AWS Compute Blog
Uploading to Amazon S3 directly from a web or mobile application
In web and mobile applications, it’s common to provide users with the ability to upload data. Your application may allow users to upload PDFs and documents, or media such as photos or videos. Every modern web server technology has mechanisms to allow this functionality. Typically, in the server-based environment, the process follows this flow:
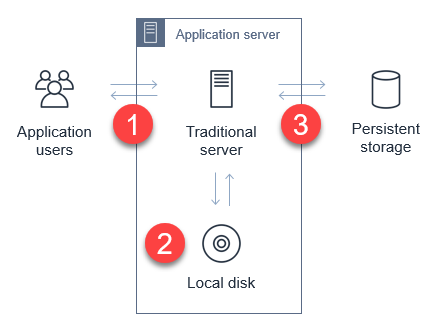
- The user uploads the file to the application server.
- The application server saves the upload to a temporary space for processing.
- The application transfers the file to a database, file server, or object store for persistent storage.
While the process is simple, it can have significant side-effects on the performance of the web-server in busier applications. Media uploads are typically large, so transferring these can represent a large share of network I/O and server CPU time. You must also manage the state of the transfer to ensure that the entire object is successfully uploaded, and manage retries and errors.
This is challenging for applications with spiky traffic patterns. For example, in a web application that specializes in sending holiday greetings, it may experience most traffic only around holidays. If thousands of users attempt to upload media around the same time, this requires you to scale out the application server and ensure that there is sufficient network bandwidth available.
By directly uploading these files to Amazon S3, you can avoid proxying these requests through your application server. This can significantly reduce network traffic and server CPU usage, and enable your application server to handle other requests during busy periods. S3 also is highly available and durable, making it an ideal persistent store for user uploads.
In this blog post, I walk through how to implement serverless uploads and show the benefits of this approach. This pattern is used in the Happy Path web application. You can download the code from this blog post in this GitHub repo.
Overview of serverless uploading to S3
When you upload directly to an S3 bucket, you must first request a signed URL from the Amazon S3 service. You can then upload directly using the signed URL. This is two-step process for your application front end:

- Call an Amazon API Gateway endpoint, which invokes the getSignedURL Lambda function. This gets a signed URL from the S3 bucket.
- Directly upload the file from the application to the S3 bucket.
To deploy the S3 uploader example in your AWS account:
- Navigate to the S3 uploader repo and install the prerequisites listed in the README.md.
- In a terminal window, run:
git clone https://github.com/aws-samples/amazon-s3-presigned-urls-aws-sam
cd amazon-s3-presigned-urls-aws-sam
sam deploy --guided
- At the prompts, enter s3uploader for Stack Name and select your preferred Region. Once the deployment is complete, note the APIendpoint output.The API endpoint value is the base URL. The upload URL is the API endpoint with
/uploadsappended. For example:https://ab123345677.execute-api.us-west-2.amazonaws.com/uploads.

Testing the application
I show two ways to test this application. The first is with Postman, which allows you to directly call the API and upload a binary file with the signed URL. The second is with a basic frontend application that demonstrates how to integrate the API.
To test using Postman:
- First, copy the API endpoint from the output of the deployment.
- In the Postman interface, paste the API endpoint into the box labeled Enter request URL.
- Choose Send.

- After the request is complete, the Body section shows a JSON response. The uploadURL attribute contains the signed URL. Copy this attribute to the clipboard.
- Select the + icon next to the tabs to create a new request.
- Using the dropdown, change the method from GET to PUT. Paste the URL into the Enter request URL box.
- Choose the Body tab, then the binary radio button.

- Choose Select file and choose a JPG file to upload.
Choose Send. You see a 200 OK response after the file is uploaded.
- Navigate to the S3 console, and open the S3 bucket created by the deployment. In the bucket, you see the JPG file uploaded via Postman.

