AWS Startups Blog
Serverless Architectures with Java 8, AWS Lambda, and Amazon DynamoDB — Part 2
In this post, I continue the discussion by presenting an implementation of a back end service to support the example use case of the first post. As you might recall, the use case involves a company that is building out a new API backed by DynamoDB to access a catalog of sports events.
Using Java 8 with AWS Lambda
For my implementation, I developed Lambda functions for the Lambda Java 8 runtime. The release of the Java 8 runtime for Lambda marked an important step in the evolution of the Lambda service. Many companies of all sizes, from startups to multinational enterprises, use JVM-based stacks in their products.
There are many reasons for this, including the ability to highly tune applications running on a JVM, access to extensive tooling for developing and working with JVM-based applications, and a vast supporting ecosystem that includes frameworks and libraries that enable developing JVM-based applications in just about any programming paradigm, from imperative to functional to reactive.
Although there are several possible ways to structure a Java 8 code base for Lambda, the code base for this post is structured as a single code base that combines multiple Lambda function handlers in a single source control repository. Combining handlers is useful for logically grouping together Lambda functions that jointly would be considered a microservice if developed with a traditional server-based approach, and deployed and run in a Java servlet container such as Tomcat or Jetty. Another rationale for the combined approach is the convenience of code and deployment management that results from managing one repository rather than many.
Prerequisites and Setup
The primary prerequisite for running the code for this example is to create an EVENT table in DynamoDB. Using the Amazon DynamoDB console at https://console.aws.amazon.com/dynamodb or the AWS CLI, create the table with the keys and indexes specified in Part 1 of this blog post series for the EVENT table. When creating sample data to populate the table, keep in mind that the Event POJO (discussed later in the post) also supports the following attributes in addition to those specified previously: eventId (Number), sport (String), country (String).
All of the code referenced in this blog post series can be found on GitHub at https://github.com/awslabs/lambda-java8-dynamodb. After you create the DynamoDB table, clone the example code base using the git clone command. Then build it with Maven using the mvn package command (if you don’t have Maven installed already, you need to install it now). Upload the resulting JAR file via the AWS console or CLI to each Lambda function, with one Lambda function created per handler in the code base. Because there are six handlers, you should create six Lambda functions. For a quick walkthrough that shows you how to create a Lambda function if you haven’t done so before, see the Getting Started guide.
Code Base Features
The example code base demonstrates several features of the AWS SDK for Java. In connection with DynamoDB, one of the most important features of the SDK is the convenience provided by DynamoDBMapper, an object mapper for DynamoDB. Like an ORM library such as Hibernate for relational databases, DynamoDBMapper enables developer-friendly, shorthand domain-object interactions with a DynamoDB table via simple methods, which can be used for CRUD operations instead of having to construct queries with “raw” long-form API calls.
More specifically, to use DynamoDBMapper, for each domain object that corresponds to a DynamoDB table, create a POJO that comprises fields and accessors. Annotations are included on the POJO’s fields or getters to indicate whether they are ordinary attributes, or hash or sort keys for the table itself or the table index. In the example code base, the relevant POJO is the Event class, as shown in the following code snippet:
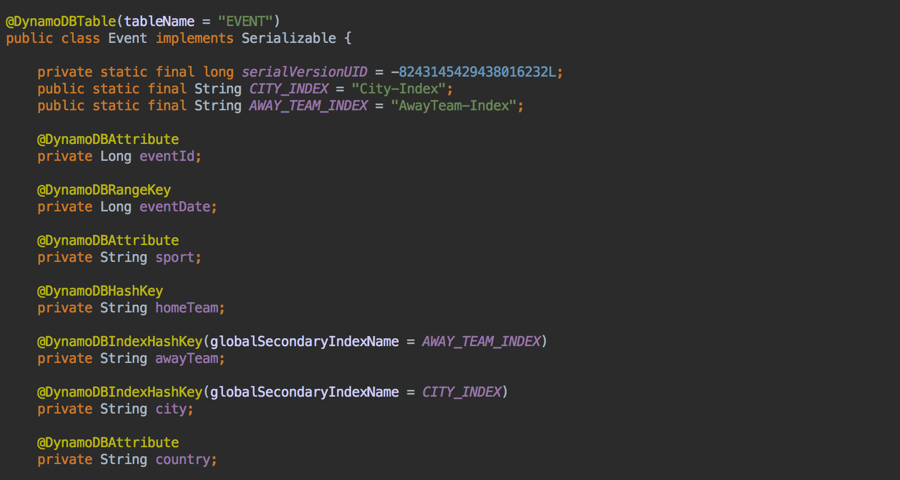
Given this POJO, you can perform CRUD operations for a particular Event object using simple methods. These methods will be of the following form: mapper.save(…), mapper.delete(…), mapper.load(…), etc., where mapper is the DynamoDBMapper object and the method arguments are the event object or team name and event date.
