). By default, we deploy our services to any available spot instances, but when we need to use “on demand”, we just change the service or task definition with a placement constraint so the scheduler looks for any available instance that has the ec2.instance-spot attribute set to false. Also, having the ability to use on-demand instances together with spot instances could be useful for the times we want a backup mechanism in the unlikely event of having all of our spot pools exhausted. Nothing is perfect, though. Since we use Terraform to provision our infrastructure, the use of launch templates with EC2 Spot Fleet Request is not supported yet. This makes it more difficult to recycle your Cluster instances with a new AMI. Our customized Cluster autoscaling is not as fast as using an EC2 autoscaling group due to target changes in Spot Fleet taking more time to complete. Nevertheless, we’re happy with the results.
Conclusion
The new EC2 Spot pricing has been a true game changer. We don’t need to deal with the complexity of optimizing bidding actions to overcome reliability trade-offs. Also, the introduction of EC2 Spot Fleet makes it even easier to manage different pools of instances and types and maintain target capacity by replacing terminated instances. There is great potential when using EC2 Spot with ECS and we’re currently looking into migrating other workloads into this platform. Achieving better reliability was also possible and not overly complicated as it was done through a simple Lambda function and being able to programmatically use an API for required AWS services. This journey also led to an extremely important side benefit that will change your developer mindset. You will need to make sure you design your services to deal with failure, to be more resilient and fault tolerant. If you want to achieve maximum efficiency at scale, you will have to dig deeper and learn how to get the best out of what you’re paying for. This takes time and effort, but we believe the work we’ve done so far has been worth it, with more to come.
To know more about Signal Media, our tech team news and activities, please follow us at @SignalHQ_Tech or visit hour GitHub home.