AWS News Blog
Amazon DynamoDB Update – Global Tables and On-Demand Backup
AWS customers in a wide variety of industries use Amazon DynamoDB to store mission-critical data. Financial services, commerce, AdTech, IoT, and gaming applications (to name a few) make millions of requests per second to individual tables that contain hundreds of terabytes of data and trillions of items, and count on DynamoDB to return results in single-digit milliseconds.
Today we are introducing two powerful new features that I know you will love:
Global Tables – You can now create tables that are automatically replicated across two or more AWS Regions, with full support for multi-master writes, with a couple of clicks. This gives you the ability to build fast, massively scaled applications for a global user base without having to manage the replication process.
On-Demand Backup – You can now create full backups of your DynamoDB tables with a single click, and with zero impact on performance or availability. Your application remains online and runs at full speed. Backups are suitable for long-term retention and archival, and can help you to comply with regulatory requirements.
Global Tables
DynamoDB already replicates your tables across three Availability Zones to provide you with durable, highly available storage. Now you can use Global Tables to replicate your tables across two or more AWS Regions, setting it up with a couple of clicks. You get fast read and write performance that can scale to meet the needs of the most demanding global apps.
 You do not need to make any changes to your existing code. You simply send write requests and eventually consistent read requests to a DynamoDB endpoint in any of the designated Regions (writes that are associated with strongly consistent reads should share a common endpoint). Behind the scenes, DynamoDB implements multi-master writes and ensures that the last write to a particular item prevails. When you use Global Tables, each item will include a timestamp attribute representing the time of the most recent write. Updates are propagated to other Regions asynchronously via DynamoDB Streams and are typically complete within one second (you can track this using the new ReplicationLatency and PendingReplicationCount metrics).
