AWS News Blog
DynamoDB Update – Triggers (Streams + Lambda) + Cross-Region Replication App
I’ve got some really good news for Amazon DynamoDB users! First, the DynamoDB Streams feature is now available and you can start using it today. As you will see from this blog post, it is now very easy to use AWS Lambda to process the change records from a stream. Second, we are making it really easy for you to replicate content from one DynamoDB table to another, either across regions or within a region.
Let’s dig in!
DynamoDB Streams
We launched a sneak preview of DynamoDB Streams last fall, just a couple of days before AWS re:Invent. As I wrote at the time, we built this feature because many AWS customers expressed a desire to be able to track the changes made to their DynamoDB tables.

“Interactive Intelligence is excited to be an early adopter of the new Amazon DynamoDB Cross Region Replicas feature. Incorporating this feature into the PureCloud platform has enabled us to quickly and easily replicate data across AWS regions, thus reducing our operational and support costs.”
Mike Szilagyi, Vice President of PureCloud Service Technology
DynamoDB Streams are now ready for production use. Once you enable it for a table, all changes (puts, updates, and deletes) are tracked on a rolling 24-hour basis and made available in near real-time as a stream record. Multiple stream records are grouped in to shards and returned as a unit for faster and more efficient processing.
The relative ordering of a sequence of changes made to a single primary key will be preserved within a shard. Further, a given key will be present in at most one of a set of sibling shards that are active at a given point in time. As a result, your code can simply process the stream records within a shard in order to accurately track changes to an item.
Your code can retrieve the shards, iterate through the records, and process them in any desired way. The records can be retrieved at approximately twice the rate of the table’s provisioned write capacity.
You can enable streams for a table at creation time by supplying a stream specification parameter when you call CreateTable. You can also enable streams for an existing table by supplying a similar specification to UpdateTable. In either case, the specification must include a flag (enable or disable streams), and a view type (store and return item keys only, new image only, old image only, or both new and old images).
Read the new DynamoDB Streams Developer Guide to learn more about this new feature.
You can create DynamoDB Streams on your DynamoDB tables at no charge. You pay only for reading data from your Streams. Reads are measured as read request units; each call to GetRecords is billed as a single request unit and can return up to 1 MB of data. See the DynamoDB Pricing page for more info.
DynamoDB Streams + Lambda = Database Triggers
AWS Lambda makes it easy for you to write, host, and run code (currently Node.js and Java) in the cloud without having to worry about fault tolerance or scaling, all on a very economical basis (you pay only for the compute time used to run your code, in 100 millisecond increments).
As the centerpiece of today’s launch of DynamoDB Streams in production status, we are also making it easy for you to use Lambda to process stream records without writing a lot of code or worrying about scalability as your tables grow larger and busier.
You can think of the combination of Streams and Lambda as a clean and lightweight way to implement database triggers, NoSQL style! Historically, relational database triggers were implemented within the database engine itself. As such, the repertoire of possible responses to an operation is limited to the operations defined by the engine. Using Lambda to implement the actions associated with the triggers (inserting, deleting, and changing table items) is far more powerful and significantly more expressive. You can write simple code to analyze changes (by comparing the new and the old item images), initiate updates to other forms of data, enforce business rules, or activate synchronous or asynchronous business logic. You can allow Lambda to manage the hosting and the scaling so that you can focus on the unique and valuable parts of your application.
