AWS News Blog
Amazon Cloud Directory – A Cloud-Native Directory for Hierarchical Data
Our customers have traditionally used directories (typically Active Directory Lightweight Directory Service or LDAP-based) to manage hierarchically organized data. Device registries, course catalogs, network configurations, and user directories are often represented as hierarchies, sometimes with multiple types of relationships between objects in the same collection. For example, a user directory could have one hierarchy based on physical location (country, state, city, building, floor, and office), a second one based on projects and billing codes, and a third based on the management chain. However, traditional directory technologies do not support the use of multiple relationships in a single directory; you’d have to create and maintain additional directories if you needed to do this.
Scale is another important challenge. The fundamental operations on a hierarchy involve locating the parent or the child object of a given object. Given that hierarchies can be used to represent large, nested collections of information, these fundamental operations must be as efficient as possible, regardless of how many objects there are or how deeply they are nested. Traditional directories can be difficult to scale, and the pain only grows if you are using two or more in order to represent multiple hierarchies.
New Amazon Cloud Directory
 Today we are launching Cloud Directory. This service is purpose-built for storing large amounts of strongly typed hierarchical data as described above. With the ability to scale to hundreds of millions of objects while remaining cost-effective, Cloud Directory is a great fit for all sorts of cloud and mobile applications.
Today we are launching Cloud Directory. This service is purpose-built for storing large amounts of strongly typed hierarchical data as described above. With the ability to scale to hundreds of millions of objects while remaining cost-effective, Cloud Directory is a great fit for all sorts of cloud and mobile applications.
Cloud Directory is a building block that already powers other AWS services including Amazon Cognito and AWS Organizations. Because it plays such a crucial role within AWS, it was designed with scalability, high availability, and security in mind (data is encrypted at rest and while in transit).
Amazon Cloud Directory is a managed service; you don’t need to think about installing or patching software, managing servers, or scaling any storage or compute infrastructure. You simply define the schemas, create a directory, and then populate your directory by making calls to the Cloud Directory API. This API is designed for speed and for scale, with efficient, batch-based read and write functions.
The long-lasting nature of a directory, combined with the scale and the diversity of use cases that it must support over its lifetime, brings another challenge to light. Experience has shown that static schemas lack the flexibility to adapt to the changes that arise with scale and with new use cases. In order to address this challenge and to make the directory future-proof, Cloud Directory is built around a model that explicitly makes room for change. You simply extend your existing schemas by adding new facets. This is a safe operation that leaves existing data intact so that existing applications will continue to work as expected. Combining schemas and facets allows you to represent multiple hierarchies within the same directory. For example, your first hierarchy could mirror your org chart. Later, you could add an additional facet to track some additional properties for each employee, perhaps a second phone number or a social network handle. After that, you can could create a geographically oriented hierarchy within the same data: Countries, states, buildings, floors, offices, and employees.
As I mentioned, other parts of AWS already use Amazon Cloud Directory. Cognito User Pools use Cloud Directory to offer application-specific user directories with support for user sign-up, sign-in and multi-factor authentication. With Cognito Your User Pools, you can easily and securely add sign-up and sign-in functionality to your mobile and web apps with a fully-managed service that scales to support hundreds of millions of users. Similarly, AWS Organizations uses Cloud Directory to support creation of groups of related AWS accounts and makes good use of multiple hierarchies to enforce a wide range of policies.
Before we dive in, let’s take a quick look at some important Amazon Cloud Directory concepts:
Directories are named, and must have at least one schema. Directories store objects, relationships between objects, schemas, and policies.
Facets model the data by defining required and allowable attributes. Each facet provides an independent scope for attribute names; this allows multiple applications that share a directory to safely and independently extend a given schema without fear of collision or confusion.
Schemas define the “shape” of data stored in a directory by making reference to one or more facets. Each directory can have one or more schemas. Schemas exist in one of three phases (Development, Published, or Applied). Development schemas can be modified; Published schemas are immutable. Amazon Cloud Directory includes a collection of predefined schemas for people, organizations, and devices. The combination of schemas and facets leaves the door open to significant additions to the initial data model and subject area over time, while ensuring that existing applications will still work as expected.
