AWS Big Data Blog
Introducing AWS Glue serverless Spark UI for better monitoring and troubleshooting
In AWS, hundreds of thousands of customers use AWS Glue, a serverless data integration service, to discover, combine, and prepare data for analytics and machine learning. When you have complex datasets and demanding Apache Spark workloads, you may experience performance bottlenecks or errors during Spark job runs. Troubleshooting these issues can be difficult and delay getting jobs working in production. Customers often use Apache Spark Web UI, a popular debugging tool that is part of open source Apache Spark, to help fix problems and optimize job performance. AWS Glue supports Spark UI in two different ways, but you need to set it up yourself. This requires time and effort spent managing networking and EC2 instances, or through trial-and error with Docker containers.
Today, we are pleased to announce serverless Spark UI built into the AWS Glue console. You can now use Spark UI easily as it’s a built-in component of the AWS Glue console, enabling you to access it with a single click when examining the details of any given job run. There’s no infrastructure setup or teardown required. AWS Glue serverless Spark UI is a fully-managed serverless offering and generally starts up in a matter of seconds. Serverless Spark UI makes it significantly faster and easier to get jobs working in production because you have ready access to low level details for your job runs.
This post describes how the AWS Glue serverless Spark UI helps you to monitor and troubleshoot your AWS Glue job runs.
Getting started with serverless Spark UI
You can access the serverless Spark UI for a given AWS Glue job run by navigating from your Job’s page in AWS Glue console.
- On the AWS Glue console, choose ETL jobs.
- Choose your job.
- Choose the Runs tab.
- Select the job run you want to investigate, then choose Spark UI.
