AWS Big Data Blog
Best practices to optimize your Amazon Redshift and MicroStrategy deployment
This is a guest blog post co-written by Amit Nayak at Microstrategy. In their own words, “MicroStrategy is the largest independent publicly traded business intelligence (BI) company, with the leading enterprise analytics platform. Our vision is to enable Intelligence Everywhere. MicroStrategy provides modern analytics on an open, comprehensive enterprise platform used by many of the world’s most admired brands in the Fortune Global 500. Optimized for cloud and on-premises deployments, the platform features HyperIntelligence, a breakthrough technology that overlays actionable enterprise data on popular business applications to help users make smarter, faster decisions.”
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse. It provides a simple and cost-effective way to analyze all your data using your existing BI tools. Amazon Redshift delivers fast query performance by using columnar storage technology to improve I/O efficiency and parallelizing queries across multiple nodes. Amazon Redshift has custom JDBC and ODBC drivers that you can download from the Connect Client tab on the Amazon Redshift console, allowing you to use a wide range of familiar BI tools.
When using your MicroStrategy application with Amazon Redshift, it’s important to understand how to optimize Amazon Redshift to get the best performance to meet your workload SLAs.
In this post, we look at the best practices for optimized deployment of MicroStrategy using Amazon Redshift.
Optimize Amazon Redshift
In this section, we discuss ways to optimize Amazon Redshift.
Amazon Redshift RA3 instances
RA3 nodes with managed storage help you optimize your data warehouse by scaling and paying for the compute capacity and managed storage independently. With RA3 instances, you can choose the number of nodes based on your performance requirements, and only pay for the managed storage that you use. Size your RA3 cluster based on the amount of data you process daily without increasing your storage costs.
For additional details about RA3 features, see Amazon Redshift RA3 instances with managed storage.
Distribution styles
When you load data into a table, Amazon Redshift distributes the rows of the table to each of the compute nodes according to the table’s distribution style. When you run a query, the query optimizer redistributes the rows to the compute nodes as needed to perform any joins and aggregations. The goal in choosing a table distribution style is to minimize the impact of the redistribution step by locating the data where it needs to be before the query is run.
When you create a table, you can designate one of four distribution styles: AUTO, EVEN, KEY, or ALL. If you don’t specify a distribution style, Amazon Redshift uses AUTO distribution. With AUTO distribution, Amazon Redshift assigns an optimal distribution style based on the size of the table data. You can use automatic table optimization to get started with Amazon Redshift easily or optimize production workloads while decreasing the administrative effort required to get the best possible performance.
MicroStrategy, like any SQL application, transparently takes advantage of the distribution style defined on base tables. MicroStrategy recommends following Amazon Redshift recommended best practices when implementing the physical schema of the base tables.
Sort keys
Defining a table with a sort key results in the physical ordering of data in the Amazon Redshift cluster nodes based on the sort type and the columns chosen in the key definition. Sorting enables efficient handling of range-restricted predicates to scan the minimal number of blocks on disk to satisfy a query. A contrived example would be having an orders table with 5 years of data with a SORTKEY on the order_date column. Now suppose a query on the orders table specifies a date range of 1 month on the order_date column. In this case, you can eliminate up to 98% of the disk blocks from the scan. If the data isn’t sorted, more of the disk blocks (possibly all of them) have to be scanned, resulting in the query running longer.
We recommend creating your tables with SORTKEY AUTO. This way, Amazon Redshift uses automatic table optimization to choose the sort key. If Amazon Redshift determines that applying a SORTKEY improves cluster performance, tables are automatically altered within hours from the time the cluster was created, with minimal impact to queries.
We also recommend using the sort key on columns often used in the WHERE clause of the report queries. Keep in mind that SQL functions (such as data transformation functions) applied to sort key columns in queries reduce the effectiveness of the sort key for those queries. Instead, make sure that you apply the functions to the compared values so that the sort key is used. This is commonly found on DATE columns that are used as sort keys.
Amazon Redshift Advisor provides recommendations to help you improve the performance and decrease the operating costs for your Amazon Redshift cluster. The Advisor analyzes your cluster’s workload to identify the most appropriate distribution key and sort key based on the query patterns of your cluster.
Compression
Compression settings can also play a big role when it comes to query performance in Amazon Redshift. Compression conserves storage space and reduces the size of data that is read from storage, which reduces the amount of disk I/O and therefore improves query performance.
