Amazon Web Services ブログ
Category: General

週刊生成AI with AWS – 2026/6/8 週
週刊生成 AI with AWS, エージェント型サービスが続々登場した 2026 年 6 月 8 日号 – タキヒヨー株式会社様、株式会社エイチビーソフトスタジオ様の国内事例ブログを紹介。また、Claude Fable 5 の発表や AWS FinOps Agent、AWS DevOps Agent、Amazon Bedrock AgentCore、Kiro の最新アップデートなどのブログ記事も。サービスアップデートでは Gemma 4 や OpenAI GPT-5.5 の Amazon Bedrock 提供、AI を活用したコスト調査機能をはじめとする 9 件のアップデートを紹介。

Amazon Connect Customer とは?エージェンティック AI ソリューションの最新アップデート – 2026 年 5月
こんにちは、Amazon Connect ソリューションアーキテクトの梅田です。2026年 4 月号 はお読み […]

AWS Summit 2026 Supply Chainブースのご紹介
数日かかるサプライチェーンの意思決定を、AI エージェントへの一言で数分に短縮できるとしたら? このブログでは、AWS Summit Japan 2026 の Supply Chain ブースで展示するデモの仕組みと技術的な裏側を詳しく紹介しています。ぜひご一読ください!

第 7 回 AWS ジャパン 生成 AI Frontier Meetup ~学びと繋がりの場~【開催報告】
アマゾン ウェブ サービス ジャパン(以下、AWS ジャパン)が実施する「生成 AI 実用化推進プログラム」は […]

経済産業省 GENIAC 基盤モデル開発支援事業 (第4期) における採択事業者への支援を開始
2026年6月4日、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する […]

フィジカルAIで創薬が変わる Self-Driving Labのご紹介 | AWS Summit 2026 Healthcare & Life Sciences ブース
国内最大規模の学習型 IT カンファレンスである AWS Summit Japan が、2026 年 6 月 […]
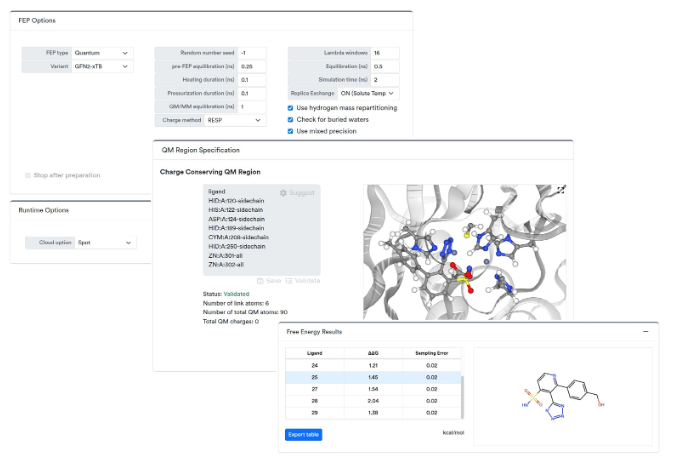
第一三共株式会社 × QSimulate: データ駆動型創薬 (D4) における QM-FEP 活用 — QSimulate × AWS で切り拓く親和性予測の高度化
このブログは、第一三共株式会社 スマートリサーチ第二研究所と QSimulate による共著です。 はじめに […]

AWS Summit Japan 2026 ブース紹介 生産ラインの未来
急な需要の変化に対して、工場の生産ラインをもっと柔軟に変更したいと言う困りごとはないでしょうか。このブログでは、AWS Summit Japan 2026 の 製造展示の中から生産ラインの未来のテーマをご紹介しています。 AI エージェント、デジタルツイン、ソフトウェアで定義された工場のキーワードで、需要の変化に追随できる新しい工場の姿をご紹介しています。
生成AIで開発ツール操作を自動化 – Kiro × MCP Server × dSPACE ControlDesk
はじめに SIL/HIL(Software/Hardware-in-the-Loop)などのシミュレーションを […]

AWS DevOps Agent によるネットワークインシデント対応の自動化
本記事は、2026 年 4 月 21 日に Networking & Content Delivery […]