The Spark UI will display in the lower pane, as shown in the following screen capture:
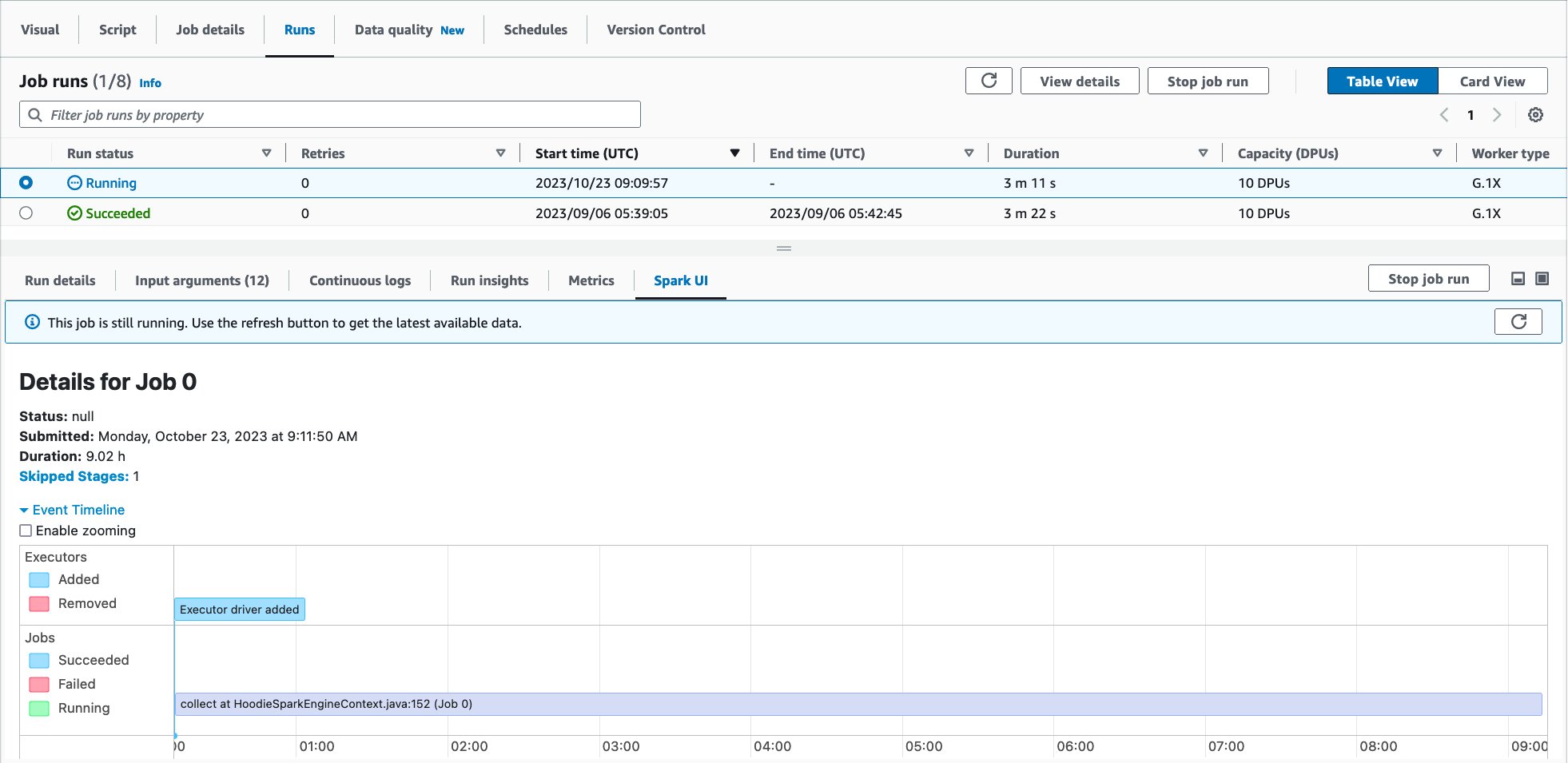
Alternatively, you can get to the serverless Spark UI for a specific job run by navigating from Job run monitoring in AWS Glue.
- On the AWS Glue console, choose job run monitoring under ETL jobs.
- Select your job run, and choose View run details.
Scroll down to the bottom to view the Spark UI for the job run.
Prerequisites
Complete the following prerequisite steps:
- Enable Spark UI event logs for your job runs. It is enabled by default on Glue console and once enabled, Spark event log files will be created during the job run, and stored in your S3 bucket. The serverless Spark UI parses a Spark event log file generated in your S3 bucket to visualize detailed information for both running and completed job runs. A progress bar shows the percentage to completion, with a typical parsing time of less than a minute. Once logs are parsed, you can
- When logs are parsed, you can use the built-in Spark UI to debug, troubleshoot, and optimize your jobs.
For more information about Apache Spark UI, refer to Web UI in Apache Spark.
Monitor and Troubleshoot with Serverless Spark UI
A typical workload for AWS Glue for Apache Spark jobs is loading data from relational databases to S3-based data lakes. This section demonstrates how to monitor and troubleshoot an example job run for the above workload with serverless Spark UI. The sample job reads data from MySQL database and writes to S3 in Parquet format. The source table has approximately 70 million records.
The following screen capture shows a sample visual job authored in AWS Glue Studio visual editor. In this example, the source MySQL table has already been registered in the AWS Glue Data Catalog in advance. It can be registered through AWS Glue crawler or AWS Glue catalog API. For more information, refer to Data Catalog and crawlers in AWS Glue.
