AWS Partner Network (APN) Blog
Building Serverless SaaS Microservices with AWS Lambda Layers
By Tod Golding, Principal Partner Solutions Architect – AWS
One of the key goals of every software-as-a-service (SaaS) architect is to design a solution where the complexity of multi-tenancy is largely hidden away from the developers who are building the services of these solutions.
The goal is to introduce frameworks, libraries, and tooling that limits a developer’s need to have any awareness of tenant context, freeing them up to focus on the features and functionality of their system. This is a core principle of creating an environment that achieves the management and agility goals that are essential to the adoption of SaaS.
There are any number of well-understood ways to address this goal that may vary a bit from one technology stack to the next. The general strategy that is applied in this post is to move the common code that accesses and applies tenant context into a set of libraries that can be referenced and leveraged by the components/services that make up your SaaS environment. These libraries are often separately packaged and versioned into a library or module that can be imported and referenced by developers.
As we look at the serverless model, where we deploy and build in much smaller units, we need better strategies for sharing common code across multiple AWS Lambda functions. If our goal is to keep the footprint of our Lambda functions small and efficient, then we want to limit the degree to which these individual functions become bloated with imported libraries and shared code. At the same time, we want to simplify the developer experience by moving tenant awareness into libraries.
This is precisely where AWS Lambda Layers fit. In this post, we’ll look at how Lambda Layers allow us to give the best of both worlds, allowing SaaS architects to centralize tenant-aware libraries without impacting the size or load-time of your SaaS application’s functions.
Separating Out the Shared Concepts
Before we dig into the AWS Lambda Layers, we first need to understand what it means to hide away the details of multi-tenancy in our SaaS microservices.
Let’s start by looking at a common microservice that may be part of a SaaS environment. The example below provides a high-level view of some of the common components that might be part of my microservice implementation.
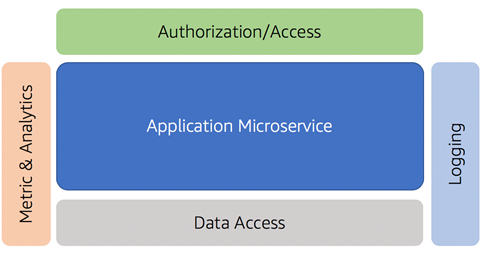
Figure 1 – Microservices and multi-tenant helpers.
Here, you’ll notice we have a microservice at the center of this diagram. Within this service resides all of the business logic and functionality that’s implemented within the scope of the microservice. Surrounding it are examples of common constructs that would often be shared by any microservice that are part of our system.
Logging, for example, has been included here to represent the common library that will be used to capture and publish our log messages. The metrics and analytics library, as its name suggests, is used to record any metric data that’s associated with the service.
At the top of the service, you’ll also see authorization/access. This library is used to acquire tenant context from an incoming request and validate/scope the caller’s access to the service’s functionality.
Finally, you’ll notice that we have a data access library here as well. This is a common construct for many systems that want to create a standardized model for interacting with the underlying storage and/or database used by this service.
Adding Tenant Context to the Mix
So far, there is nothing particularly distinguishing about this model. However, if you take these same services and place them in a multi-tenant environment, you’ll find there is a range of additional considerations that will impact the scope and implementation of these libraries.
In a SaaS environment, each one of these services must incorporate support for tenant context. This context includes the identifying information about the tenant that’s essential to any number of activities that may happen within the scope of the microservice.
Imagine how you might implement logging and metrics in a multi-tenant environment. Instead of just passing through log or metric data, these libraries must also inject tenant context into each request that’s processed. Having this context included with our log and metric data allows us to scope the view of metric and log data to individual tenants. This is essential to enabling business and operations teams to effectively analyze this data.

Figure 2 – Injecting tenant context.
Above, you see a simple example of how tenant context influences the implementation of our multi-tenant microservices. We have a microservice that takes inbound JSON Web Token (JWT) and the microservice needs to log an activity message. While we need tenant context in our logs, we don’t want our microservices to own responsibility for acquiring or resolving that tenant context. Instead, the service should just log a message as they normally would (Step 2 in the diagram).
You’ll notice we introduced a log manager helper that calls the token manager to get the tenantId from the JWT token. Then, it records a log message with tenant context. A very basic helper still adds value because it simplifies resolution of the tenant identity and takes it out of the view of the developer.
Where this gets more interesting is when we look at how this approach can influence the way our microservices interact with multi-tenant data. With this approach, we can move any knowledge of how tenant data may be partitioned away from the view of the microservice developers.
Moving this detail into common libraries allows us to have a more centralized model for managing our multi-policies and strategies. In our data access example, we could toggle from a siloed data model to a pooled data model without impacting the microservice code. These policies can now be implemented in a single place that can be changed, versioned, and deployed independently.
