AWS News Blog
Welcoming Amazon Rekognition Video: Deep-Learning Based Video Recognition

|
It was this time last year during re:Invent 2016 that Jeff announced the Amazon Rekognition service launch. I was so excited about getting my hands dirty and start coding against the service to build image recognition solutions. As you may know by now, Amazon Rekognition Image is a cloud service that uses deep learning to provide scalable image recognition and analysis. Amazon Rekognition Image enables you to build and integrate object and scene detection, real-time facial recognition, celebrity recognition, image moderation, as well as, text recognition into your applications and systems.
The Amazon Rekognition Image service was created by using deep learning neural network models and was based on the same technology that enables Prime Photos to analyze billions of images each day. At the time of Rekognition’s release, its primary focus was providing scalable, automated analysis, search, and classification of images. Well that all changes today as I am excited to tell you about some additional features the service now has to offer.

Hello, Amazon Rekognition Video
Say hello to my new friend, Amazon Rekognition Video. Yes, of course, I started to use the Scarface movie reference and write “Say hello to my little friend”. But since I didn’t say it, you must give me a little credit for not going completely corny. Now that that’s cleared up, let’s get back to discussing this exciting new AI service feature; Amazon Rekognition Video.
Amazon Rekognition Video is a new video analysis service feature that brings scalable computer vision analysis to your S3 stored video, as well as, live video streams. With Rekognition video, you can accurately detect, track, recognize, extract, and moderate thousands of objects, faces, and content from a video. What I believe is even cooler about the new feature is that it not only provides accurate information about the objects within a video but it the first video analysis service of its kind that uses the complete context of visual, temporal, and motion of the video to perform activity detection and person tracking. Thereby using its deep-learning-based capabilities to derive more complete insights about what activities are being performed in the video. For example, this service feature can identify that there is a man, a car, and a tree in the video, as well as, deduce that the man in the video was running to the car. Pretty cool, right! Just imagine all of the possible scenarios that this functionality can provide to customers.
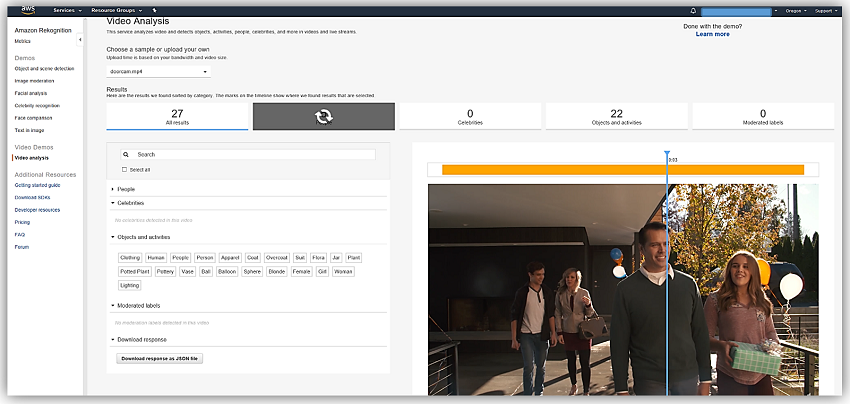
The process of conducting video analysis using the asynchronous Amazon Rekognition Video API is as follows:
- A Rekognition Video Start operation API is called on .mp4 or .mov video. Please note videos must be encoded with a H.264 codec. The Start operation APIs are as follows:
- StartPersonTracking
- StartFaceDetection
- StartLabelDetection
- StartCelebrityRecognition
- StartContentModeration
- Amazon Rekognition Video processes video and publishes the completion status of the start operation API request to an Amazon SNS topic.
- You retrieve the notification of the API completion result by subscribing an Amazon SQS queue or AWS Lambda function to the SNS topic that you specify.
- Call the Get operation API associated with the start operation API that processed the video using the JobID provided in the SNS notification. The JobID is also provided to you as a part of the Start API response as well.The Get operation APIs are:
- GetPersonTracking
- GetFaceDetection
- GetLabelDetection
- GetCelebrityRecognition
- GetContentModeration
- Retrieve the results of the video analysis via JSON returned from the Get operation API and a pagination token to the next set of results if applicable.
You can leverage the video analysis capabilities of Amazon Rekognition Video by using the AWS CLI, AWS SDKs, and/or REST APIs. I believe that there is no better way to learn about a new service than diving in and experiencing for yourself. So let’s try it out!