Getting set up to run your own code to handle changes is really easy. Let’s take a quick walk-through using a new table. After I create an invocation role for Lambda (so that it can access DynamoDB on my behalf), I open up the Lambda Console and click on Create a Lambda function. Then I choose the blueprint labeled dynamodb-process-stream:
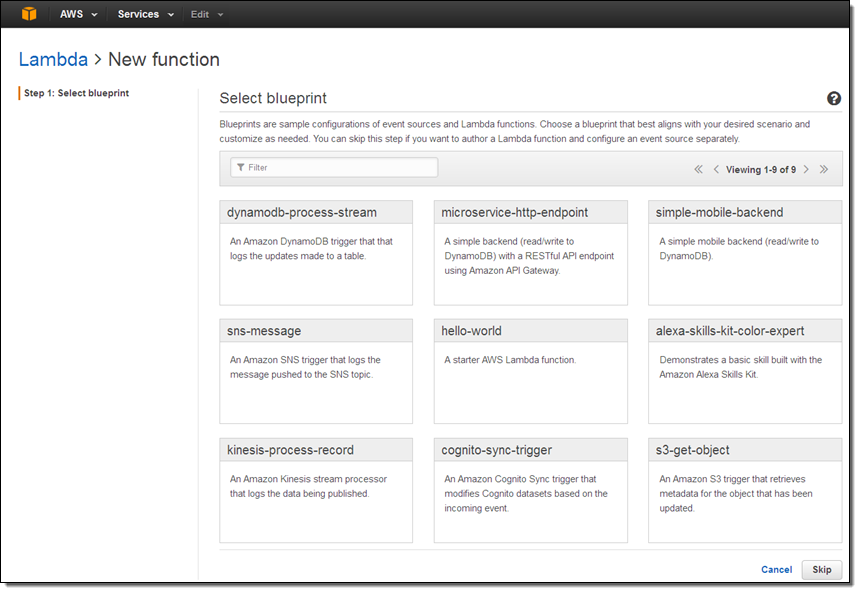 Each blueprint configures an event source and a skeletal Lambda function to get you started. The Console prompts me to configure the event source. I connect it to one of my DynamoDB tables (user_table), indicate that my code can handle batches of up to 100 stream records, and that I want to process new records (I could also choose to process existing records dating back to the stream’s trim horizon):
Each blueprint configures an event source and a skeletal Lambda function to get you started. The Console prompts me to configure the event source. I connect it to one of my DynamoDB tables (user_table), indicate that my code can handle batches