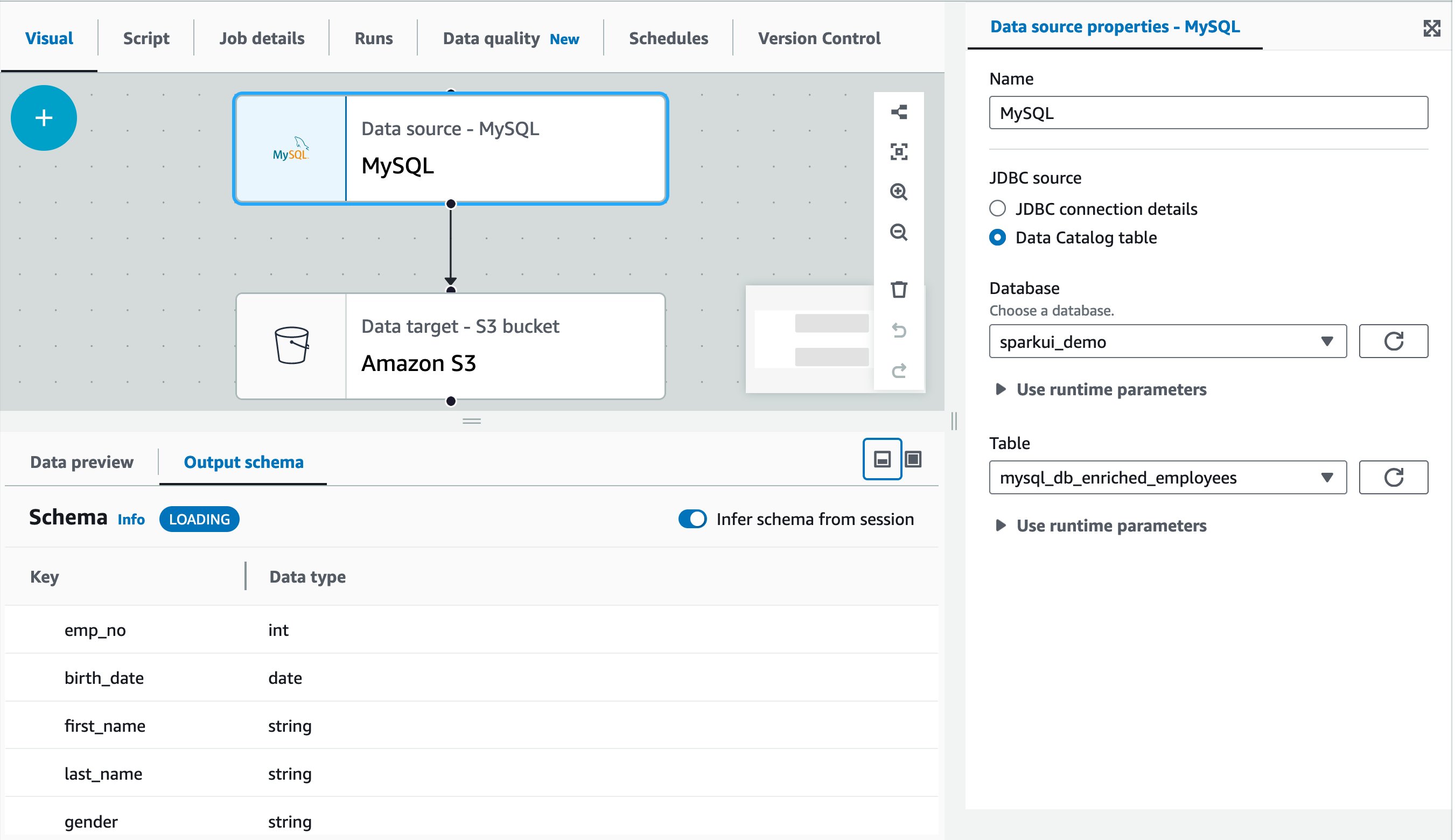
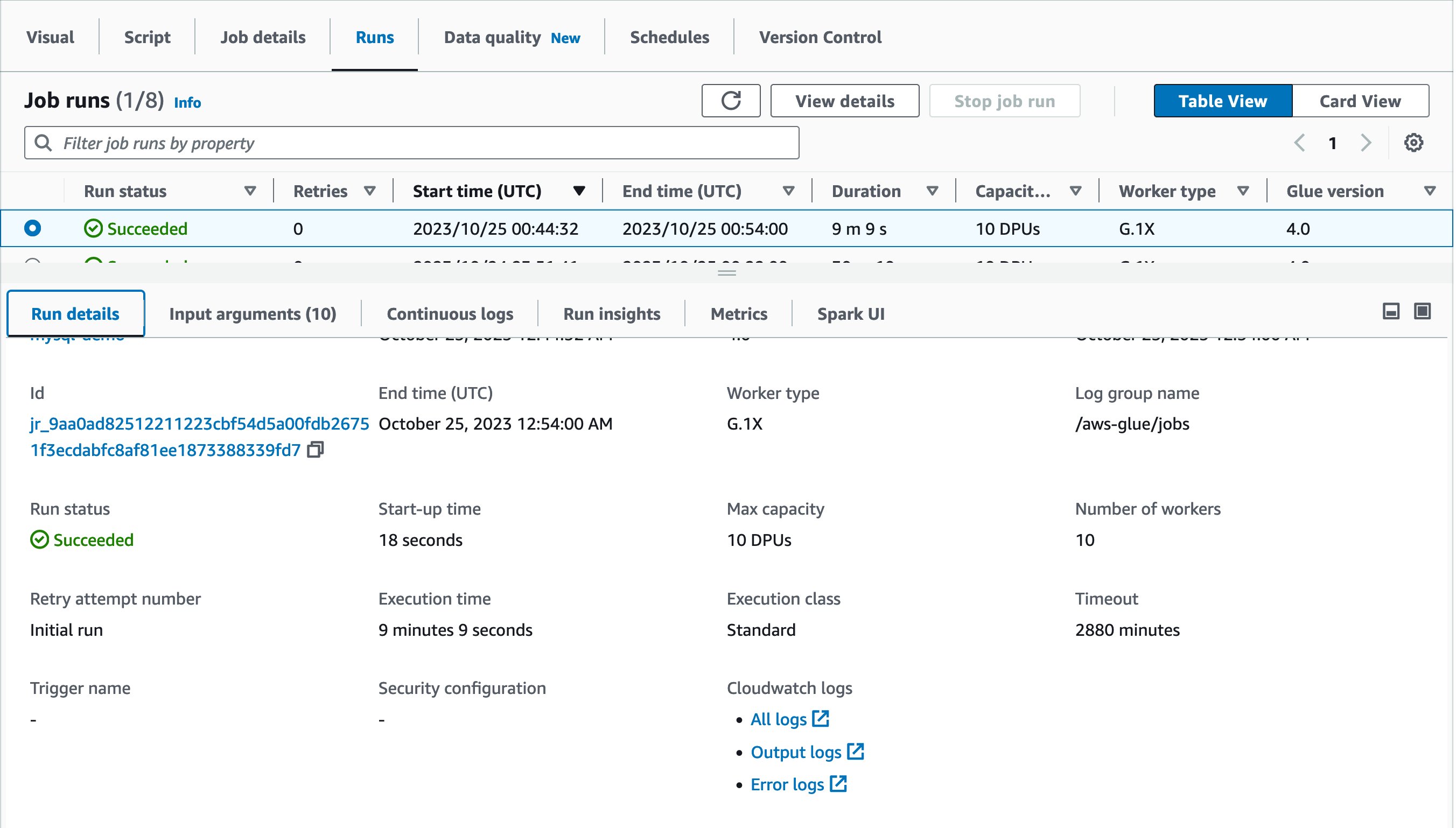
Now it’s time to run the job! The first job run finished in 30 minutes and 10 seconds as shown:
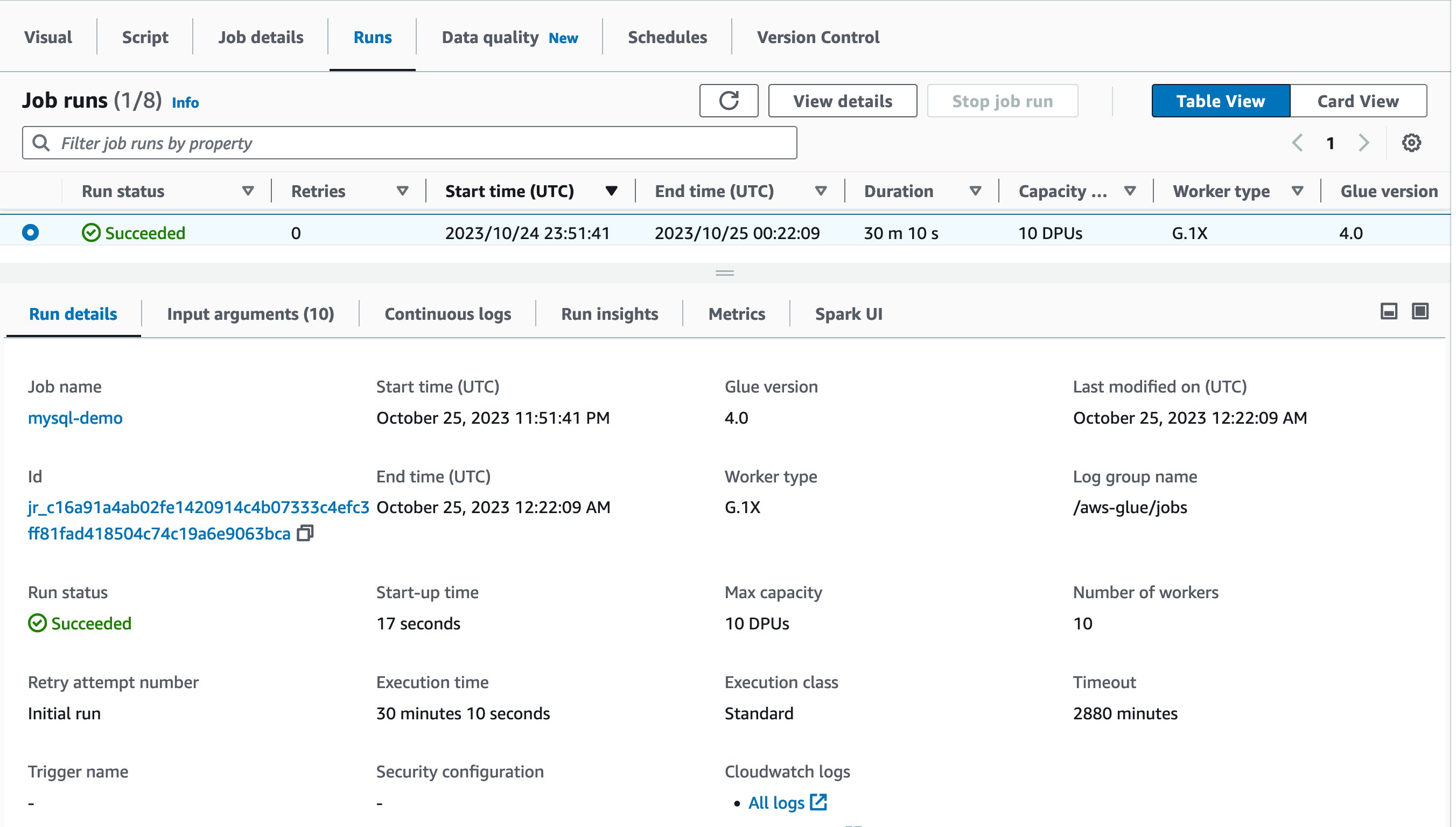
Let’s use Spark UI to optimize the performance of this job run. Open Spark UI tab in the Job runs page. When you drill down to Stages and view the Duration column, you will notice that Stage Id=0 spent 27.41 minutes to run the job, and the stage had only one Spark task in the Tasks:Succeeded/Total column. That means there was no parallelism to load data from the source MySQL database.

To optimize the data load, introduce parameters called hashfield and hashpartitions to the source table definition. For more information, refer to Reading from JDBC tables in parallel. Continuing to the Glue Catalog table, add two properties: hashfield=emp_no, and hashpartitions=18 in Table properties.