These are just a few examples of how tenant context can be hidden away from developers. While the approach might vary from system to system, the goal remains mostly the same. We want the injection of application of tenant context out of the view of our services.
Using AWS Lambda Layers for Shared Libraries
Now that we’ve established the general need and use case for shared libraries in a SaaS environment, we can start to look at what it would mean to realize this model in a serverless model. Serverless requires developers to be more focused on how the footprint of each Lambda function will impact the performance and scale of the overall system.
Generally, the goal with serverless is to keep our functions as lean as possible. The challenge is that these functions also tend to rely on shared constructs. Most functions need to have dependencies on frameworks and libraries that address core concepts that are shared across many functions.
Given that each function is meant to be deployed independently, this usually means you’ll need to bundle all of the required concepts with each deployment of a function. This dynamic generally inflates the size and footprint of your functions.
Fortunately, the introduction of AWS Lambda Layers gives us a new tool to address this problem. Lambda Layers give you a way to create, manage, and deploy components or libraries that are shared by one or more functions. The diagram below provides a conceptual view of how layers might be used with your Lambda functions.
In Figure 3, you’ll notice we have a getOrders() Lambda function implemented in NodeJS that has dependencies on a collection of third-party modules. The list of modules that may be required can vary substantially. However, it’s not uncommon for these modules to add a fair amount of bloat to your function’s overall footprint.
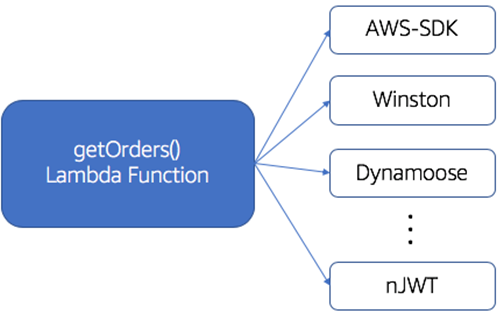
Figure 3 – Third-party module dependencies.
With Lambda Layers, the goal is to move these common libraries out of the scope of our individual functions, providing a way for them to be referenced and included through a global mechanism. If we apply layers to our function in Figure 3, for example, we can move all of these third-party modules into a Lambda Layer(s) and have them referenced by all the functions of our system.
Now, instead of having each of these libraries packaged and deployed with our functions, they can be placed in a separately versioned and deployed construct. You can, in fact, manage version dependencies between your functions and your layers, controlling which version of a given layer is being referencing by one or more functions. This both reduces the footprint of our functions and gives us a way to separate the management and deployment of these libraries from the deployment of our functions.
You’ll also want to consider how the use of Lambda Layers will affect the overall code storage of your serverless environment. While Lambda Layers can generally help with code storage, they also count toward to 250mb of total unzipped size of the function quota. More data on code storage best practice can be found in the AWS documentation.
Create Layers to Abstract Away Tenant Awareness
Let’s circle back to our SaaS microservices and think about how Lambda Layers would influence our approach to hiding away multi-tenant detail. You can imagine how Lambda Layers represent a natural fit for the needs of the serverless SaaS functions.
With Lambda Layers, you can push all (or most of) the multi-tenant awareness out of your Lambda functions and into a layer that supports all the tenant abstraction concepts outlined above.
The diagram in Figure 4 provides a more detailed view of this in action. Here, we have two serverless microservices that both rely on a layer with multi-tenant helpers. This is essentially an extension of the concepts described above realized with a Lambda Layer. The helpers we described above are now built, deployed, and accessed via a shared layer.

Figure 4 – Sample Lambda Layer implementation.
The goal here is to identify any libraries that can move these tenant-specific concepts outside the view of microservice builders. The power comes from both the simplification of microservice code and the centralized build/deployment of these shared constructs.
Adding Another Dimension of Agility
Agility is one of the key motivations for adopting a SaaS delivery model. Lambda Layers give us another tool that enhances the overall agility footprint of a SaaS environment. Since each layer we introduce can be versioned and deployed independently, you can make updates to these shared multi-tenant libraries and have individual functions opt into the new version of your layer.
Imagine, for example, that you have changed the data you want to capture for a metric that is published by multiple Lambda functions. If you now want to add more information or context to that metric event, you could simply update the metrics library that reside in the Lambda Layer and deploy it. If the version of the layer changes, however, your CI/CD process will also need to re-deploy all of the Lambda functions that depend on it.
This ability to have these cross-cutting concerns managed and deployed separately enhances the overall agility profile of the SaaS environment. It also creates an opportunity to have separate teams own these Lambda Layer libraries.
The Impact on Your Code
While most of our focus in this post has been about pushing this multi-tenant functionality out to Lambda Layers, it’s worth thinking about how this effects the actual code your SaaS builders write. Teams that do a good job with abstracting away tenant awareness tend to end up with code that is generally cleaner and simpler to maintain.