of up to 100 stream records, and that I want to process new records (I could also choose to process existing records dating back to the stream’s trim horizon):
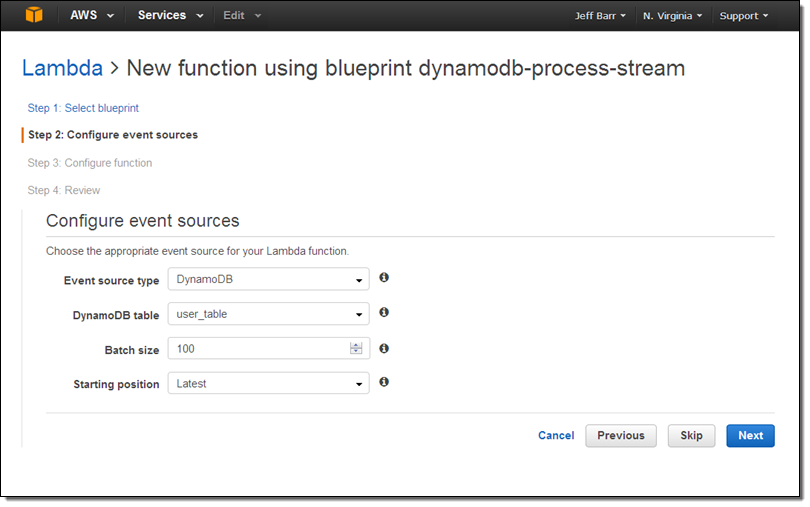
The blueprint includes a function that I can use as-is for testing purposes; I simply give it a name (ProcessUserTableRecords) and choose an IAM role so that the function can access DynamoDB:
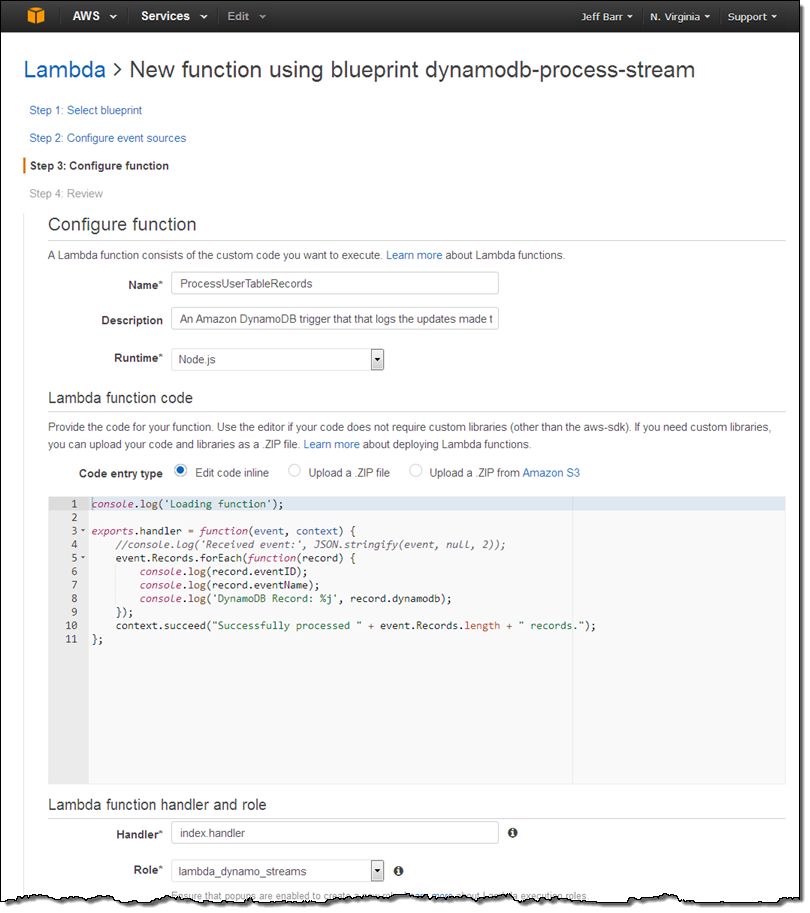
Now I confirm my intent. I will enable the event source (for real development you might want to defer this until after you have written and tested your code):
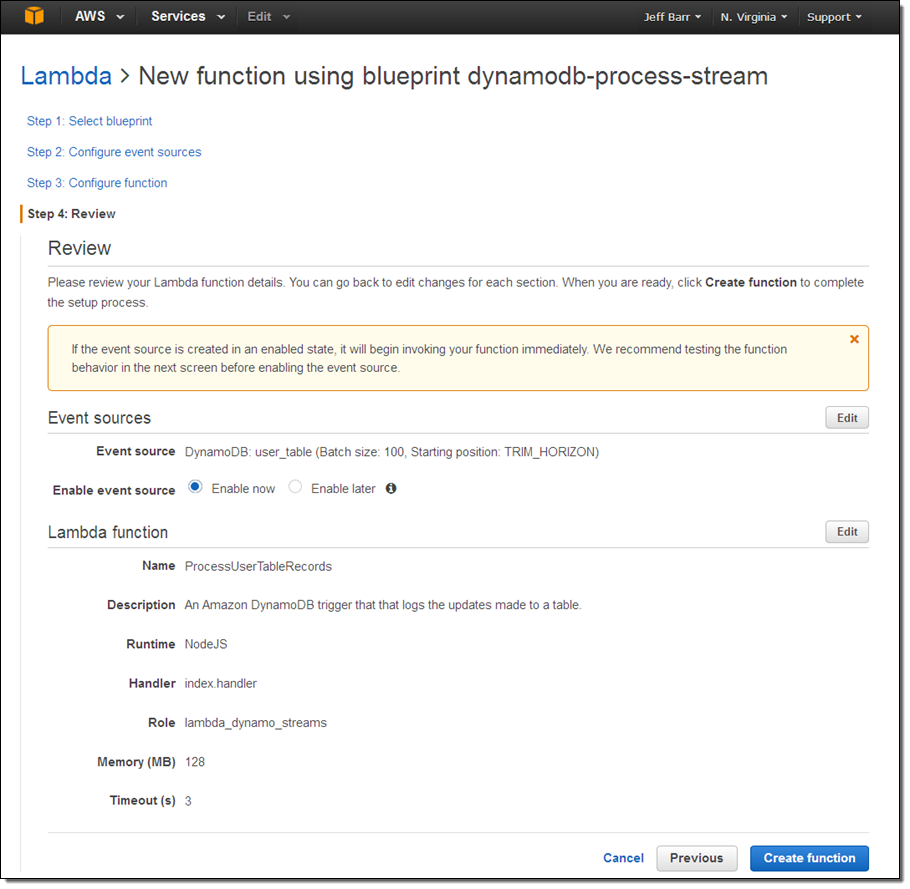
Clicking Create function will create the function and use my table’s update stream as an event source. I can see the status of this and the other event sources on the Event sources tab in the Lambda Console:
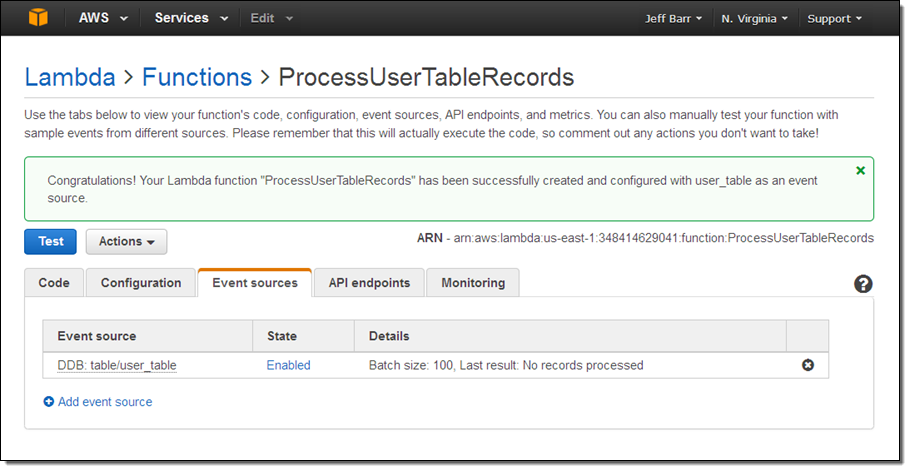
Ok, I am all set. At this point I have a function, it is connected to my table’s update stream, and it is ready to process records! To test this out I switch to the DynamoDB Console and insert a couple of items into my table in order to generate some activity on the stream:
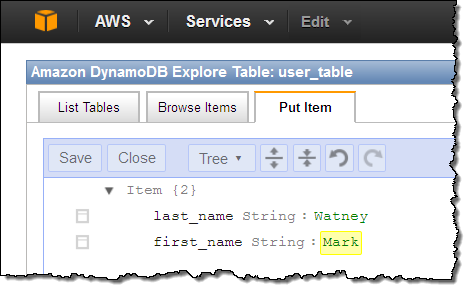
Then I go back to the Lambda Console (browser tabs make all of this really easy, of course) and verify that everything worked as expected. A quick glance at the Monitoring tab confirms that my function ran twice, with no apparent errors:
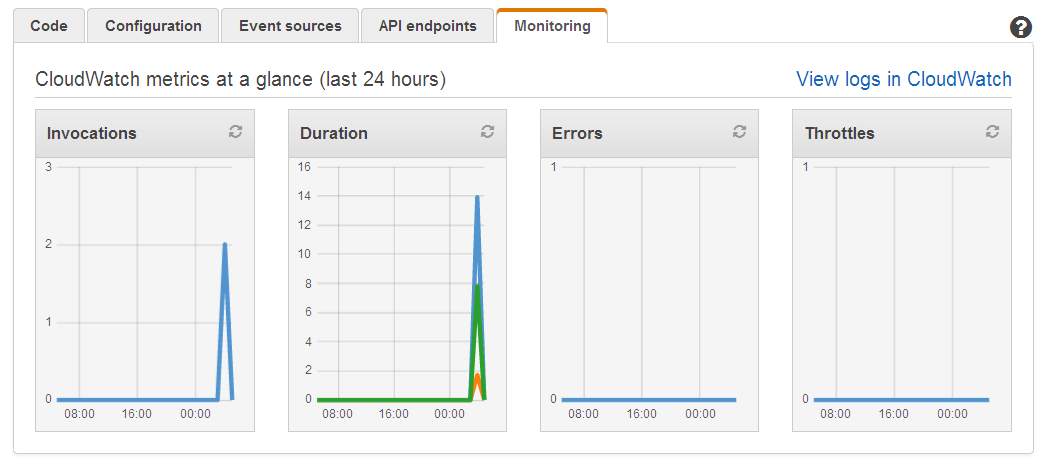
That looks good, so I inspect the CloudWatch Logs for the function to learn more:
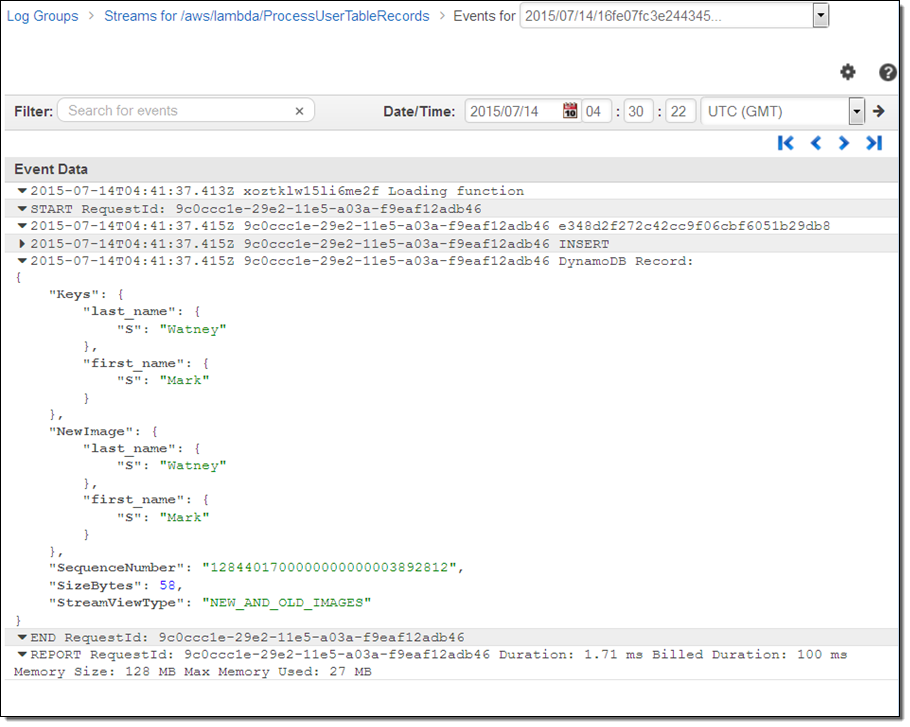
If I was building a real application, I could start with the code provided by the blueprint and add more functionality from there.
AWS customer Mapbox is already making use of DynamoDB Streams and Lambda, take a look at their new blog post, Scaling the Mapbox Infrastructure with DynamoDB Streams.
To learn more about how to use DynamoDB and Lambda together, read the documentation on Using DynamoDB Streams and AWS Lambda. There is no charge for DynamoDB Triggers; you pay the usual rates for the execution of your Lambda functions (see the Lambda Pricing page for more information).
I believe that this new feature will allow you to make your applications simpler, more powerful, and more responsive. Let me know what you build!
Cross-Region DynamoDB Replication
As an example of what can be done with the new DynamoDB Streams feature, we are also releasing a new cross-region replication app for DynamoDB. This application makes use of the DynamoDB Cross Region Replication library that we published last year (you can also use this library as part of your own applications, of course).
You can use replication to duplicate your DynamoDB data across regions for several different reasons including disaster recovery and low-latency access from multiple locations. As you’ll see, the app makes it easy for you to set up and maintain replicas.
This app runs on AWS Elastic Beanstalk and makes use of the Amazon EC2 Container Service, all launched via a AWS CloudFormation template.
