AWS Compute Blog
Applying the Twelve-Factor App Methodology to Serverless Applications
The Twelve-Factor App methodology is twelve best practices for building modern, cloud-native applications. With guidance on things like configuration, deployment, runtime, and multiple service communication, the Twelve-Factor model prescribes best practices that apply to a diverse number of use cases, from web applications and APIs to data processing applications. Although serverless computing and AWS Lambda have changed how application development is done, the Twelve-Factor best practices remain relevant and applicable in a serverless world.
In this post, I directly apply and compare the Twelve-Factor methodology to serverless application development with Lambda and Amazon API Gateway.
The Twelve Factors
As you’ll see, many of these factors are not only directly applicable to serverless applications, but in fact a default mechanism or capability of the AWS serverless platform. Other factors don’t fit, and I talk about how these factors may not apply at all in a serverless approach.
| I. | Codebase |
| II. | Dependencies |
| III. | Config |
| IV. | Backing services |
| V. | Build, release, run |
| VI. | Processes |
| VII. | Port binding |
| VIII. | Concurrency |
| IX. | Disposability |
| X. | Dev/prod parity |
| XI. | Logs |
| XII. | Admin processes |
I. Codebase
One codebase tracked in revision control, many deploys
A general software development best practice is to have all of your code in revision control. This is no different with serverless applications.
For a single serverless application, your code should be stored in a single repository in which a single deployable artifact is generated and from which it is deployed. This single code base should also represent the code used in all of your application environments (development, staging, production, etc.). What might be different for serverless applications is the bounds for what constitutes a “single application.”
Here are two guidelines to help you understand the scope of an application:
- If events are shared (such as a common Amazon API Gateway API), then the Lambda function code for those events should be put in the same repository.
- Otherwise, break functions along event sources into their own repositories.
Following these two guidelines helps you keep your serverless applications scoped to a single purpose and help prevent complexity in your code base.
II. Dependencies
Explicitly declare and isolate dependencies
Code that needs to be used by multiple functions should be packaged into its own library and included inside your deployment package. Going back to the previous factor on codebase, if you find that you need to often include special processing or business logic, the best solution may be to try to create a purposeful library yourself. Every language that Lambda supports has a model for dependencies/libraries, which you can use:
- Node.js: npm (docs)
- Python: pip (docs)
- Java: maven (docs)
- C#: NuGet (docs)
- Go: Go get packages (docs)
You’ll want to automate this with a CI/CD process, which I talk about later in this post.
III. Config
Store config in the environment
Both Lambda and API Gateway allow you to set configuration information, using the environment in which each service runs.
In Lambda, these are called environment variables and are key-value pairs that can be set at deployment or when updating the function configuration. Lambda then makes these key-value pairs available to your Lambda function code using standard APIs supported by the language, like process.env for Node.js functions. For more information, see Programming Model, which contains examples for each supported language.
Lambda also allows you to encrypt these key-value pairs using KMS, such that they can be used to store secrets such as API keys or passwords for databases. You can also use them to help define application environment specifics, such as differences between testing or production environments where you might have unique databases or endpoints with which your Lambda function needs to interface. You could also use these for setting A/B testing flags or to enable or disable certain function logic.
For API Gateway, these configuration variables are called stage variables. Like environment variables in Lambda, these are key-value pairs that are available for API Gateway to consume or pass to your API’s backend service. Stage variables can be useful to send requests to different backend environments based on the URL from which your API is accessed. For example, a single configuration could support both beta.yourapi.com vs. prod.yourapi.com. You could also use stage variables to pass information to a Lambda function that causes it to perform different logic.
IV. Backing Services
Treat backing services as attached resources
Because Lambda doesn’t allow you to run another service as part of your function execution, this factor is basically the default model for Lambda. Typically, you reference any database or data store as an external resource via HTTP endpoint or DNS name. These connection strings are ideally passed in via the configuration information, as previously covered.
V. Build, release, run
Strictly separate build and run stages
The separation of build, release, and run stages follows the development best practices of continuous integration and delivery. AWS recommends that you have a CI &CD process no matter what type of application you are building. For serverless applications, this is no different. For more information, see the Building CI/CD Pipelines for Serverless Applications (SRV302) re:Invent 2017 session.

An example minimal pipeline (from presentation linked above)
VI. Process
Execute the app as one or more stateless processes
This is inherent in how Lambda is designed so there is nothing more to consider. Lambda functions should always be treated as being stateless, despite the ability to potentially store some information locally between execution environment re-use. This is because there is no guaranteed affinity to any execution environment, and the potential for an execution environment to go away between invocations exists. You should always store any stateful information in a database, cache, or separate data store via a backing service.
