AWS News Blog
Multi-AZ Support / Auto Failover for Amazon ElastiCache for Redis
Like every AWS offering, Amazon ElastiCache started out simple and then grew in breadth and depth over time. Here’s a brief recap of the most important milestones:
- August 2011 – Initial launch with support for the Memcached caching engine in one AWS Region.
- December 2011 – Expansion to four additional Regions.
- March 2012 – The first of several price reductions.
- April 2012 – Introduction of Reserved Cluster Nodes.
- November 2012 – Introduction of four additional types of Cache Nodes.
- September 2013 – Initial support for the Redis caching engine including Replication Groups with replicas for increased read throughput.
- March 2014 – Another price reduction.
- April 2014 – Backup and restore of Redis Clusters.
- July 2014 – Support for M3 and R3 Cache Nodes.
- July 2014 – Node placement across more than one Availability Zone in a Region.
- September 2014 – Support for T2 Cache Nodes.
When you start to use any of the AWS services, you should always anticipate a steady stream of enhancements. Some of them, as you can see from list above, will give you additional flexibility with regard to architecture, scalability, or location. Others will improve your cost structure by reducing prices or adding opportunities to purchase Reserved Instances. Another class of enhancements simplifies the task of building applications that are resilient and fault-tolerant.
Multi-AZ Support for Redis
Today’s launch is designed to help you to add additional resilience and fault tolerance to your Redis Cache Clusters. You can now create a Replication Group that spans multiple Availability Zones with automatic failure detection and failover.
After you have created a Multi-AZ Replication Group, ElastiCache will monitor the health and connectivity of the nodes. If the primary node fails, ElastiCache will select the read replica that has the lowest replication lag (in other words, the one that is the most current) and make it the primary node. It will then propagate a DNS change, create another read replica, and wire everything back together, with no administrative work on your side.
This new level of automated fault detection and recovery will enhance the overall availability of your Redis Cache Clusters. The following situations will initiate the failover process:
- Loss of availability in the primary’s Availability Zone.
- Loss of network connectivity to the primary.
- Failure of the primary.
Creating a Multi-AZ Replication Group
You can create a Multi-AZ Cache Replication Group by checking the Multi-AZ checkbox after selecting Create Cache Cluster:
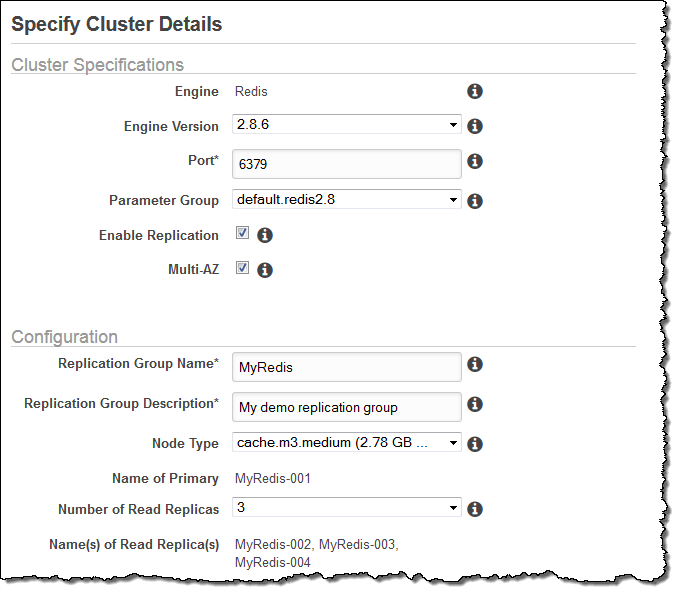
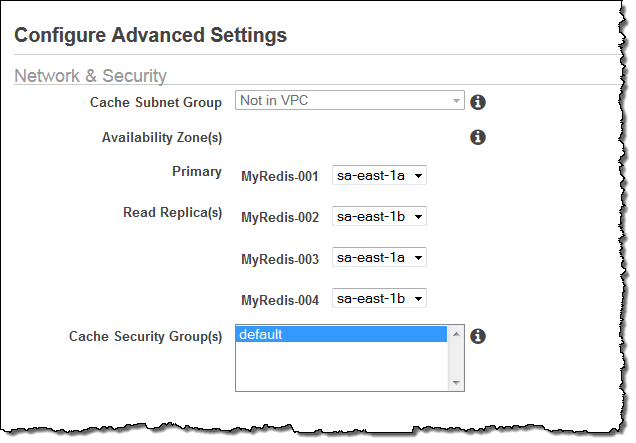
A diverse set of Availability Zones will be assigned by default. You can easily override them in order to better reflect the needs of your application:
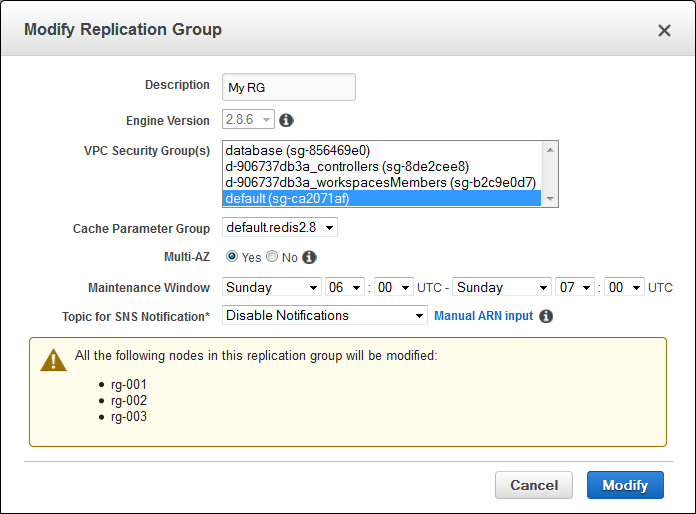
Multi-AZ for Existing Cache Clusters
You can also modify your existing Cache Cluster to add Multi-AZ residency and automatic failover with a couple of clicks.
Things to Know
The Multi-AZ support in ElastiCache for Redis currently makes use of the asynchronous replication that is built in to newer versions (2.8.6 and beyond) of the Redis engine. As such, it is subject to its strengths and weaknesses. In particular, when a read replica connects to a primary for the first time or when the primary changes, the replica will perform a full synchronization with the primary. This ensures that the cached information is as current as possible, but it will impose an additional load on the primary and the read replica(s).
The entire failover process, from detection to the resumption of normal caching behavior, will take several minutes. Your application’s caching tier should have a strategy (and some code!) to deal with a cache that is momentarily unavailable.
Available Now
This new feature is available now in all public AWS Regions and you can start using it today. The feature is offered at no extra charge to all ElastiCache users.
— Jeff;