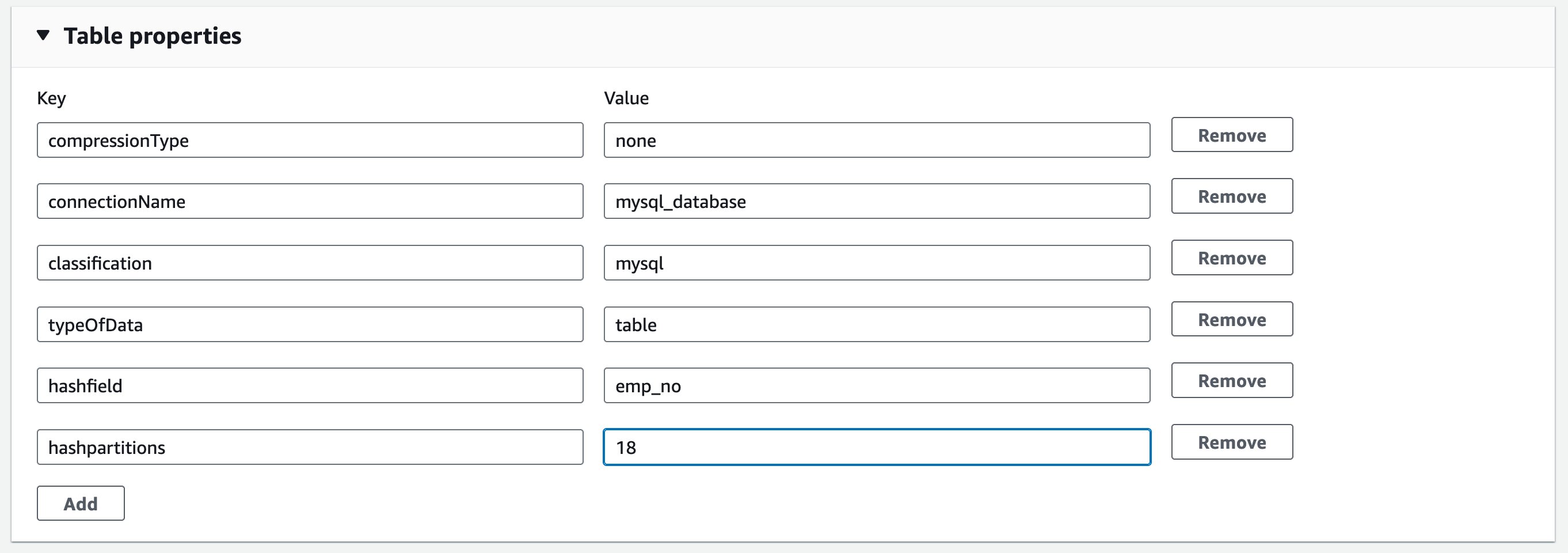
This means the new job runs reading parallelize data load from the source MySQL table.
Let’s try running the same job again! This time, the job run finished in 9 minutes and 9 seconds. It saved 21 minutes from the previous job run.
As a best practice, view the Spark UI and compare them before and after the optimization. Drilling down to Completed stages, you will notice that there was one stage and 18 tasks instead of one task.
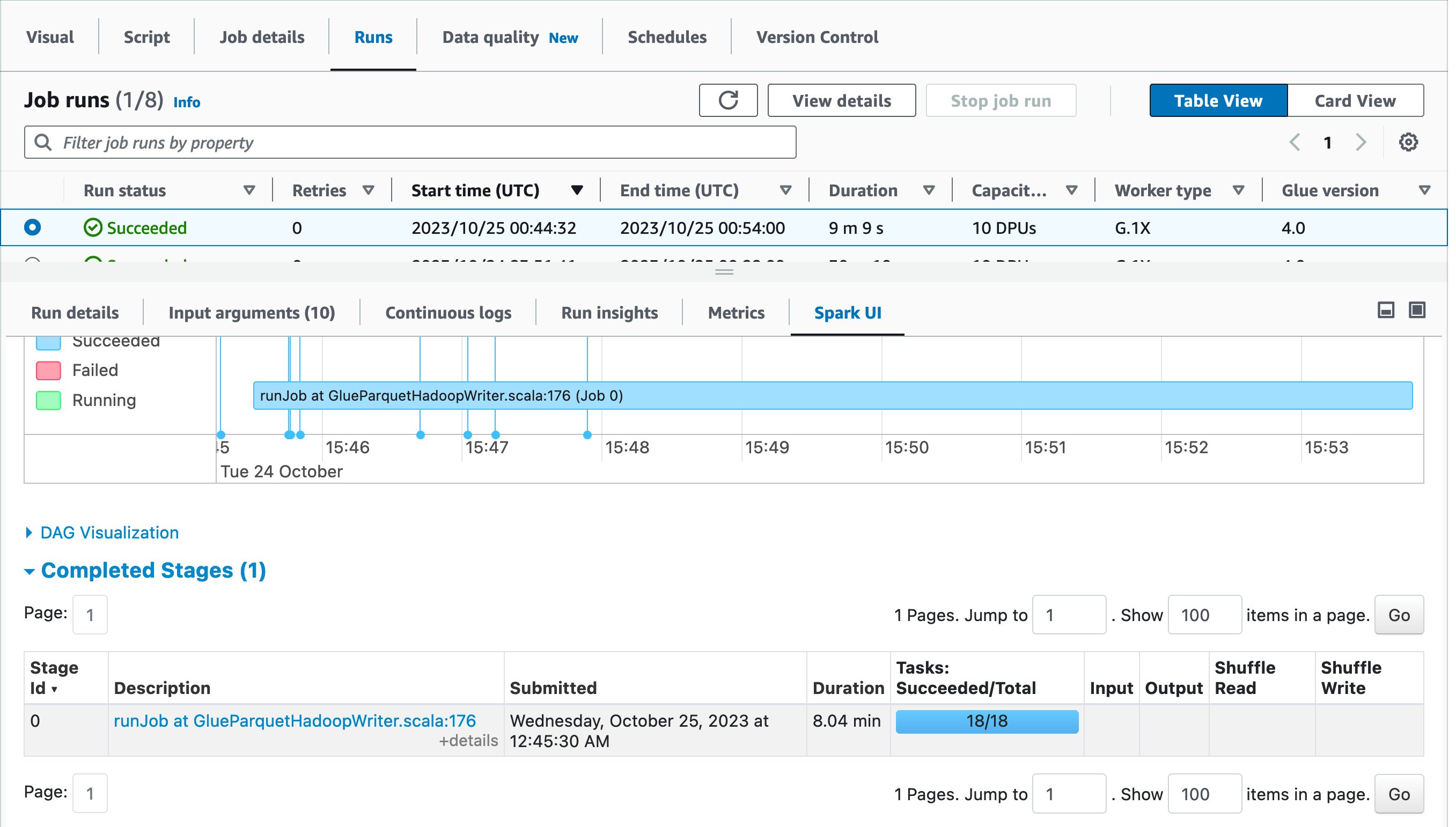
In the first job run, AWS Glue automatically shuffled data across multiple executors before writing to destination because there were too few tasks. On the other hand, in the second job run, there was only one stage because there was no need to do extra shuffling, and there were 18 tasks for loading data in parallel from source MySQL database.
Considerations
Keep in mind the following considerations:
- Serverless Spark UI is supported in AWS Glue 3.0 and later
- Serverless Spark UI will be available for jobs that ran after November 20, 2023, due to a change in how AWS Glue emits and stores Spark logs
- Serverless Spark UI can visualize Spark event logs which is up to 512 MB in size
- There is no limit in retention because serverless Spark UI scans the Spark event log files on your S3 bucket
- Serverless Spark UI is not available for Spark event logs stored in S3 bucket that can only be accessed by your VPC
Conclusion