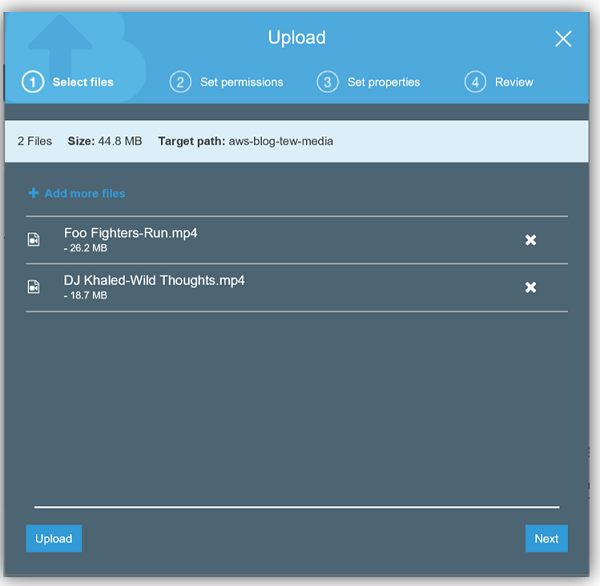
I’ll start by uploading two music videos in .mp4 file format to my S3 bucket of songs in rotation on my playlist; Run by Foo Fighters and Wild Thoughts by DJ Khaled. Hey, what can I say, my musical tastes are broad and diverse.
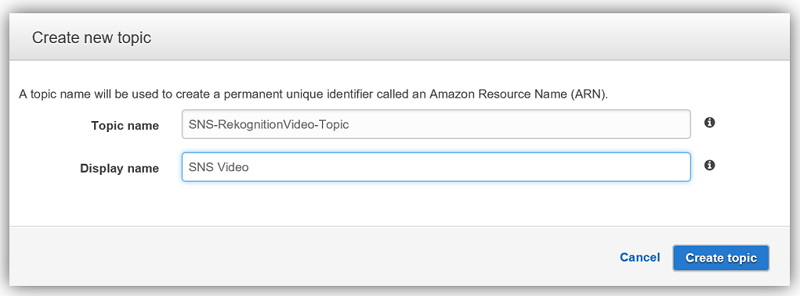
I’ll create a SNS topic for notifications from Rekognition Video and a SQS queue to receive notifications from the SNS Topic.
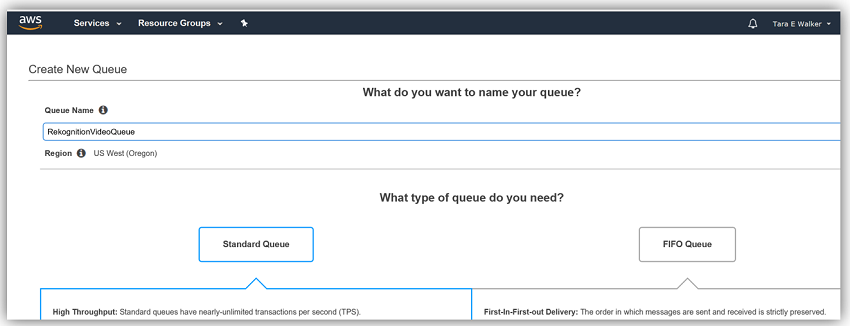
Now I can subscribe my SQS Queue, RekognitionVideoQueue, to my SNS Topic, SNS-RekogntionVideo-Topic.
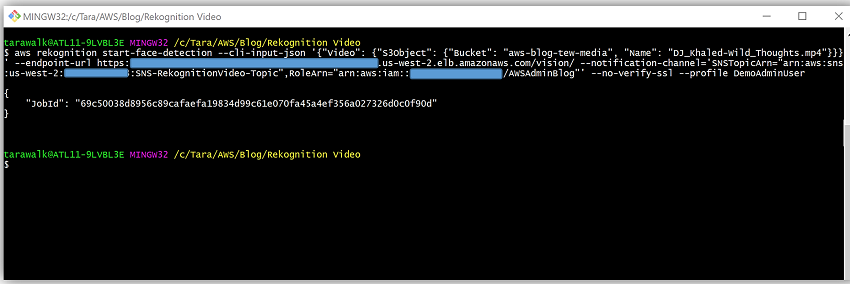
Now, I’ll use the AWS CLI to call the start-face-detection API operation on my video, DJ_Khaled-Wild_Thoughts.mp4, and obtain my JobId from the API response.