You can initiate the launch process from within the DynamoDB Console. CloudFormation will prompt you for the information that it needs to have in order to create the stack and the containers:
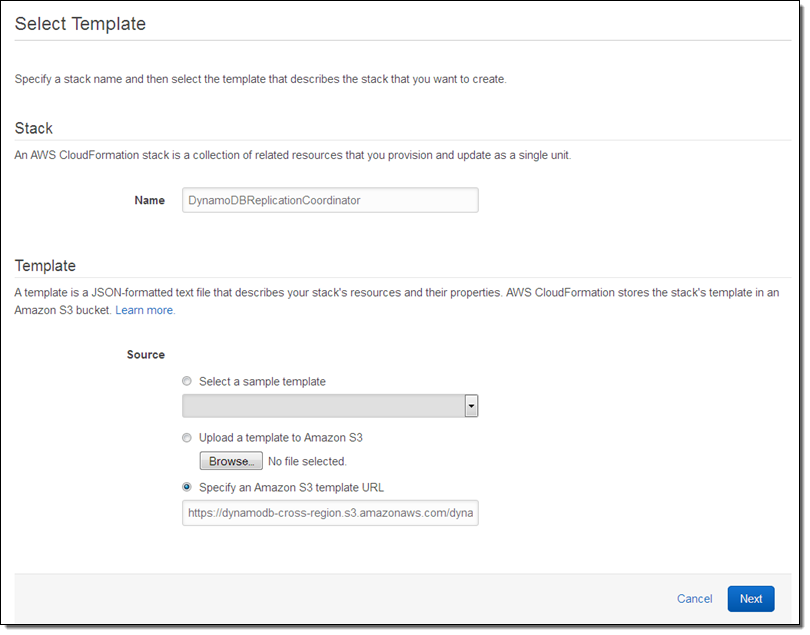
Give the stack (a collective name for the set of AWS resources launched by the template) a name and then click on Next. Then fill in the parameters (you can leave most of these at their default values):
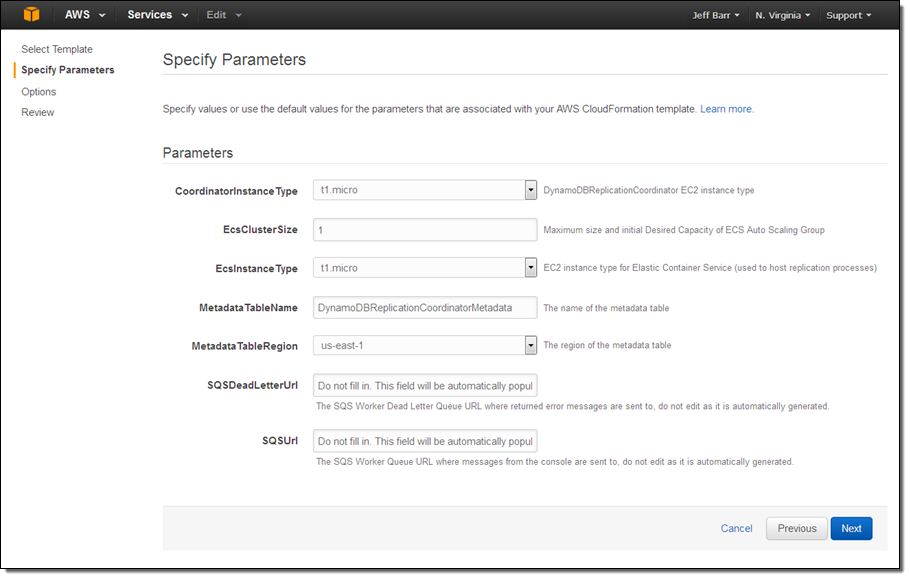
The Metadata table contains the information that the replicator needs to have in order to know which tables to replicate and where the replicas are to be stored. After you launch the replication app you can access its online configuration page (the CloudFormation template will produce a URL) and set things up:
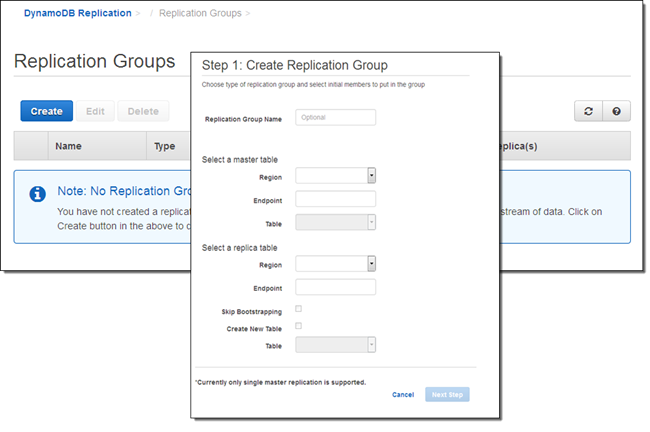
This feature is available to you at no charge. You will be charged for the resources (provisioned throughput and storage for the replica tables, data transfer between regions, reading data from the Streams, the EC2 instances, and the SQS queue that is used to control the application). See the DynamoDB Pricing page for more information.
Read about Cross Region Replication to learn how to set everything up!
— Jeff;