You do not need to make any changes to your existing code. You simply send write requests and eventually consistent read requests to a DynamoDB endpoint in any of the designated Regions (writes that are associated with strongly consistent reads should share a common endpoint). Behind the scenes, DynamoDB implements multi-master writes and ensures that the last write to a particular item prevails. When you use Global Tables, each item will include a timestamp attribute representing the time of the most recent write. Updates are propagated to other Regions asynchronously via DynamoDB Streams and are typically complete within one second (you can track this using the new ReplicationLatency and PendingReplicationCount metrics).
Getting started is simple. You create a table in the usual way, and then do one-click adds to arrange for replication to other Regions. You must start out with empty tables, all with the same name and key configuration (hash and optional sort). All of the tables should also share a consistent set of Auto Scaling, TTL, Local Secondary Index, Global Secondary Index, provisioned throughput settings, and IAM policies. For convenience, Auto Scaling is enabled automatically for new Global Tables.
If you are not using DynamoDB Auto Scaling, you should provision enough read capacity to deal with local reads along with enough write capacity to accommodate writes from all of the tables in the group and for an additional system write for each application write that originates in the local region. The system write is used to support the last-writer-wins model.
Let’s create a Global Table that spans three Regions. I create my table in the usual way and then click on the Global Tables tab:
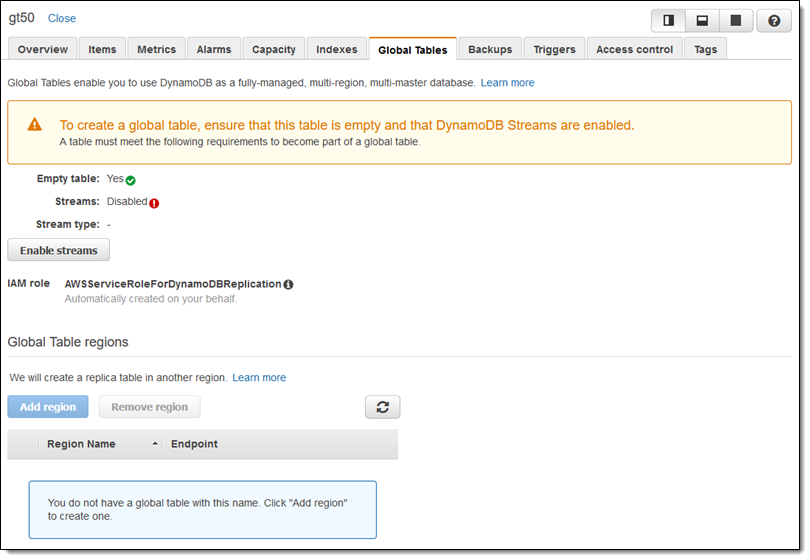
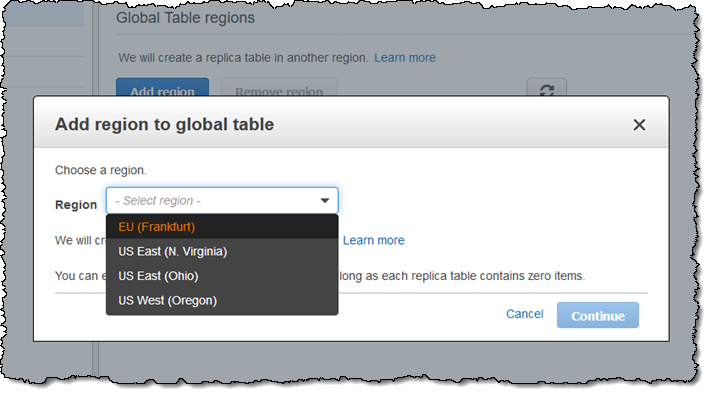
DynamoDB checks the table to make sure that it meets the requirements, and indicates that I need to enable DynamoDB Streams, which I do. Now I click on Add region, chose EU (Frankfurt), and click on Continue:
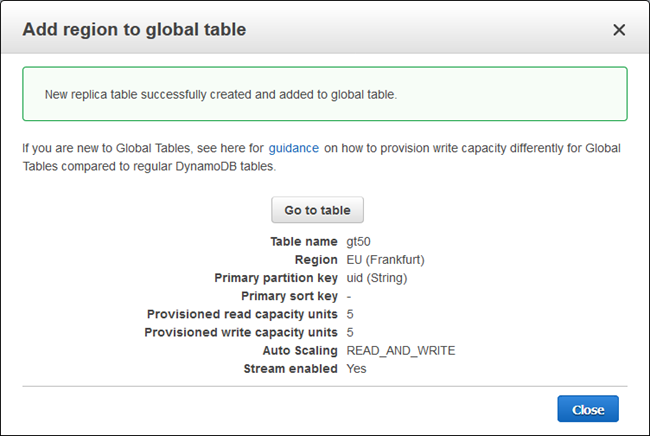
The table is created in a matter of seconds:
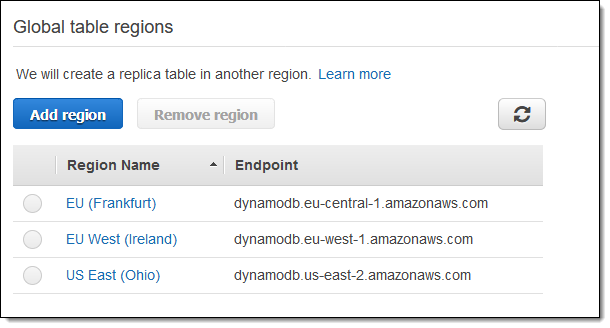
I do this a second time and I now have a global table that spans three AWS Regions:
I create an item in Europe (Ireland):
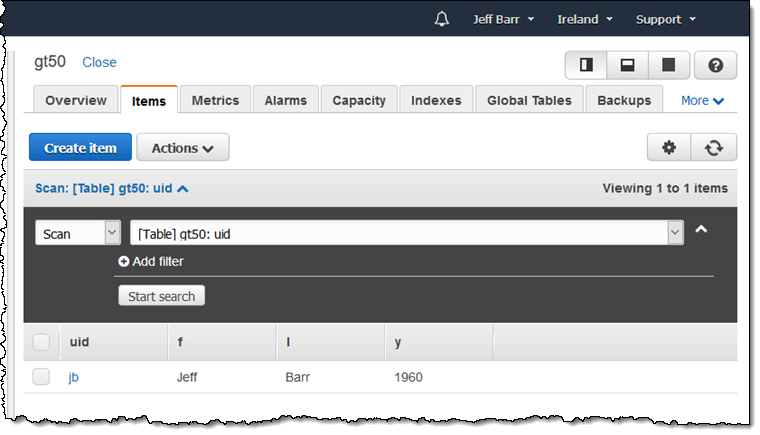
And it shows up in Europe (Frankfurt) right away:
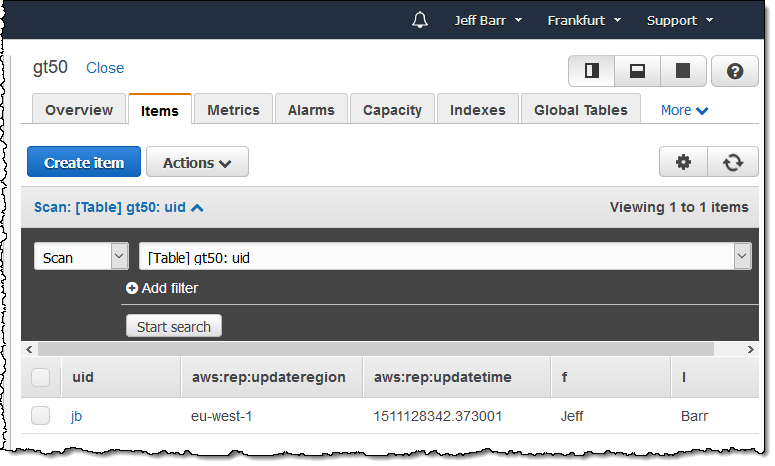
The cross-region replication process adds the aws:rep:updateregion and the aws:rep:updatetime attributes; they are visible to your application but should not be modified.
