AWS News Blog
Cross-Region Export and Import of DynamoDB Tables
Two of the most frequent feature requests for Amazon DynamoDB involve backup/restore and cross-Region data transfer.
 Today we are addressing both of these requests with the introduction of a pair of scalable tools (export and import) that you can use to move data between a DynamoDB table and an Amazon S3 bucket. The export and import tools use the AWS Data Pipeline to schedule and supervise the data transfer process. The actual data transfer is run on an Elastic MapReduce cluster that is launched, supervised, and terminated as part of the import or export operation.
Today we are addressing both of these requests with the introduction of a pair of scalable tools (export and import) that you can use to move data between a DynamoDB table and an Amazon S3 bucket. The export and import tools use the AWS Data Pipeline to schedule and supervise the data transfer process. The actual data transfer is run on an Elastic MapReduce cluster that is launched, supervised, and terminated as part of the import or export operation.
In other words, you simply set up the export (either one-shot or every day, at a time that you choose) or import (one-shot) operation, and the combination of AWS Data Pipeline and Elastic MapReduce will take care of the rest. You can even supply an email address that will be used to notify you of the status of each operation.
Because the source bucket (for imports) and the destination bucket (for exports) can be in any AWS Region, you can use this feature for data migration and for disaster recovery.
Export and Import Tour
Let’s take a quick tour of the export and import features, both of which can be accessed from the DynamoDB tab of the AWS Management Console. Start by clicking on the Export/Import button:
At this point you have two options: You can select multiple tables and click Export from DynamoDB, or you can select one table and click Import into DynamoDB.
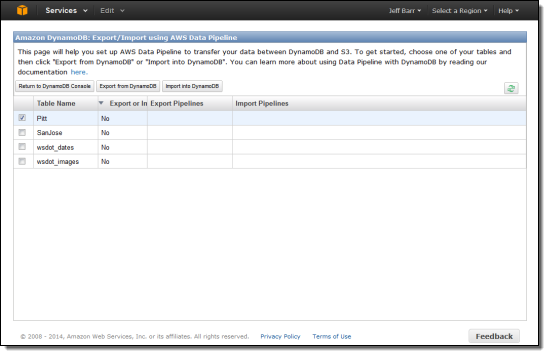
If you click Export from DynamoDB, you can specify the desired S3 buckets for the data and for the log files.
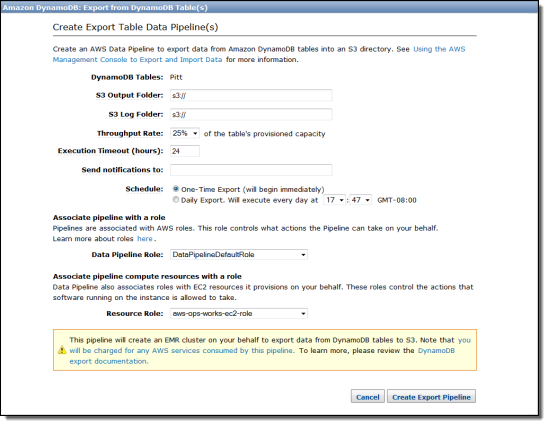
As you can see, you can decide how much of the table’s provisioned throughput to allocate to the export process (10% to 100% in 5% increments). You can run an immediate, one-time export or you can choose to start it every day at the time of your choice. You can also choose the IAM role to be used for the pipeline and for the compute resources that it provisions on your behalf.
I selected one of my tables for immediate export, and watched as the MapReduce job was started up:
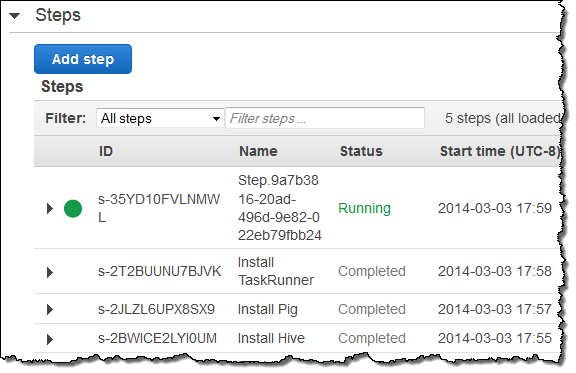
The export operation was finished within a few minutes and my data was in S3:
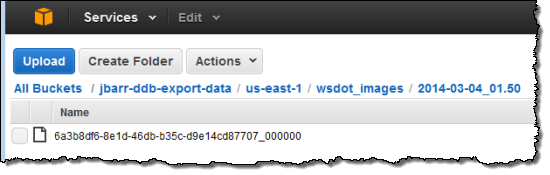
Because the file’s key includes the date and the time as well as a unique identifier, exports that are run on a daily basis will accumulate in S3. You can use S3’s lifecycle management features to control what happens after that.
I downloaded the file and verified that my DynamoDB records were inside:
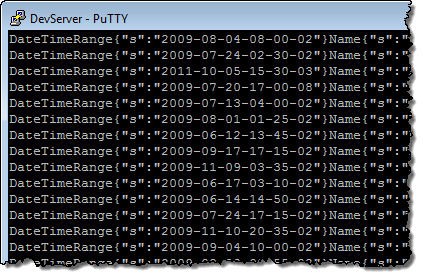
Although you can’t see them in this screen shot, the attribute names are surrounded by the STX and ETX ASCII characters. Refer to the documentation section titled Verify Data File Export for more information on the file format.
The import process is just as simple. You can create as many one-shot import jobs as you need, one table at a time:
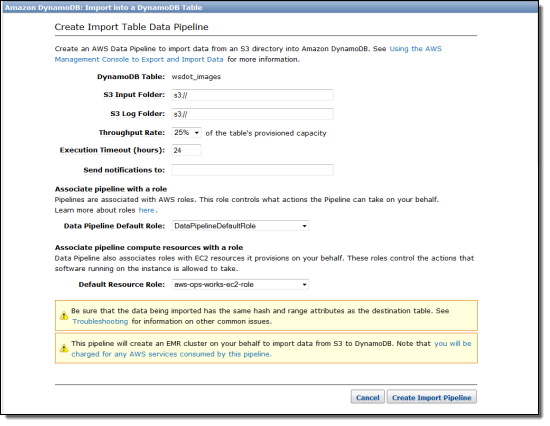
Again, S3 plays an important role here, and you can control how much throughput you’d like to devote to the import process. You will need to point to a specific “folder” for the input data when you set up the import. Although the most common use case for this feature is to import data that was previously exported, you can also export data from an existing relational or NoSQL database, transform it into the structure described here, and import the resulting file into DynamoDB.
— Jeff;