VII. Port Binding
Export services via port binding
This factor also does not apply to Lambda, as execution environments do not expose any direct networking to your functions. Instead of a port, Lambda functions are invoked via one or more triggering services or AWS APIs for Lambda. There are currently three different invocation models:
- Synchronous
- Asynchronous
- Stream-based
Each has unique characteristics. For more information, see Invoking Lambda Functions.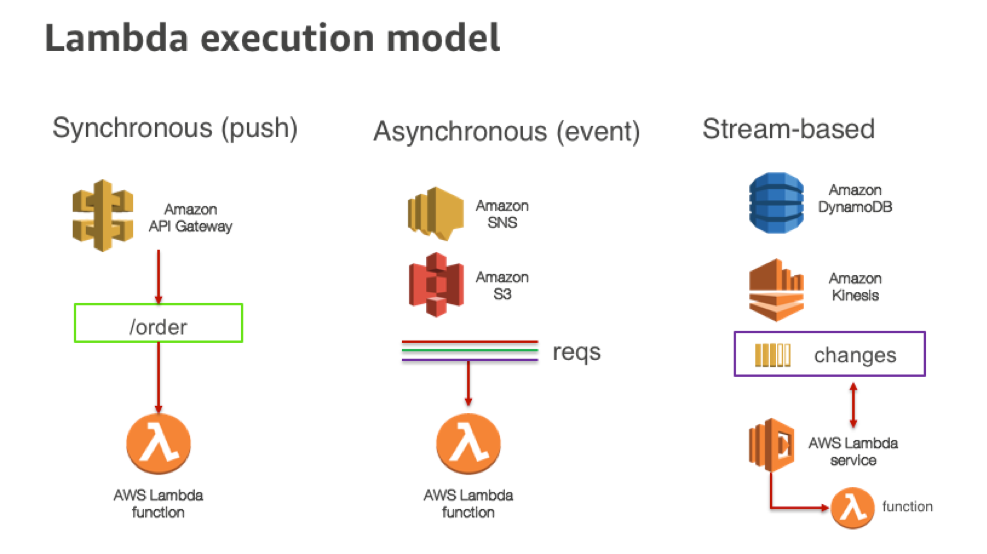
VIII. Concurrency
Scale out via the process model
Lambda was built with massive concurrency and scale in mind. A recent post on this blog, titled Managing AWS Lambda Function Concurrency explained that for a serverless application, “the unit of scale is a concurrent execution” and that these are consumed by your functions.
Lambda automatically scales to meet the demands of invocations sent at your function. This is in contrast to a traditional compute model using physical hosts, virtual machines, or containers that you self-manage. With Lambda, you do not need to manage overall capacity or apply scaling policies.
Each AWS account has an overall AccountLimit value that is fixed at any point in time, but can be easily increased as needed. As of May 2017, the default limit is 1000 concurrent executions per AWS Region. You can also set and manage a reserved concurrency limit, which provides a limit to how much concurrency a function can have. It also reserves concurrency capacity for a given function out of the total available for an account.
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
Shutdown doesn’t apply to Lambda because Lambda is intrinsically event-driven. Invocations are tied directly to incoming events or triggers.
However, speed at startup does matter. Initial function execution latency, or what is called “cold starts”, can occur when there isn’t a “warmed” compute resource ready to execute against your application invocations. In the AWS Lambda Execution Model topic, it explains that:
“It takes time to set up an execution context and do the necessary “bootstrapping”, which adds some latency each time the Lambda function is invoked. You typically see this latency when a Lambda function is invoked for the first time or after it has been updated because AWS Lambda tries to reuse the execution context for subsequent invocations of the Lambda function.”
The Best Practices topic covers a number of issues around how to think about performance of your functions. This includes where to place certain logic, how to re-use execution environments, and how by configuring your function for more memory you also get a proportional increase in CPU available to your function. With AWS X-Ray, you can gather some insight as to what your function is doing during an execution and make adjustments accordingly.
X. Dev/prod parity
Keep development, staging, and production as similar as possible
Along with continuous integration and delivery, the practice of having independent application environments is a solid best practice no matter the development approach. Being able to safely test applications in a non-production environment is key to development success. Products within the AWS Serverless Platform do not charge for idle time, which greatly reduces the cost of running multiple environments. You can also use the AWS Serverless Application Model (AWS SAM), to manage the configuration of your separate environments.