Global Tables are available in the US East (Ohio), US East (N. Virginia), US West (Oregon), EU (Ireland), and EU (Frankfurt) Regions today, with more Regions in the works for 2018. You pay the usual DynamoDB prices for read capacity and storage, along with data transfer charges for cross-region replication. Write capacity is billed in terms of replicated write capacity units.
On-Demand Backup
This feature is designed to help you to comply with regulatory requirements for long-term archival and data retention. You can create a backup with a click (or an API call) without consuming your provisioned throughput capacity or impacting the responsiveness of your application. Backups are stored in a highly durable fashion and can be used to create fresh tables.
The DynamoDB Console now includes a Backups section:
I simply click on Create backup and give my backup a name:
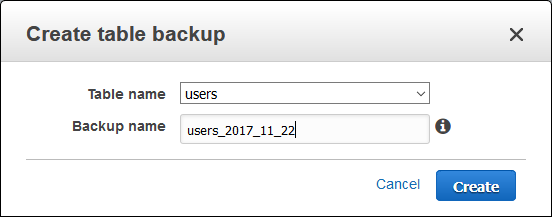
The backup is available right away! It is encrypted with an Amazon-managed key and includes all of the table data, provisioned capacity settings, and settings for Local and Global Secondary Indexes. It does not include Auto Scaling or TTL settings, tags, IAM policies, CloudWatch metrics, or CloudWatch Alarms.
You may be wondering how this operation can be instant, given that some of our customers have tables approaching half of a petabyte. Behind the scenes, DynamoDB takes full snapshots and saves all change logs. Taking a backup is as simple as saving a timestamp along with the current metadata for the table.
Here is my backup:
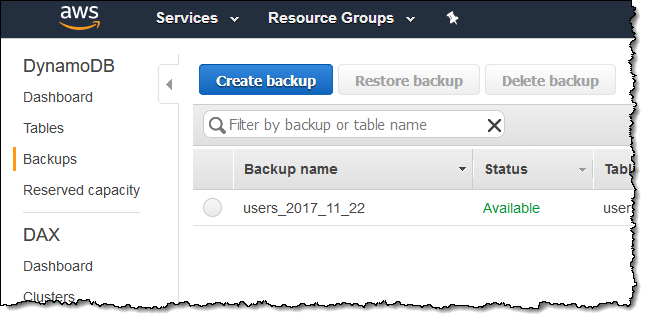
And here’s how I restore it to a new table:
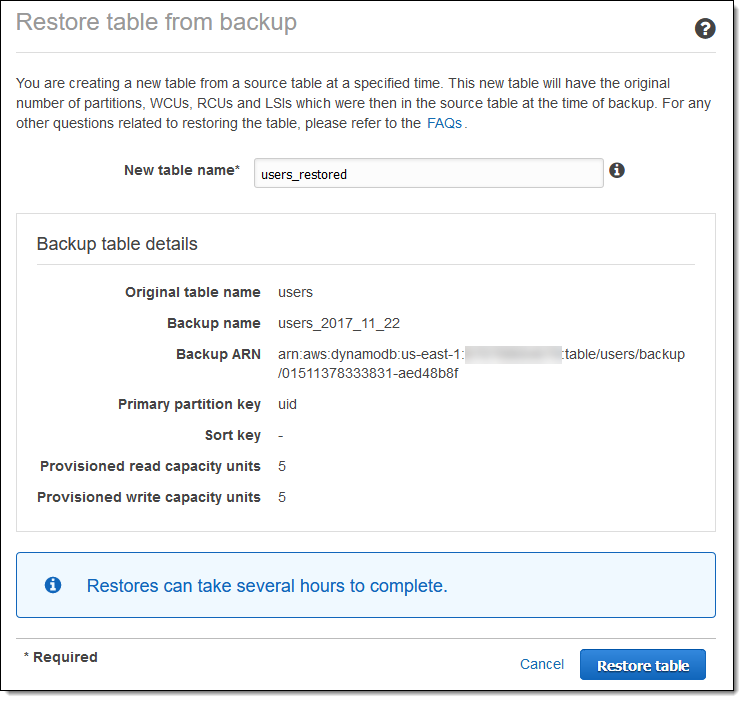
Here are a couple of things to keep in mind about DynamoDB backups:
Setup – After you create a new table, DynamoDB has to do some setup work (basically enough time to eat lunch at your desk) before you can create your first backup.
Restoration – Restoration time depends on the size of the table, with times ranging from 30 minutes to several hours for very large tables.
Availability – We are rolling this new feature out on an account-by-account basis as quickly as possible, with initial availability in the US East (N. Virginia), US East (Ohio), US West (Oregon), and Europe (Ireland) Regions.
Pricing – You pay for backup storage by the gigabyte-month and restore based on the amount of data that you restore.
— Jeff;