This post described how the AWS Glue serverless Spark UI helps you monitor and troubleshoot your AWS Glue jobs. By providing instant access to the Spark UI directly within the AWS Management Console, you can now inspect the low-level details of job runs to identify and resolve issues. With the serverless Spark UI, there is no infrastructure to manage—the UI spins up automatically for each job run and tears down when no longer needed. This streamlined experience saves you time and effort compared to manually launching Spark UIs yourself.
Give the serverless Spark UI a try today. We think you’ll find it invaluable for optimizing performance and quickly troubleshooting errors. We look forward to hearing your feedback as we continue improving the AWS Glue console experience.
About the authors
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
 Alexandra Tello is a Senior Front End Engineer with the AWS Glue team in New York City. She is a passionate advocate for usability and accessibility. In her free time, she’s an espresso enthusiast and enjoys building mechanical keyboards.
Alexandra Tello is a Senior Front End Engineer with the AWS Glue team in New York City. She is a passionate advocate for usability and accessibility. In her free time, she’s an espresso enthusiast and enjoys building mechanical keyboards.
 Matt Sampson is a Software Development Manager on the AWS Glue team. He loves working with his other Glue team members to make services that our customers benefit from. Outside of work, he can be found fishing and maybe singing karaoke.
Matt Sampson is a Software Development Manager on the AWS Glue team. He loves working with his other Glue team members to make services that our customers benefit from. Outside of work, he can be found fishing and maybe singing karaoke.
 Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.
Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.