By default, Amazon Redshift automatically manages compression encoding for all columns in a table. You can specify the ENCODE AUTO option for the table to enable Amazon Redshift to automatically manage compression encoding for all columns in a table. You can alternatively apply a specific compression type to the columns in a table manually when you create the table, or you can use the COPY command to analyze and apply compression automatically.
We don’t recommend compressing the first column in a compound sort key because it might result in scanning more rows than expected.
Amazon Redshift materialized views
Materialized views can significantly boost query performance for repeated and predictable analytical workloads such as dashboarding, queries from BI tools, and extract, load, and transform (ELT) data processing.
Materialized views are especially useful for queries that are predictable and repeated over and over. Instead of performing resource-intensive queries on large tables, applications can query the pre-computed data stored in the materialized view.
For example, consider the scenario where a set of queries is used to populate a collection of charts for a dashboard. This use case is ideal for a materialized view, because the queries are predictable and repeated over and over again. Whenever a change occurs in the base tables (data is inserted, deleted, or updated), the materialized views can be automatically or manually refreshed to represent the current data.
Amazon Redshift can automatically refresh materialized views with up-to-date data from its base tables when materialized views are created with or altered to have the auto-refresh option. Amazon Redshift auto-refreshes materialized views as soon as possible after base tables changes.
To update the data in a materialized view manually, you can use the REFRESH MATERIALIZED VIEW statement at any time. There are two strategies for refreshing a materialized view:
- Incremental refresh – In an incremental refresh, it identifies the changes to the data in the base tables since the last refresh and updates the data in the materialized view
- Full refresh – If incremental refresh isn’t possible, Amazon Redshift performs a full refresh, which reruns the underlying SQL statement, replacing all the data in the materialized view
Amazon Redshift automatically chooses the refresh method for a materialized view depending on the SELECT query used to define the materialized view. For information about the limitations for incremental refresh, see Limitations for incremental refresh.
The following are some of the key advantages using materialized views:
- You can speed up queries by pre-computing the results of complex queries, including multiple base tables, predicates, joins, and aggregates
- You can simplify and accelerate ETL and BI pipelines
- Materialized views support Amazon Redshift local, Amazon Redshift Spectrum, and federated queries
- Amazon Redshift can use automatic query rewrites of materialized views
For example, let’s consider the sales team wants to build a report that shows
the product sales across different stores. This dashboard query is based out of a 3 TB Cloud DW benchmark dataset based on the TPC-DS benchmark dataset.
In this first step, you create a regular view. See the following code:
The following code is a report to analyze the product sales by category:
The preceding reports take approximately 15 seconds to run. As more products are sold, this elapsed time gradually gets longer. To speed up those reports, you can create a materialized view to precompute the total sales per category. See the following code:
The following code analyzes the product sales by category against the materialized view:
The same reports against a materialized view took around 4 seconds because the new queries access precomputed joins, filters, grouping, and partial sums instead of the multiple, larger base tables.
Workload management
Amazon Redshift workload management (WLM) enables you to flexibly manage priorities within workloads so that short, fast-running queries don’t get stuck in queues behind long-running queries. You can use WLM to define multiple query queues and route queries to the appropriate queues at runtime.
You can query WLM in two modes:
- Automatic WLM – Amazon Redshift manages the resources required to run queries. Amazon Redshift determines how many queries run concurrently and how much memory is allocated to each dispatched query. Amazon Redshift uses highly trained sophisticated ML algorithms to make these decisions.
- Query priority is a feature of automatic WLM that lets you assign priority ranks to different user groups or query groups, to ensure that higher-priority workloads get more resources for consistent query performance, even during busy times. For example, consider a critical dashboard report query that has higher priority than an ETL job. You can assign the priority as highest for the report query and high priority to the ETL query.
- No queries are ever starved of resources, and lower priority queries always complete, but may just take longer to complete.
- Manual WLM – With manual WLM, you can manage the system performance by modifying the WLM configuration to create separate queues for long-running queries and short-running queries. You can define up to eight queues to separate workloads from each other. Each queue contains a number of query slots, and each queue is associated with a portion of available memory.