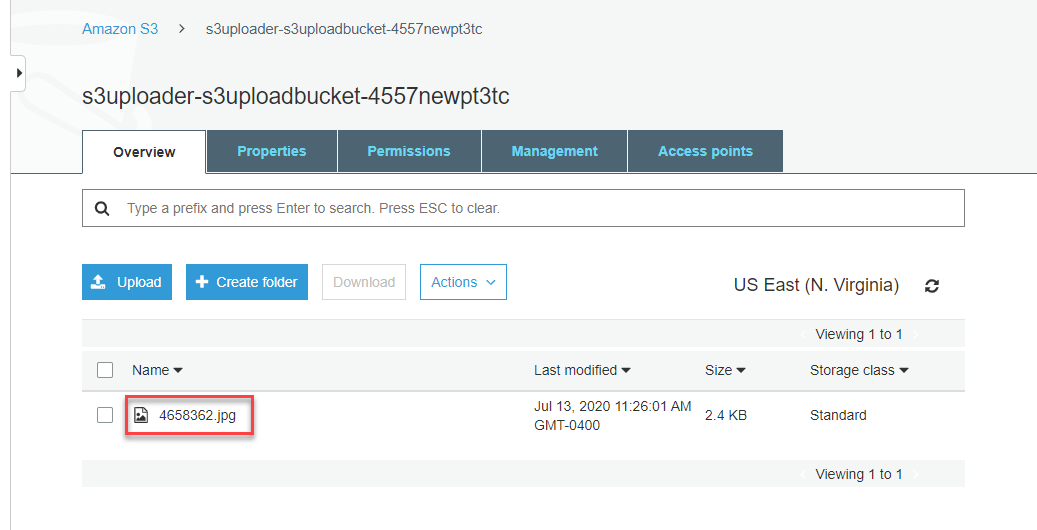
To test with the sample frontend application:
- Copy index.html from the example’s repo to an S3 bucket.
- Update the object’s permissions to make it publicly readable.
- In a browser, navigate to the public URL of index.html file.

- Select Choose file and then select a JPG file to upload in the file picker. Choose Upload image. When the upload completes, a confirmation message is displayed.
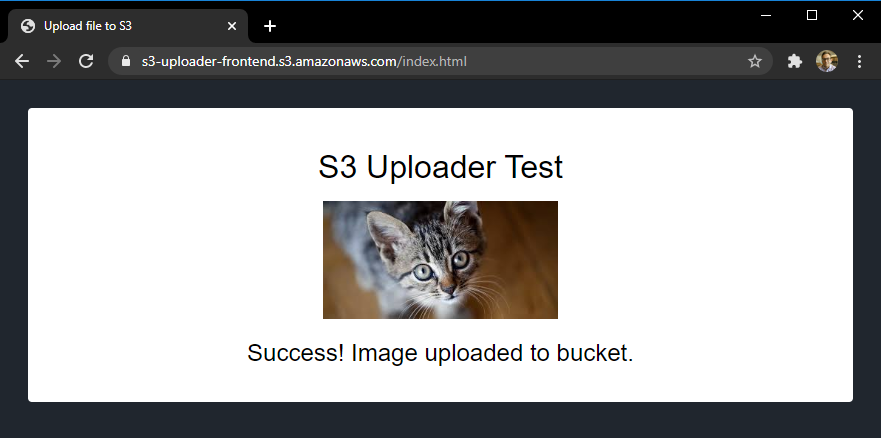
- Navigate to the S3 console, and open the S3 bucket created by the deployment. In the bucket, you see the second JPG file you uploaded from the browser.