SAM allows you to model your serverless applications in greatly simplified AWS CloudFormation syntax. With SAM, you can use CloudFormation’s capabilities—such as Parameters and Mappings—to build dynamic templates. Along with Lambda’s environment variables and API Gateway’s stage variables, those templates give you the ability to deploy multiple environments from a single template, such as testing, staging, and production. Whenever the non-production environments are not in use, your costs for Lambda and API Gateway would be zero. For more information, see the AWS Lambda Applications with AWS Serverless Application Model 2017 AWS online tech talk.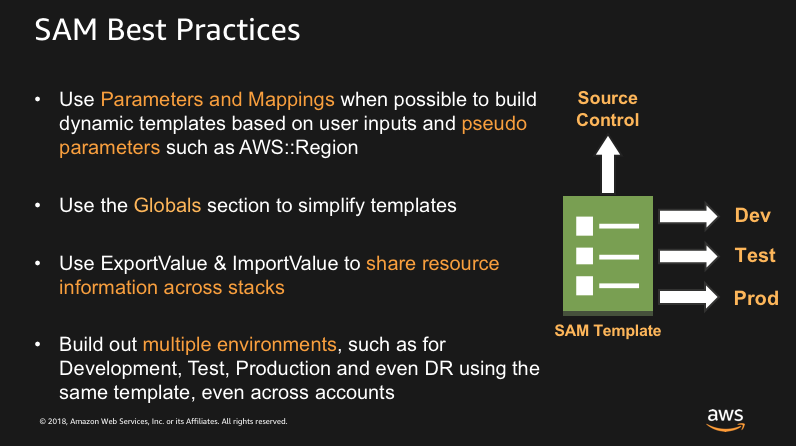
XI. Logs
In a typical non-serverless application environment, you might be concerned with log files, logging daemons, and centralization of the data represented in them. Thankfully, this is not a concern for serverless applications, as most of the services in the platform handle this for you.
With Lambda, you can just output logs to the console via the native capabilities of the language in which your function is written. For more information about Go, see Logging (Go). Similar documentation pages exist for other languages. Those messages output by your code are captured and centralized in Amazon CloudWatch Logs. For more information, see Accessing Amazon CloudWatch Logs for AWS Lambda.
API Gateway provides two different methods for getting log information:
- Execution logs
Includes errors or execution traces (such as request or response parameter values or payloads), data used by custom authorizers, whether API keys are required, whether usage plans are enabled, and so on. - Access logs
Provide the ability to log who has accessed your API and how the caller accessed the API. You can even customize the format of these logs as desired.
Both are also made available to you in CloudWatch Logs. For more information, see Setting Up API Logging in API Gateway.
Capturing logs and being able to search and view them is one thing, but CloudWatch Logs also gives you the ability to treat a log message as an event and take action on them via subscription filters in the service. With subscription filters, you could send a log message matching a certain pattern to a Lambda function, and have it take action based on that. Say, for example, that you want to respond to certain error messages or usage patterns that violate certain rules. You could do that with CloudWatch Logs, subscription filters, and Lambda. Another important capability of CloudWatch Logs is the ability to “pivot” log information into a metric in CloudWatch. With this, you could take a data point from a log entry, create a metric, and then an alarm on a metric to show a breached threshold.
XII. Admin Processes
Run admin/management tasks as one-off processes
This is another factor that doesn’t directly apply to Lambda due to its design. Typically, you would have your functions scoped down to single or limited use cases and have individual functions for different components of your application. Even if they share a common invoking resource, such as an API Gateway endpoint and stage, you would still separate the individual API resources and actions to their own Lambda functions.
The Seven-and-a-Half–Factor model and you
As we’ve seen, Twelve-Factor application design can still be applied to serverless applications, taking into account some small differences! The following diagram highlights the factors and how applicable or not they are to serverless applications:

NOTE: Disposability only half applies, as discussed in this post.
Conclusion
If you’ve been building applications for cloud infrastructure over the past few years, the Twelve-Factor methodology should seem familiar and straight-forward. If you are new to this space, however, you should know that the general best practices and default working patterns for serverless applications overlap heavily with what I’ve discussed here.
It shouldn’t require much work to adhere rather closely to the Twelve-Factor model. When you’re building serverless applications, following the applicable points listed here helps you simplify development and any operational work involved (though already minimized by services such as Lambda and API Gateway). The Twelve-Factor methodology also isn’t all-or-nothing. You can apply only the practices that work best for you and your applications, and still benefit.