AWS News Blog
Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning
What do you see when you look at this picture?

You might simply see an animal. Maybe you see a pet, a dog, or a Golden Retriever. The association between the image and these labels is not hard-wired in to your brain. Instead, you learned the labels after seeing hundreds or thousands of examples. Operating on a number of different levels, you learned to distinguish an animal from a plant, a dog from a cat, and a Golden Retriever from other dog breeds.
Deep Learning for Image Detection
Giving computers the same level of comprehension has proven to be a very difficult task. Over the course of decades, computer scientists have taken many different approaches to the problem. Today, a broad consensus has emerged that the best way to tackle this problem is via deep learning. Deep learning uses a combination of feature abstraction and neural networks to produce results that can be (as Arthur C. Clarke once said) indistinguishable from magic. However, it comes at a considerable cost. First, you need to put a lot of work into the training phase. In essence, you present the learning network with a broad spectrum of labeled examples (“this is a dog”, “this is a pet”, and so forth) so that it can correlate features in the image with the labels. This phase is computationally expensive due to the size and the multi-layered nature of the neural networks. After the training phase is complete, evaluating new images against the trained network is far easier. The results are traditionally expressed in confidence levels (0 to 100%) rather than as cold, hard facts. This allows you to decide just how much precision is appropriate for your applications.
Introducing Amazon Rekognition
Today I would like to tell you about Amazon Rekognition. Powered by deep learning and built by our Computer Vision team over the course of many years, this fully-managed service already analyzes billions of images daily. It has been trained on thousands of objects and scenes, and is now available for you to use in your own applications. You can use the Rekognition Demos to put the service through its paces before dive in and start writing code that uses the Rekognition API.
Rekognition was designed from the get-go to run at scale. It comprehends scenes, objects, and faces. Given an image, it will return a list of labels. Given an image with one or more faces, it will return bounding boxes for each face, along with attributes. Let’s see what it has to say about the picture of my dog (her name is Luna, by the way):
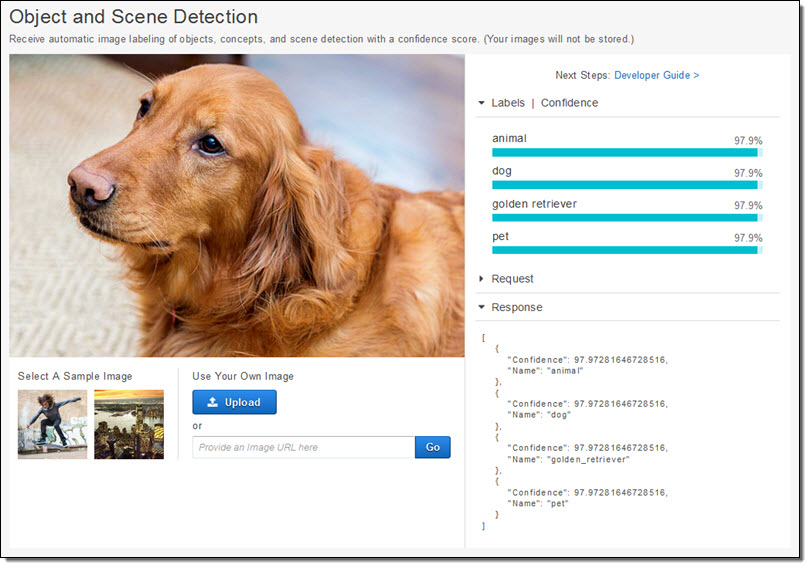
As you can see, Rekognition labeled Luna as an animal, a dog, a pet, and as a golden retriever with a high degree of confidence. It is important to note that these labels are independent, in the sense that the deep learning model does not explicitly understand the relationship between, for example, dogs and animals. It just so happens that both of these labels were simultaneously present on the dog-centric training material presented to Rekognition.
Let’s see how it does with a picture of my wife and I:
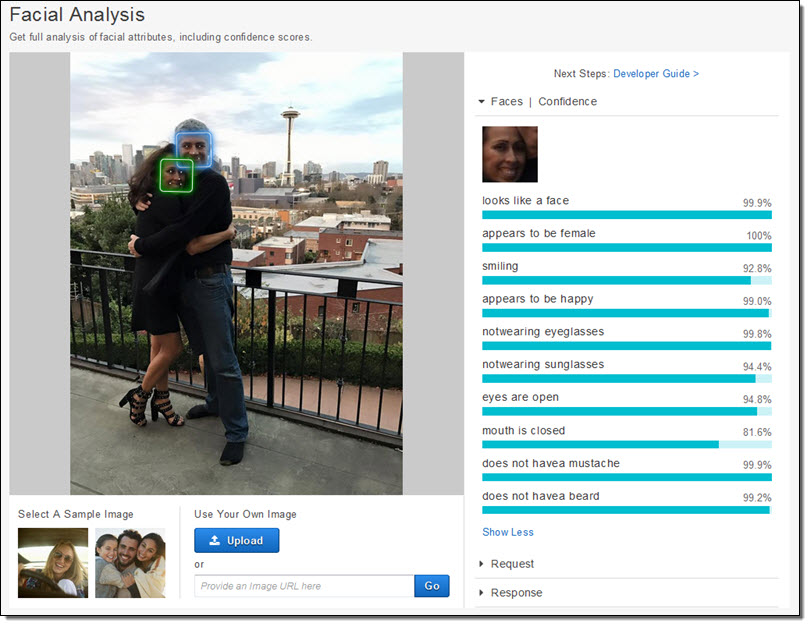
Amazon Rekognition found our faces, set up bounding boxes, and let me know that my wife was happy (the picture was taken on her birthday, so I certainly hope she was).
You can also use Rekognition to compare faces and to see if a given image contains any one of a number of faces that you have asked it to recognize.
All of this power is accessible from a set of API functions (the console is great for quick demos). For example, you can call DetectLabels to programmatically reproduce my first example, or DetectFaces to reproduce my second one. You can make multiple calls to IndexFaces to prepare Rekognition to recognize some faces. Each time you do this, Rekognition extracts some features (known as face vectors) from the image, stores the vectors, and discards the image. You can create one or more Rekognition collections and store related groups of face vectors in each one.
Rekognition can directly process images stored in Amazon Simple Storage Service (Amazon S3). In fact, you can use AWS Lambda functions to process newly uploaded photos at any desired scale. You can use AWS Identity and Access Management (IAM) to control access to the Rekognition APIs.
Applications for Rekognition
So, what can you use this for? I’ve got plenty of ideas to get you started!
If you have a large collection of photos, you can tag and index them using Amazon Rekognition. Because Rekognition is a service, you can process millions of photos per day without having to worry about setting up, running, or scaling any infrastructure. You can implement visual search, tag-based browsing, and all sorts of interactive discovery models.
You can use Rekognition in several different authentication and security contexts. You can compare a face on a webcam to a badge photo before allowing an employee to enter a secure zone. You can perform visual surveillance, inspecting photos for objects or people of interest or concern.
You can build “smart” marketing billboards that collect demographic data about viewers.
Now Available
Rekognition is now available in the US East (N. Virginia), US West (Oregon), and Europe (Ireland) Regions and you can start using it today. As part of the AWS Free Tier tier, you can analyze up to 5,000 images per month and store up to 1,000 face vectors each month for an entire year. After that (and at higher volume), you will pay tiered pricing based on the number of images that you analyze and the number of face vectors that you store.
Ready to learn even more? We have a webinar on December 13th. Register here.
— Jeff;