AWS Partner Network (APN) Blog
The Curse of Big Data Labeling and Three Ways to Solve It
 |
 |
By Jennifer Prendki, VP of Machine Learning at Figure Eight
Remember when data was a rare, precious commodity? It might be hard to believe, but those days were not such a long time ago.
When I was finishing my PhD in Particle Physics back in 2009, the field was particularly attractive to people with a strong interest in understanding the mysteries of the universe, but also to analytically-minded people desperate for interesting data to analyze.
How things have changed since then!
With the appearance of ever more powerful hardware capable of recording every mouse click, tweet, and purchase, we simply have too much data now to ever look at.
The nature of data has also changed dramatically. Just a decade back, the majority of our data was structured (residing in relational databases) or textual. Now, with the advent of self-driving vehicles, drones, and the Internet of Things (IoT), images and video data are taking the lion’s share of the data storage zoo. It almost seems like modern society has created a data scientist’s paradise.
Unfortunately, things are never that easy.
There is a huge elephant in the room that even some of the savviest tech companies seem to have overlooked or chosen to ignore—the problem of data labeling.
Why Big Data Labeling Holds Back AI
In some sense, it’s easy to see why this critical issue is so often bypassed. Decades after being invented, neural networks can finally be used in practice to build incredible new artificial intelligence (AI)-powered applications.
This is largely thanks to recent progress made in hardware, which has both enabled the collection of larger quantities of data and provided the compute power necessary to train large models.
Put simply, the preponderance of big data seems to have put an end to a long AI winter. The issue though, is that deep learning models are mostly used in a supervised way. In other words, they require data to be labeled.
The true bottleneck to AI is not access to data, but rather labeling this data. That’s why, in spite of the huge availability of quantity image data, ImageNet (the largest labeled image dataset available to the public, consisting of “only” 14 million images) is the go-to dataset for computer vision specialists across industries, even when more appropriate specific data is available. One of the main reasons the community uses ImageNet is because it’s labeled.
As we create more and more data on more and more devices, this problem is not going away. In fact, we have reached a point where there aren’t enough people on the planet to label all the data we’re creating.
This problem is precisely the problem we are addressing at Figure Eight, an AWS Partner Network (APN) Advanced Technology Partner with the AWS Machine Learning Competency.
At Figure Eight, we pioneered the AI industry by defining the very concept of human-in-the-loop and providing high quality manually-labeled data to machine learning (ML) experts across the board. Now, we’re taking the human-in-the-loop AI category to the next level by using a collaborative approach between humans and machines as part of the process of data augmentation itself. We are actively developing innovative ML-powered data annotation solutions, such as our new Video Object Tracking tool.
But there is an entirely different way to think about the problem of large-scale data labeling: the idea of smart row selection.
How to Solve the Data Labeling Crisis
Nowadays, most ML professionals take a similar approach when they build models—they start by collecting data, having this data labeled, and then using it to train, test, and tune a model for a real-world application. This approach, however, fails to account for a very important fact: not all data is created equal.
Imagine, for example, that you are training a categorization model for clothing, and assume that a large fraction of the images within your dataset are images of sweaters. If you use your entire dataset or random sampling prior to labeling your data, you will most likely have a very high confidence level when categorizing sweaters, but maybe not great results for skirts.
It’s even possible that only a fraction of the sweater images in your dataset would have been enough to reach a similar result; and it would have been a better use of your labeling budget (both time- and money-wise) to focus on another type of image. This is what “smart row picking” is all about.
There are three main ways to leverage this approach when training models.
1. Choosing the rows to be labeled prior to model training
Depending on the distribution of the data in the feature space, it’s possible to determine in advance which rows might be more informative to train a specific model using a pre-processing strategy called a prioritizer.
For example, if you are working with tweets, it might be a good idea to remove spam that would cost time and money to annotate and cause biases in your model. It’s also possible to create a prioritizer specifically designed to pre-select data in the context of a specific task.
2. Choosing your rows while the model is being trained
The concept of gradually adding more data of rows optimally selected dynamically (or actively) while a model is being trained is called active learning. This is a very powerful tool in machine learning because it allows to control the exact amount of data needed for training and use just enough data to reach a specific accuracy. It generally achieves better performance than prioritization because the learner can dynamically adapt its learning strategy instead of relying on preliminary (static) assumptions.
However, active learning is more difficult to set up because it assumes that data will be labeled in several stages, requiring a succession of separate annotation jobs to be launched iteratively, which can be done efficiently only if you can control and prioritize the flow of microtasks sent to contributors.