You can also use the Amazon Redshift query monitoring rules (QMR) feature to set metrics-based performance boundaries for workload management (WLM) queues, and specify what action to take when a query goes beyond those boundaries. For example, for a queue that’s dedicated to short-running queries, you might create a rule that cancels queries that run for more than 60 seconds. To track poorly designed queries, you might have another rule that logs queries that contain nested loops. You can use predefined rule templates in Amazon Redshift to get started with QMR.
We recommend the following configuration for WLM:
- Enable automatic WLM
- Enable concurrency scaling to handle an increase in concurrent read queries, with consistent fast query performance
- Create QMR rules to track and handle poorly written queries
After you create and configure different WLM queues, you can use a MicroStrategy query label to set the Amazon Redshift query group for queue assignment. This tells Amazon Redshift which WLM queue to send the query to.
You can set the following as a report pre-statement in MicroStrategy:
You can use MicroStrategy query labels to identify the MicroStrategy submitted SQL statements within Amazon Redshift system tables.
You can use it with all SQL statement types; therefore, we recommend using it for multi-pass SQL reports. When the label of a query is stored in the system view stl_query, it’s truncated to 15 characters (30 characters are stored in all other system tables). For this reason, you should be cautious when choosing the value for query label.
You can set the following as a report pre-statement:
This collects information on the server side about variables like project name, report name, user, and more.
To clean up the query group and release resources, use the cleanup post-statement:
MicroStrategy allows the use of wildcards that are replaced by values retrieved at a report’s run time, as shown in the pre- and post-statements. The following table provides an example of pre- and post-statements.
| VLDB Category | VLDB Property Setting | Value Example |
| Pre/Post Statements | Report Pre-statement | set query_group to 'MSTR=!o;Project=!p;User=!u;Job=!j;' |
| Pre/Post Statements | Cleanup Post-statement | reset query_group; |
For example, see the following code:
Query prioritization in MicroStrategy
In general, you may have multiple applications submitting queries to Amazon Redshift in addition to MicroStrategy. You can use Amazon Redshift query groups to identify MicroStrategy submitted SQL to Amazon Redshift, along with its assignment to the appropriate Amazon Redshift WLM queue.
The Amazon Redshift query group for a MicroStrategy report is set and reset through the use of the following report-level MicroStrategy VLDB properties.
| VLDB Category | VLDB Property Setting | Value Example |
| Pre/Post Statements | Report Pre-statement | set query_group to 'MSTR_High=!o;' |
| Pre/Post Statements | Cleanup Post-statement | reset query_group; |
A MicroStrategy report job can submit one or more queries to Amazon Redshift. In such cases, all queries for a MicroStrategy report are labeled with the same query group and therefore are assigned to same queue in Amazon Redshift.
The following is an example implementation of MicroStrategy Amazon Redshift WLM:
- High-priority MicroStrategy reports are set with report pre-statement
MSTR_HIGH=!o;, medium priority reports withMSTR_MEDIUM=!o;, and low priority reports withMSTR_LOW=!o;. - Amazon Redshift WLM queues are created and associated with corresponding query groups. For example, the
MSTR_HIGH_QUEUEqueue is associated with theMSTR_HIGH=*;query group (where*is an Amazon Redshift wildcard).
Concurrency scaling
With concurrency scaling, you can configure Amazon Redshift to handle spikes in workloads while maintaining consistent SLAs by elastically scaling the underlying resources as needed. When concurrency scaling is enabled, Amazon Redshift continuously monitors the designated workload. If the queries start to get backlogged because of bursts of user activity, Amazon Redshift automatically adds transient cluster capacity and routes the requests to these new clusters. You manage which queries are sent to the concurrency scaling cluster by configuring the WLM queues. This happens transparently in a matter of seconds, so your queries continue to be served with low latency. In addition, every 24 hours that the Amazon Redshift main cluster is in use, you accrue a 1-hour credit towards using concurrency scaling. This enables 97% of Amazon Redshift customers to benefit from concurrency scaling at no additional charge.
For more details on concurrency scaling pricing, see Amazon Redshift pricing.
Amazon Redshift removes the additional transient capacity automatically when activity reduces on the cluster. You can enable concurrency scaling for the MicroStrategy report queue and in case of heavy load on the cluster, the queries run on a concurrent cluster, thereby improving the overall dashboard performance and maintaining a consistent user experience.