For a really basic example, imagine a function that didn’t have the assistance of the helper libraries that we’ve mentioned. In Figure 5, you can see a very simple getOrders() example that doesn’t have the benefit of a token management library that extracts tenant context from JWT tokens.
Our very basic function suddenly gets inflated by the basic helper code that extracts our tenant context. Lines 2-5 of this example essentially assume responsibility for finding the token in the HTTP request, doing the string manipulation to isolate the token, decoding the token, and extracting the claims.
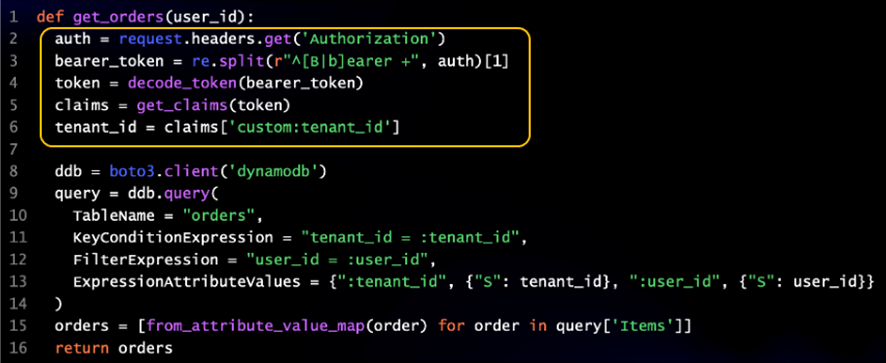
Figure 5 – Sample code without helper libraries.
If we take this same code and add our token manager library to the mix, you can see how this streamlines our code.
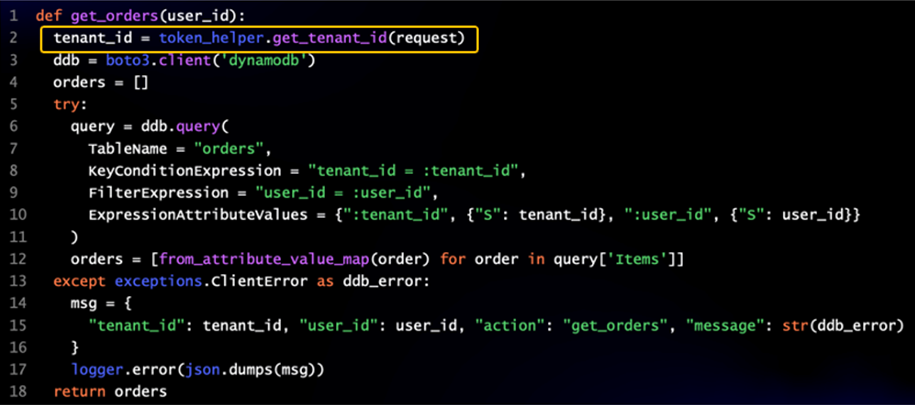
Figure 6 – Same code with a token manager.
Now, you can see the code required to fetch our tenantId has been reduced to a single line. There’s no magic about this—it’s simply good practice to move common concepts to libraries. They key is identifying all of the areas where multi-tenant concepts can be moved to share libraries.
This approach begins to add significant value when you start to look at bigger-picture concepts like tenant isolation and data access. You’ll be moving significant strategies out into common code, and this can be valuable around tenant isolation where you don’t want to rely on developers to code their own isolation strategies. Centralizing isolation in a separate library makes it hard for systems to un-intentionally violate a isolation policy.
Exploring a Working Sample
If you’re interested in seeing these concepts in action, we have created a self-guided workshop that can take you through the moving parts of a multi-tenant environment that employs AWS Lambda Layers to abstract away multi-tenant concepts.
A link to the workshop can be found on Github. If you follow the steps in this experience, you’ll be taken through the journey of introducing shared multi-tenant libraries that are moved into a Lambda Layers model.
Putting it All Together
Building multi-tenant systems can represent a major effort for some teams. The reality is, while teams are anxious to move to SaaS, they also want to focus energy on the features and functions of their product. This post is focused on introducing strategies that allow developers to write their day-to-day code without having to think about how tenancy might influence their implementation.
Focusing on abstracting away these concepts also forces teams to think about the horizontal concepts that are fundamental to their SaaS environment. How is tenant isolation be applied? How will we log and record metrics with tenant context? How will we access multi-tenant data? These are all questions that you’ll need to address. Ideally, you can address with common libraries that centralize the management, deployment, and lifecycle of these multi-tenant mechanisms.
The general goal here is to highlight how this notion of sharing common code and concepts can be realized and applied in a powerful way that enhances the experience of SaaS builders.
About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.