3. Choosing your rows to be corrected after the model is trained
This approach is a little bit different in nature because it doesn’t directly impact the quality of the model, but it does allow you to save on labeling costs and time nonetheless. The overall idea is to train a model using less training data, knowing that its accuracy will be impacted, and then routing low confidence predictions to human annotators for review and validation.
In this “pure” Human-in-the-Loop approach, the data corrected by humans is not fed back into the model (and if it did, this would typically become an active learning setting). While there is clearly a lost opportunity to leverage audited data to improve the performance of the model, this technique is still very powerful thanks to its simplicity, and also offers some explainability.
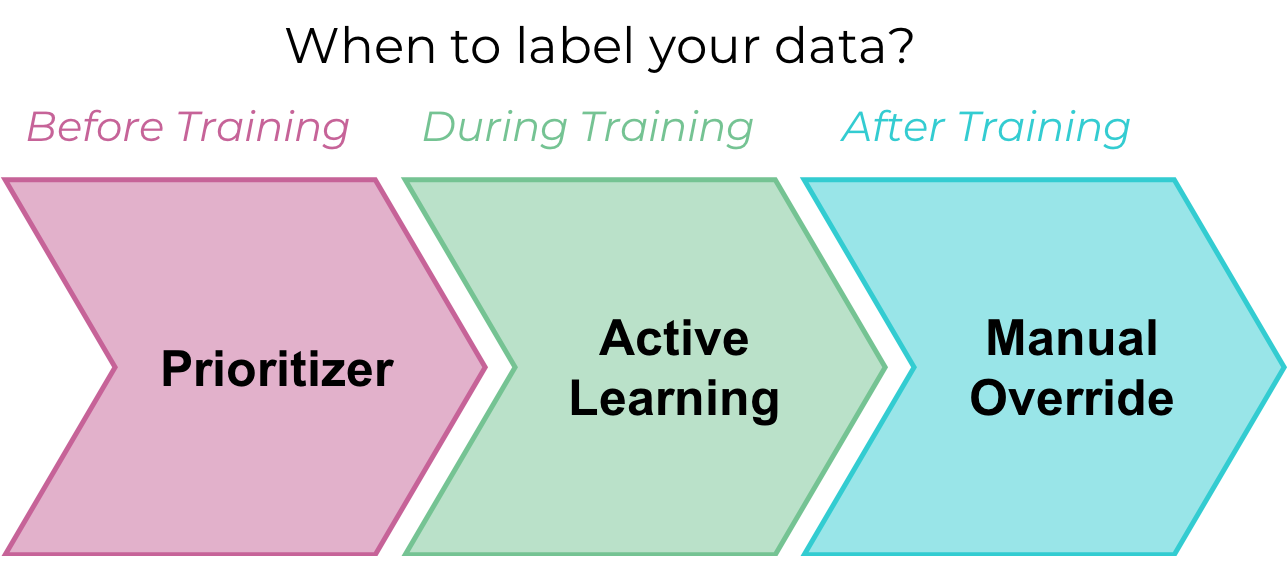
Figure 1 – Three common approaches for reducing annotation costs, before, during, and after the training process.
Conclusion
Nearly every machine learning project requires some labeling or augmentation of raw data to create data that’s ready to power smart models and algorithms. But the fundamental reality for most organizations is that they simply have too much data to label.
In this post, we discussed three main ways to leverage smart row picking when training models. Whether you select rows before you start, employ active learning, or use a Human-in-the-Loop approach for low-confidence rows post-training, these are all great tactics to use to reduce annotation time and cost.
In other words, the next time you use a supervised learning algorithm, start by asking yourself what easy steps you can take to optimize the data you send out to be labeled. This can save you precious time and effort.
The bad news is that minimizing the amount of data required for training is not easy and requires a lot of expertise; the good news is that Figure Eight is actively developing solutions to empower any company, regardless of their level of maturity, to make the wisest choices when labeling their data.
Next Steps
Figure Eight’s human-in-the-loop machine learning platform creates high-quality, structured training data for your ML models. Learn more about our human-in-the-loop machine learning platform.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
|
Figure Eight – APN Partner Spotlight
Figure Eight is an AWS ML Competency Partner. They are the essential human-in-the-loop ML platform using machine learning-assisted annotation solutions to create the high-quality training data needed by models to work in the real world.
Contact Figure Eight | Solution Overview | Customer Success
*Already worked with Figure Eight? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.