Attributes are the actual stored data. Each attribute is named and typed; data types include Boolean, binary (blob), date/time, number, and string. Attributes can be mandatory or optional, and immutable or editable. The definition of an attribute can specify a rule that is used to validate the length and/or content of an attribute before it is stored or updated. Binary and string objects can be length-checked against minimum and maximum lengths. A rule can indicate that a string must have a value chosen from a list, or that a number is within a given range.
Objects are stored in directories, have attributes, and are defined by a schema. Each object can have multiple children and multiple parents, as specified by the schema. You can use the multiple-parent feature to create multiple, independent hierarchies within a single directory (sometimes known as a forest of trees).
Policies can be specified at any level of the hierarchy, and are inherited by child objects. Cloud Directory does not interpret or assign any meaning to policies, leaving this up to the application. Policies can be used to specify and control access permissions, user rights, device characteristics, and so forth.
Creating a Directory
Let’s create a directory! I start by opening up the AWS Directory Service Console and clicking on the first Create directory button:
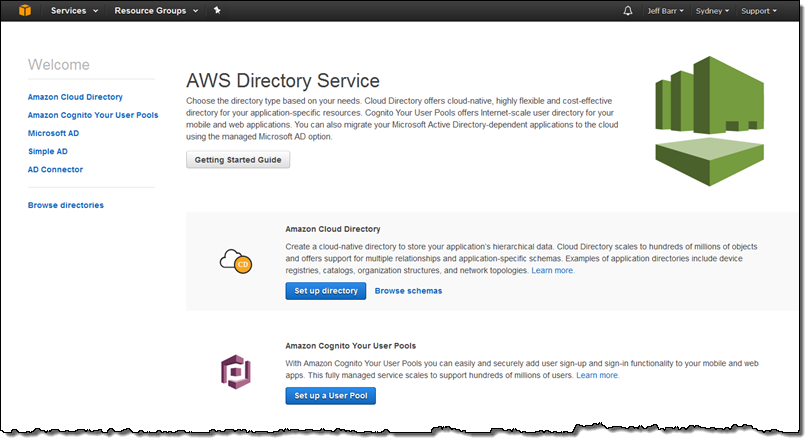
I enter a name for my directory (users), choose the person schema (which happens to have two facets; more about this in a moment), and click on Next:
