AWS Storage Blog
How to test drive Amazon Elastic File System
Many customers are excited about Amazon EFS because it makes it easy to run a highly scalable, highly available, and highly durable shared file system in the cloud. Within seconds, you can create an NFSv4 compliant file system and mount it to multiple (up to thousands of) Amazon EC2 instances or on-premises servers.
Amazon EFS provides a simple elastic file system for Linux-based workloads and is built to scale on demand to petabytes without disrupting applications. Amazon EFS supports a broad spectrum of use cases from highly parallelized, scale-out workloads that require the highest possible throughput to single-threaded, latency-sensitive workloads. Use cases such as lift-and-shift enterprise applications, big data analytics, web serving and content management, application development and testing, media and entertainment workflows, database backups, and container storage.
I have the unique privilege to work with customers as they evaluate, design, and implement storage solutions to support different applications and workloads. One theme I see with customers who are new to Amazon EFS is a lack of familiarity with advanced file system techniques. I want to share these best practices with you before you start evaluating and testing Amazon EFS. This post helps you get the most out of Amazon EFS.
Create an Amazon EFS file system
If you haven’t already done so, create an Amazon EFS file system using the AWS Management Console or AWS Command Line Interface (CLI). Complete steps 1, 2, and 3 in the Getting Started with Amazon Elastic File System topic. After a few minutes, you should be logged in to an Amazon EC2 instance that has an Amazon EFS file system mounted.
Test drive
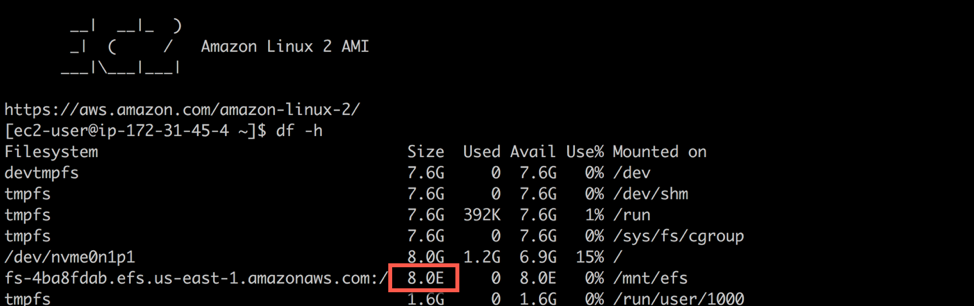
The first thing that I like to show customers after they mount a file system is its size—the number of 1K-blocks available. Run df at the command line of the EC2 instance where the EFS file system is mounted. It should return something similar to what you see below.

If you’re like me, you have a hard time converting a nine quadrillion (16-digit) value into something understandable. So, a quick df -h command makes it easier to comprehend. It appears to your applications as if you have >8 EB of available storage but Amazon EFS is elastic, automatically growing and shrinking as you add and remove data, and you only pay for the storage you are actually using (in this case, zero). No longer do you need to worry about provisioning storage and you only pay for what you use.
Because it’s easy to get up and running with Amazon EFS, you may want to dive in and evaluate how Amazon EFS performs as quickly as possible. A common test I see some customers use to evaluate Amazon EFS performance is a “touch” test to generate lots of zero-byte files. I’ve seen this written in Perl, Python, Java, and other languages.
For this post, use a bash script to see how fast you can generate 1024 files. Run the following command on your EC2 instance, making sure that you change the path to your mounted Amazon EFS file system.
time for i in {1..1024}; do
sudo touch /mnt/efs/deleteme.$i;
done;How long did it take? In my test, it took 16.808 seconds to generate 1024 files on Amazon EFS.

If you’re thinking that this took an unusually long time to generate 1024 zero-byte files, double-check the command to make sure it is correct. After deleting the first set of 1024 zero-byte files, run the command again. What are the results? They’re pretty much the same.

