AWS Startups Blog
Amazon DynamoDB Storage Backend for Titan: Distributed Graph Database
Today’s startups thrive in our increasingly connected world. As our world grows more complex, there is growing demand for solutions that simplify and make sense of that complexity to help drive decisions. Startups benefit from new technologies to map complex relationships between people, locations, physical items, and virtual items to identify patterns, make recommendations, predict outcomes, anticipate changes, and respond quickly to a dynamic environment. Graph databases help companies quickly navigate and learn from these relationships.
What is a Graph Database?
You might be asking yourself, “What is a graph database?” A graph database is a database where data is modeled as vertices and directed edges of a directed graph. Graphs can be stored in relational (SQL) and non-relational (NoSQL) stores. Both vertices and edges can have properties associated with them. Edges in a graph can be represented as vertex adjacency lists, or as an adjacency matrix. The diagram below depicts a simple graph of relationships between friends and their interests:
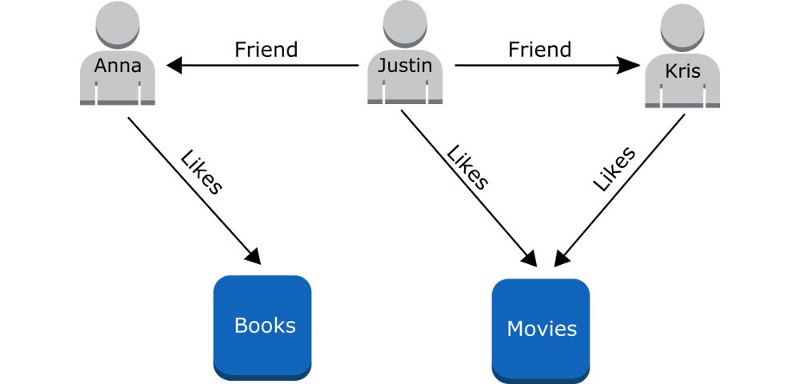
Graph databases model any link-rich domain such as social graphs, business relationships, dependencies, and many more. For example, a graph database could represent people and products as vertices, edges between people to represent friends, and edges between people and products to represent “likes.” This information could be used to generate recommendations based on products your friends like. It’s not uncommon for a startup to process graph databases containing hundreds of millions of entities, linked by billions of connections. Thus, it’s no surprise that startups must balance the graph scale and responsiveness with storage and processing capacity.
Introducing the Amazon DynamoDB Storage Backend for Titan: Distributed Graph Database
Titan is a scalable graph database abstraction on top of existing storage solutions optimized for storing and querying directed graphs containing hundreds of billions of vertices and edges released under the Apache License, version 2.0. Titan is an implementation of the Blueprints property graph with a plugin-based architecture, utilizing a variety of storage backends such as Apache Cassandra, Apache HBase, Oracle BerkeleyDB and now Amazon DynamoDB. This means you can now run your graph database on AWS without managing a massive database cluster. To put it simply:
Titan + DynamoDB = Distributed Graph Database – Cluster Host Management
Benefits of the Amazon DynamoDB Storage Backend for Titan
- AWS managed authentication and authorization keeps data secure
- Configurable table prefixes let you create multiple graphs in the same geographical region
- Consistent performance with full graph traversals with rate limited table scans
- Performance and graph density flexibility with two options: single-item or multiple-item models
- Vertices support index-free adjacency, speeding up graph traversals without requiring joins
- Integrated Titan metrics and API-level DynamoDB metrics
- Compatibility with Titan 0.4.4 and 0.5.4 (at Tinkerpop 2.4 and 2.5, respectively).
- Super-node support with partitioned vertices in Titan 0.5.4
- Test graph traversals and algorithms locally and at no cost with DynamoDB Local
Data Model
The Amazon DynamoDB Storage Backend for Titan has a flexible data model so you can optimize the graph database for simplicity or scalability. Clients can configure tables to use either a single-item model or a multiple-item model.
Single-Item Model
The single-item model is optimized for graphs where the number of edges per vertex is small. A single DynamoDB item stores all values for a single key. The Titan key is stored as a DynamoDB hash key, each column is stored as attribute name and each column value is stored as an attribute value. Using the single-item model, the graph above would look the following way on DynamoDB:

The single-item model has the smallest storage footprint and this model is ideal for lower-complexity graphs.
Multiple-Item Model
The multiple-item model stores a single key using multiple DynamoDB items. The Titan key is stored as a DynamoDB hash key and each column is stored in the range key of a separate DynamoDB item. Individual column-value pairs are stored in separate DynamoDB items.
This implementation uses more memory than the single-item data model, but isn’t limited by DynamoDB’s 400kb item size limit. Graphs backed by DynamoDB tables using the multiple-item data model use the Query API instead of the GetItem API to get the necessary multiple column-value pairs. Using the multi-model the graph above would appear like this on DynamoDB:

Getting Started
The following code creates a sample Titan graph to help you get started. All you need to do is check out the repository on GitHub, run mvn install, start DynamoDB Local with mvn test -Pstart-dynamodb-local, start Gremlin with mvn test -Pstart-gremlin, and execute the following Gremlin commands:
1 conf = new BaseConfiguration() 2 conf.setProperty(“storage.backend”, “com.amazon.titan.diskstorage.dynamodb.DynamoDBStoreManager”) 3 conf.setProperty(“storage.dynamodb.client.endpoint”, “http://localhost:4567") 4 graph = TitanFactory.open(conf) 5 graph.makeLabel(“is”).oneToOne().make() 6 graph.makeLabel(“on”).oneToMany().make() 7 graph.commit() 8 titan = graph.addVertex(null, [name:”titan”]) 9 dynamodb = graph.addVertex(null, [name:”dynamodb”]) 10 awesome = graph.addVertex(null, [name:”awesome”]) 11 graph.addEdge(titan, dynamodb, “on”) 12 graph.addEdge(titan, dynamodb, “on”) 13 graph.addEdge(dynamodb, awesome, “is”) graph.commit()
Alternatively, you can launch a Titan/Rexster CloudFormation stack with the DynamoDB Storage Backend for Titan installed, and follow steps 5–13 above to achieve the same result. Wait for your stack to finish launching, as creating tables and provisioning an EC2 instance might take some time.
Scalable graph databases like Titan enable insights and recommendations for users, and allow your startup to rapidly reach world-class scale. Leveraging DynamoDB as a scalable storage backend means you’ll have more time to focus on your customer instead of thinking about storage clusters.
Resources
- Graph Databases by Ian Robinson, Jim Webber, and Emil Eifrem
- Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement by Eric Redmond and Jim R. Wilson
- NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence by Pramod J. Sadalage and Martin Fowler
Summary
Titan is a distributed graph database that now supports DynamoDB. To learn more, visit the project page on GitHub.