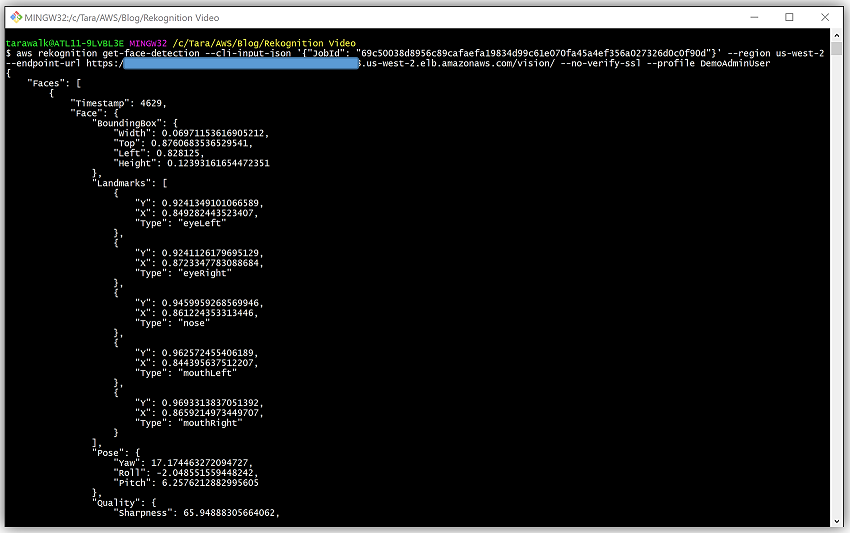
Once I have been notified that a message was received from the SNS Topic to my RekognitionVideoQueue SQS queue, and Status in that message is SUCCEEDED, I can call the get-face-detection API operation to get the results of the video analysis with the JobId.
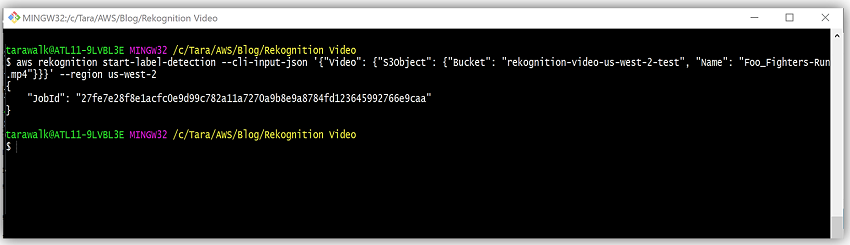
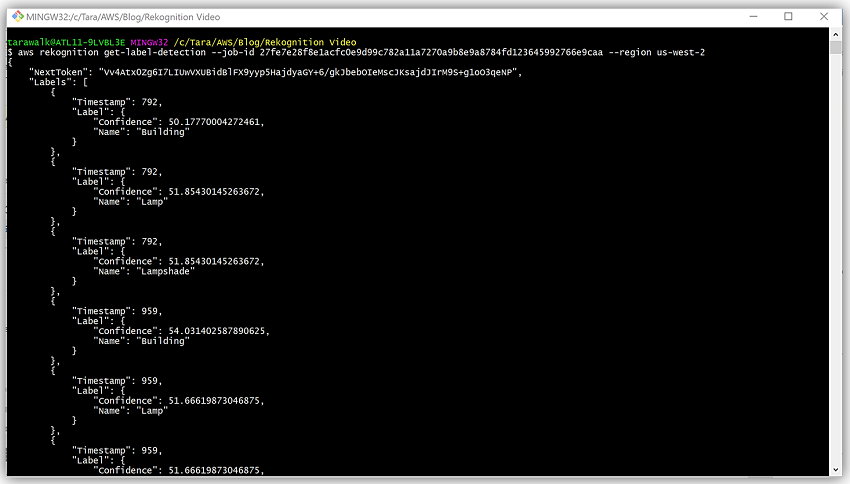
I can, also, conduct video analysis on my other video, Foo_Fighters-Run.mp4, to obtain information about the object detected in the frames of the video by calling the start-label-detection and get-label-detection API operations.
Summary
Now with Rekognition Video, video captured with cell phones, cameras, IoT video sensors, and real-time live stream video processing can be used to create scalable, high accuracy video analytics solutions. This new deep-learning video feature will automate all the tasks necessary for detection of objects, faces, and activities in a video, and with the integration of other AWS Services, you can build robust media applications for varying workloads.
Learn more about Amazon Rekognition and the new Rekognition Video capability by checking out our Getting Started page or the Rekognition documentation.
– Tara