If you’re still thinking that this is a long time to generate 1024 zero-byte files, you can compare it to another storage platform. Change the command and run it against the Amazon EBS volume mounted to the instance. Run the following command, making sure that you change the path to use an Amazon EBS volume. In this example, I write to the ec2-user home directory.
time for i in {1..1024}; do
sudo touch ~/deleteme.$i;
done;How long did it take? In my test, it took 5.112 seconds to generate 1024 zero-byte files on EBS. This is the root volume, which is a 10-GB gp2 EBS volume. In this example, the operation writing to EBS is 3.28x faster when compared to EFS.

In cases like this, I like to play with different what if scenarios. What if you re-wrote the command to use multiple threads? This would allow you to generate files in parallel. Enter GNU Parallel, which is an open-source shell tool for executing serial operations in parallel. It was added to the Amazon Linux repository so a sudo yum install parallel -y command installs it on Amazon Linux 2, after installing and enabling the EPEL rpm package. For more information, see GNU Parallel.
Run the following command, installing GNU Parallel and generating 1024 zero-byte files using multiple threads.
time seq 1 1024 | sudo parallel --will-cite -j 32 touch
/mnt/efs/deleteme2.{};
By re-writing the command to use 32 jobs (or 32 threads), you can generate the same 1024 zero-byte files in only 8.647 seconds, which is a 94% improvement.
What if you re-wrote the multi-threaded command to write to multiple directories? Each thread writes to a separate directory. This spreads the write operations across multiple inodes.
For those unfamiliar with inodes, an inode is a Unix-style data structure that describes file system objects, like files and directories. Inode contention occurs when multiple threads are attempting to update the same inode, which can be more evident in network file systems due to network latencies. Run the following command to generate 1024 zero-byte files using 32 threads, each thread generating 32 files in its own directory. Thirty-two files in 32 directories totaling 1024 files.
sudo mkdir -p /mnt/efs/{1..32}
time seq 1 32 | sudo parallel --will-cite -j 32 touch
/mnt/efs/{}/deleteme3.{1..32};
By re-writing the command to use 32 jobs (or 32 threads), and having each thread generate files in its own directory, you can generate 1024 zero-byte files in only 0.776 seconds. This is 21x faster than the first single-threaded, single-directory test.
Now, what if the same file system is mounted to 2, 10, 100, or 1000 Amazon EC2 instances? How many files can be generated on a file system that supports open-after-close consistency, data durability across multiple storage servers and multiple Availability Zones, and high availability engineered with no single points of failure?
Next steps
This is just one test you can do to effectively evaluate and test drive Amazon EFS. To learn more about its performance characteristics, I encourage you to walk through the Amazon EFS Tutorial on GitHub. The tutorial goes beyond the test drive I just did and shows more examples of the benefits of parallelism. It also demonstrates how I/O size, EC2 instance type, and different file transfer tools have a significant impact on performance. These techniques are also used by AWS DataSync to improve data transfer performance to and from EFS file systems.
To read more about GNU Parallel, see “GNU Parallel – The Command-Line Power Tool” in The USENIX Magazine, February 2011.
Summary
Amazon EFS file systems are distributed across an unconstrained number of storage servers, allowing massively parallel access to file system objects. This distributed design avoids the bottlenecks and constraints inherent to traditional file servers.
In this test drive, I was able to use these benefits of Amazon EFS. I reduced the time that it took to generate 1024 zero-byte files from 16.808 seconds to 0.776 seconds, which is a 2100% improvement.

In this post, I demonstrated just two recommendations. You can use them to better take advantage of the distributed data storage design of Amazon EFS and achieve massively parallel access to file system data.
The first was to access EFS in parallel using multiple threads. The second was to access multiple directories or inodes in parallel using multiple threads. Other recommendations to help you better understand and leverage the distributed design of EFS are included in the Amazon EFS Tutorial. I look forward to providing more posts on Amazon EFS, FSx for Windows File Server, and FSx for Lustre.