The DynamoDBMapper object and the DynamoDB client are embedded in a reusable DynamoDBManager singleton class. This manager was not created using any third-party frameworks. Although it is possible to use Spring or other dependency injection frameworks with Lambda functions, consider keeping Lambda functions as lightweight as possible. Java 8 itself has obviated the need in some cases for common external libraries, such as Joda-Time and libraries that provide the equivalents of the new language features in Java 8. The AWS SDK for Java also provides many helpful features, such as serialization of objects returned by Lambda functions, as will be seen shortly.
In keeping with good object-oriented design principles for persistence-related code, CRUD operations for the API are described in a data access object (DAO) interface, specifically, the EventDao interface. Business logic in the rest of the API can rely on this interface, which is implemented by the DynamoDBEventDao class with code specific to DynamoDB.
To trace through how an API call is implemented, start with any Lambda function handler method. In the EventFunctions class, which has one Lambda handler method per API call, the API call for fetching events by city is represented by the getEventsForCity method. As shown in the snippet below, this method simply validates the input and returns a list of events, which Lambda itself conveniently serializes into JSON without requiring any effort on the developer’s part.
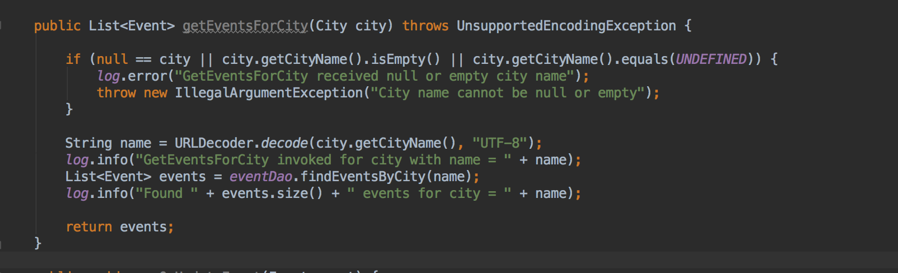
Most of the real work of the API call is done by the DynamoDBEventDao class, as shown by the next code snippet:
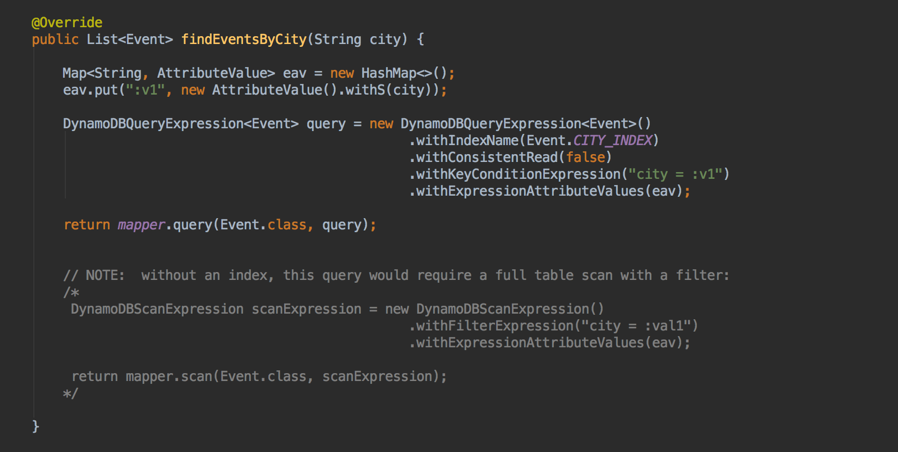
The specific CRUD method invoked, findEventsByCity, performs a query against a GSI based on city name, rather than querying the table itself. One point to keep in mind is that queries against a GSI cannot be strongly consistent, and this must be specified when making a GSI query. As a result, a GSI query might not return up-to-date data. However, as noted in the code comment in the snippet, without use of the GSI, an inefficient full-table scan would be needed to gather the result set. Also, for the example use case of this blog post series, the risk of queries returning stale data is mitigated by the fact that the event catalog is not frequently updated during a day.
Another helpful feature of the AWS SDK for Java in relation to Lambda functions is its integration of the log4j logging library. Using the log4j library, you can enable logging at multiple levels — such as debug, info, and error — to pinpoint issues and provide analytics. Logs generated by log4j for Lambda functions are readily accessible for viewing by going to the Lambda console, selecting the Lambda function at issue, and choosing View Logs in CloudWatch under the Monitoring tab. For more information about the special features of the AWS SDK for Java as they relate to authoring Lambda functions, see Programming Model for Authoring Lambda Functions in Java in the AWS Lambda Developer Guide.
Conclusion
Using Lambda together with DynamoDB, you can rapidly build an API backed by a robust and scalable data store without ever having to be concerned with deploying and managing servers. When you develop Lambda functions using the Java 8 runtime, you can leverage the powerful and vast Java ecosystem, as well as the convenient features of the AWS SDK for Java.
With respect to DynamoDB, this post just scratched the surface of the available SDK features, which include many features not discussed here. These other features include support for optimistic locking with DynamoDBMapper, and a separate transactions library that you can use to wrap related CRUD operations. Additionally, testing your DynamoDB-related code locally in your developer environment is made easy by DynamoDB Local, a local version of DynamoDB that can help you save on provisioned throughput, data storage, and data transfer fees when testing.