To make concurrency scaling work with MicroStrategy, use derived tables instead of temporary tables, which you can do by setting the VLDB property Intermediate table type to Derived table.
In the following example, we enable concurrency scaling on the Amazon Redshift cluster for the MicroStrategy dashboard queries. We create a user group in Amazon Redshift, and all the dashboard queries are allocated to this user group’s queue. With concurrency scaling in place for the report queries, we can see a significant reduction in query wait time.
For this example, we created one WLM queue to run our dashboard queries with highest priority and another ETL queue with high priority. Concurrency scaling is turned on for the dashboard queue, as shown in the following screenshot.

As part of this test, we ran several queries in parallel on the cluster, some of which are ETL jobs (insert, delete, update, and copy), and some are complex select queries, such as dashboard queries. The following graph illustrates how many queries are waiting in the WLM queues and how concurrency scaling helps to address those queries.

In the preceding graph, several queries are waiting in the WLM queues; concurrency scaling automatically starts in seconds to process queries without any delays, as shown in the following graph.
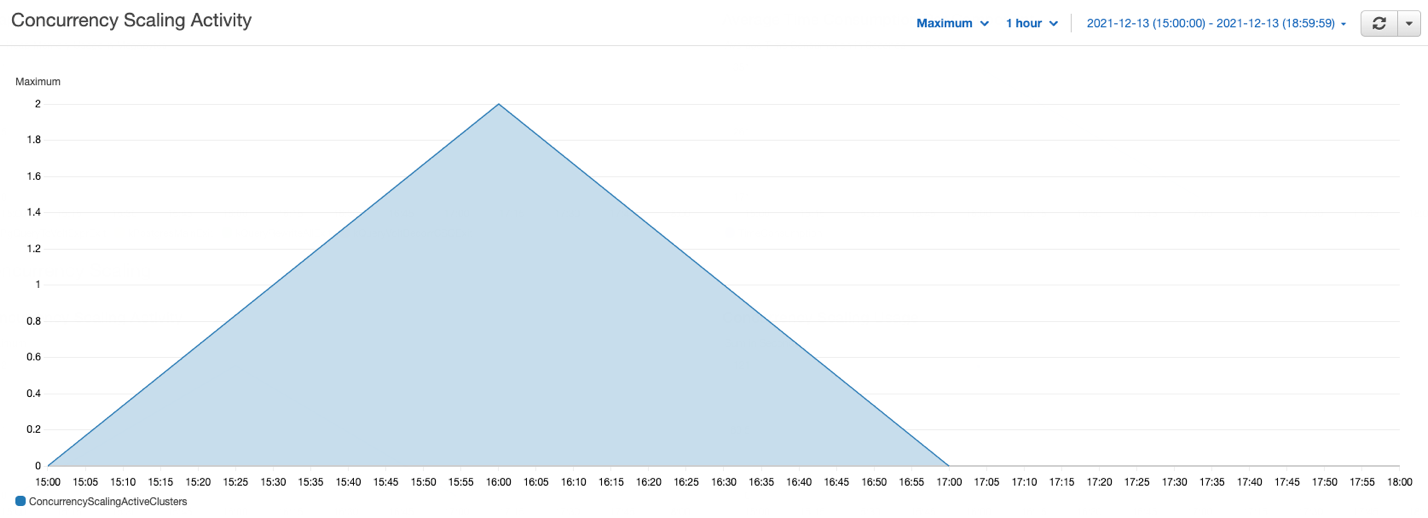
This example has demonstrated how concurrency scaling helps handle spikes in user workloads by adding transient clusters as needed to provide consistent performance even as the workload grows to hundreds of concurrent queries.
Amazon Redshift federated queries
Customers using MicroStrategy often connect various relational data sources to a single MicroStrategy project for reporting and analysis purposes. For example, you might integrate an operational (OLTP) data source (such as Amazon Aurora PostgreSQL) and data warehouse data to get meaningful insights into your business.
With federated queries in Amazon Redshift, you can query and analyze data across operational databases, data warehouses, and data lakes. The federated query feature allows you to integrate queries from Amazon Redshift on live data in external databases with queries across your Amazon Redshift and Amazon Simple Storage Service (Amazon S3) environments.
Federated queries help incorporate live data as part of your MicroStrategy reporting and analysis, without the need to connect to multiple relational data sources from MicroStrategy.