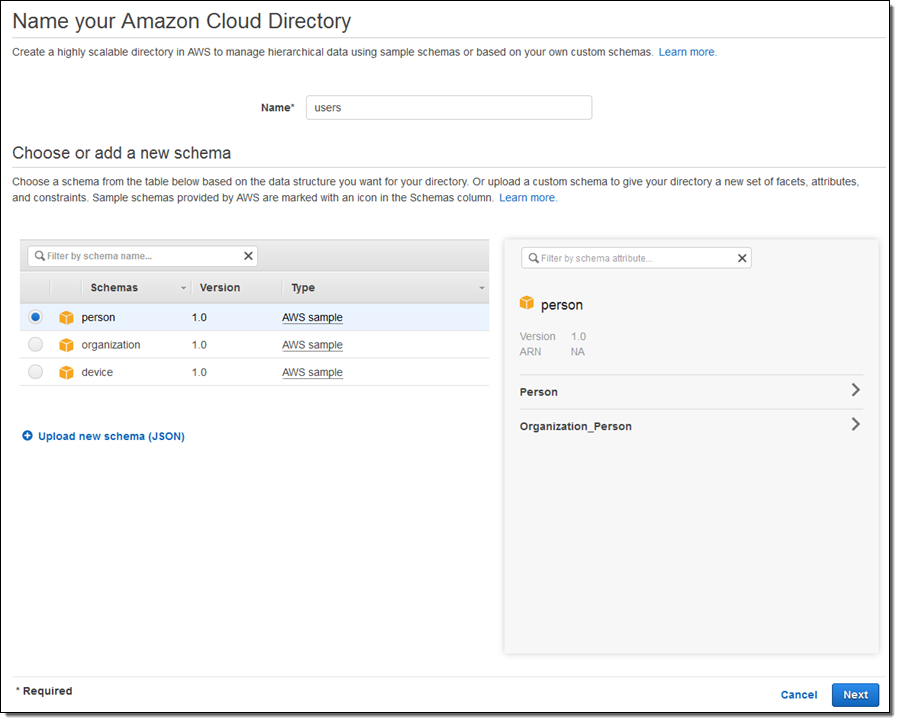
The predefined (AWS) schema will be copied to my directory. I give it a name and a version, and click on Publish:
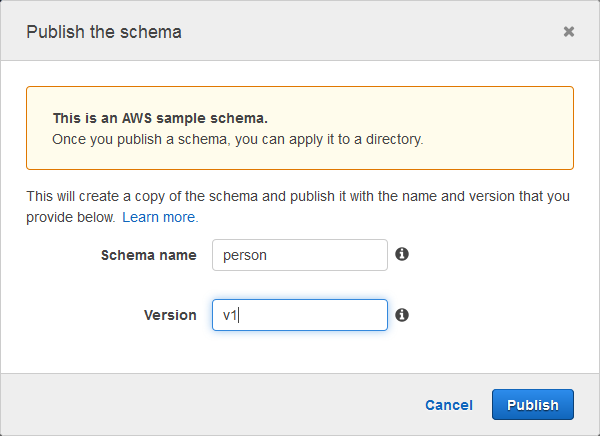
Then I review the configuration and click on Launch:
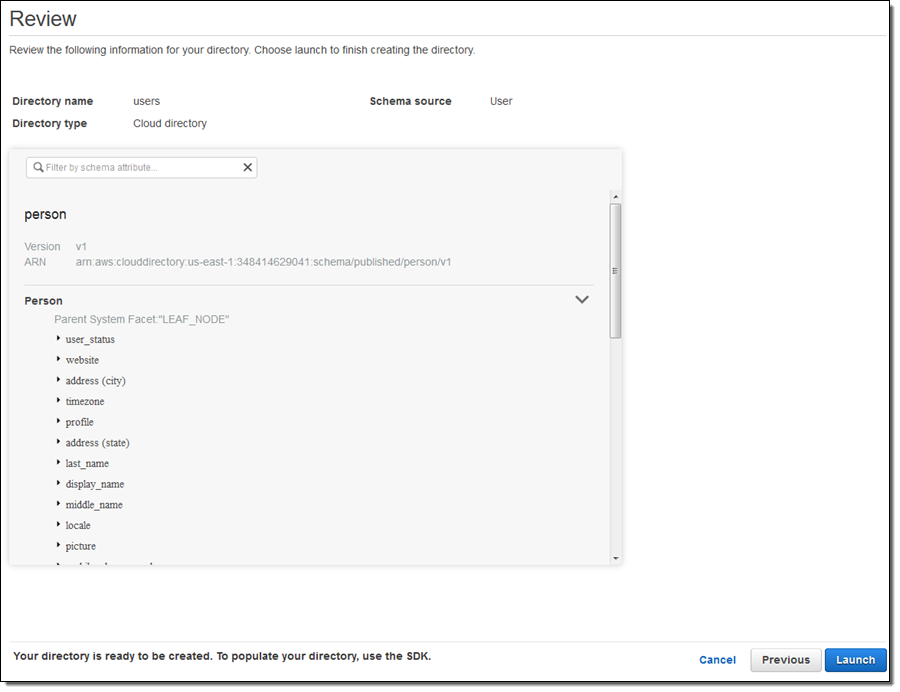
The directory is created, and I can then write code to add objects to it.
Pricing and Availability
Cloud Directory is available now in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), Asia Pacific (Sydney), and Asia Pacific (Singapore) Regions and you can start using it today.
Pricing is based on three factors: the amount of data that you store, the number of reads, and the number of writes (both eventually consistent and strongly consistent reads are available; see the Cloud Directory FAQ to see how the operations are classified). Here are the prices for the US East (N. Virginia) Region:
- Storage – $0.25 / GB / month
- Eventually Consistent Reads – $0.0040 for every 10,000 read API calls
- Strongly Consistent Reads – $0.0043 for every 1,000 read API calls
- Writes – $0.0043 for every 1,000 write API calls
To learn more, check out the Cloud Directory Pricing page.
In the Works
We have some big plans for Cloud Directory!
While the priorities can change due to customer feedback, we are working on cross-region replication, AWS Lambda integration, and the ability to create new directories via AWS CloudFormation.
— Jeff;