Understanding the S3 uploading process
When uploading objects to S3 from a web application, you must configure S3 for Cross-Origin Resource Sharing (CORS). CORS rules are defined as an XML document on the bucket. Using AWS SAM, you can configure CORS as part of the resource definition in the AWS SAM template:
S3UploadBucket:
Type: AWS::S3::Bucket
Properties:
CorsConfiguration:
CorsRules:
- AllowedHeaders:
- "*"
AllowedMethods:
- GET
- PUT
- HEAD
AllowedOrigins:
- "*"
The preceding policy allows all headers and origins – it’s recommended that you use a more restrictive policy for production workloads.
In the first step of the process, the API endpoint invokes the Lambda function to make the signed URL request. The Lambda function contains the following code:
const AWS = require('aws-sdk')
AWS.config.update({ region: process.env.AWS_REGION })
const s3 = new AWS.S3()
const URL_EXPIRATION_SECONDS = 300
// Main Lambda entry point
exports.handler = async (event) => {
return await getUploadURL(event)
}
const getUploadURL = async function(event) {
const randomID = parseInt(Math.random() * 10000000)
const Key = `${randomID}.jpg`
// Get signed URL from S3
const s3Params = {
Bucket: process.env.UploadBucket,
Key,
Expires: URL_EXPIRATION_SECONDS,
ContentType: 'image/jpeg'
}
const uploadURL = await s3.getSignedUrlPromise('putObject', s3Params)
return JSON.stringify({
uploadURL: uploadURL,
Key
})
}
This function determines the name, or key, of the uploaded object, using a random number. The s3Params object defines the accepted content type and also specifies the expiration of the key. In this case, the key is valid for 300 seconds. The signed URL is returned as part of a JSON object including the key for the calling application.
The signed URL contains a security token with permissions to upload this single object to this bucket. To successfully generate this token, the code calling getSignedUrlPromise must have s3:putObject permissions for the bucket. This Lambda function is granted the S3WritePolicy policy to the bucket by the AWS SAM template.
The uploaded object must match the same file name and content type as defined in the parameters. An object matching the parameters may be uploaded multiple times, providing that the upload process starts before the token expires. The default expiration is 15 minutes but you may want to specify shorter expirations depending upon your use case.
Once the frontend application receives the API endpoint response, it has the signed URL. The frontend application then uses the PUT method to upload binary data directly to the signed URL:
let blobData = new Blob([new Uint8Array(array)], {type: 'image/jpeg'})
const result = await fetch(signedURL, {
method: 'PUT',
body: blobData
})
At this point, the caller application is interacting directly with the S3 service and not with your API endpoint or Lambda function. S3 returns a 200 HTML status code once the upload is complete.
For applications expecting a large number of user uploads, this provides a simple way to offload a large amount of network traffic to S3, away from your backend infrastructure.
Adding authentication to the upload process
The current API endpoint is open, available to any service on the internet. This means that anyone can upload a JPG file once they receive the signed URL. In most production systems, developers want to use authentication to control who has access to the API, and who can upload files to your S3 buckets.
You can restrict access to this API by using an authorizer. This sample uses HTTP APIs, which support JWT authorizers. This allows you to control access to the API via an identity provider, which could be a service such as Amazon Cognito or Auth0.
The Happy Path application only allows signed-in users to upload files, using Auth0 as the identity provider. The sample repo contains a second AWS SAM template, templateWithAuth.yaml, which shows how you can add an authorizer to the API:
MyApi:
Type: AWS::Serverless::HttpApi
Properties:
Auth:
Authorizers:
MyAuthorizer:
JwtConfiguration:
issuer: !Ref Auth0issuer
audience:
- https://auth0-jwt-authorizer
IdentitySource: "$request.header.Authorization"
DefaultAuthorizer: MyAuthorizer
Both the issuer and audience attributes are provided by the Auth0 configuration. By specifying this authorizer as the default authorizer, it is used automatically for all routes using this API. Read part 1 of the Ask Around Me series to learn more about configuring Auth0 and authorizers with HTTP APIs.
After authentication is added, the calling web application provides a JWT token in the headers of the request:
const response = await axios.get(API_ENDPOINT_URL, {
headers: {
Authorization: `Bearer ${token}`
}
})
API Gateway evaluates this token before invoking the getUploadURL Lambda function. This ensures that only authenticated users can upload objects to the S3 bucket.
Modifying ACLs and creating publicly readable objects
In the current implementation, the uploaded object is not publicly accessible. To make an uploaded object publicly readable, you must set its access control list (ACL). There are preconfigured ACLs available in S3, including a public-read option, which makes an object readable by anyone on the internet. Set the appropriate ACL in the params object before calling s3.getSignedUrl:
const s3Params = {
Bucket: process.env.UploadBucket,
Key,
Expires: URL_EXPIRATION_SECONDS,
ContentType: 'image/jpeg',
ACL: 'public-read'
}
Since the Lambda function must have the appropriate bucket permissions to sign the request, you must also ensure that the function has PutObjectAcl permission. In AWS SAM, you can add the permission to the Lambda function with this policy:
- Statement:
- Effect: Allow
Resource: !Sub 'arn:aws:s3:::${S3UploadBucket}/'
Action:
- s3:putObjectAcl
Conclusion
Many web and mobile applications allow users to upload data, including large media files like images and videos. In a traditional server-based application, this can create heavy load on the application server, and also use a considerable amount of network bandwidth.
By enabling users to upload files to Amazon S3, this serverless pattern moves the network load away from your service. This can make your application much more scalable, and capable of handling spiky traffic.
This blog post walks through a sample application repo and explains the process for retrieving a signed URL from S3. It explains how to the test the URLs in both Postman and in a web application. Finally, I explain how to add authentication and make uploaded objects publicly accessible.
To learn more, see this video walkthrough that shows how to upload directly to S3 from a frontend web application. For more serverless learning resources, visit https://serverlessland.com.