You can also use federated queries to MySQL.
This simplifies the multi-source reports use case by having the ability to run queries on both operational and analytical data sources, without the need to explicitly connect and import data from different data sources within MicroStrategy.
Redshift Spectrum
The MicroStrategy Amazon Redshift connector includes support for Redshift Spectrum, so you can connect directly to query data in Amazon Redshift and analyze it in conjunction with data in Amazon S3.
With Redshift Spectrum, you can efficiently query and retrieve structured and semi-structured data (such as PARQUET, JSON, and CSV) from files in Amazon S3 without having to load the data into Amazon Redshift tables. It allows customers with large datasets stored in Amazon S3 to query that data from within the Amazon Redshift cluster using Amazon Redshift SQL queries with no data movement—you pay only for the data you scanned. Redshift Spectrum also allows multiple Amazon Redshift clusters to concurrently query the same dataset in Amazon S3 without the need to make copies of the data for each cluster. Based on the demands of the queries, Redshift Spectrum can intelligently scale out to take advantage of massively parallel processing.
Use cases that might benefit from using Redshift Spectrum include:
- A large volume of less-frequently accessed data
- Heavy scan-intensive and aggregation-intensive queries
- Selective queries that can use partition pruning and predicate pushdown, so the output is fairly small
Redshift Spectrum gives you the freedom to store your data where you want, in the format you want, and have it available for processing when you need it.
With Redshift Spectrum, you take advantage of a fast, cost-effective engine that minimizes data processed with dynamic partition pruning. You can further improve query performance by reducing the amount of data scanned. You could do this by partitioning and compressing data and by using a columnar format for storage.
For more details on how to optimize Redshift Spectrum query performance and cost, see Best Practices for Amazon Redshift Spectrum.
Optimize MicroStrategy
In this section, we discuss ways to optimize MicroStrategy.
SQL optimizations
With MicroStrategy 2021, MicroStrategy has delivered support for 70 new advanced customizable functions to enhance usability and capability, especially when compared to previously existing Apply functions. Application architects can customize the functions and make them ready and available for regular users like business analysts to use! For more information on how to use these new customizable functions, visit the MicroStrategy community site.
SQL Global Optimization
This setting can substantially reduce the number of SQL passes generated by MicroStrategy. In MicroStrategy, SQL Global Optimization reduces the total number of SQL passes with the following optimizations:
- Eliminates unused SQL passes – For example, a temp table is created but not referenced in a later pass
- Reuses redundant SQL passes – For example, the exact same temp table is created multiple times when a single temp table is created
- Combines SQL passes where the SELECT list is different – For example, two temp tables that have the same FROM clause, joins, WHERE clause, and GROUP BY SELECT lists are combined into single SELECT statement
- Combines SQL passes where the WHERE clause is different – For example, two temp tables that have same the SELECT list, FROM clause, joins, and GROUP BY predicates from the WHERE clause are moved into CASE statements in the SELECT list
The default setting for Amazon Redshift is to enable SQL Global Optimization at its highest level. If your database instance is configured as an earlier version of Amazon Redshift, you may have to enable this setting manually. For more information, see the MicroStrategy System Administration Guide.
Set Operator Optimization
This setting is used to combine multiple subqueries into a single subquery using set operators (such as UNION, INTERSECT, and EXCEPT). The default setting for Amazon Redshift is to enable Set Operator Optimization.
SQL query generation
The MicroStrategy query engine is able to combine multiple passes of SQL that access the same table (typically the main fact table). This can improve performance by eliminating multiple table scans of large tables. For example, this feature significantly reduces the number of SQL passes required to process datasets with custom groups.
Technically, the WHERE clauses of different passes are resolved in CASE statements of a single SELECT clause, which doesn’t contain qualifications in the WHERE clause. Generally, this elimination of WHERE clauses causes a full table scan on a large table.
In some cases (on a report-by-report basis), this approach can be slower than many highly qualified SELECT statements. Because any performance difference between approaches is mostly impacted by the reporting requirement and implementation in the MicroStrategy application, it’s necessary to test both options for each dataset to identify the optimal case.
The default behavior is to merge all passes with different WHERE clauses (level 4). We recommend testing any option for this setting, but most commonly the biggest performance improvements (if any) are observed by switching to the option Level 2: Merge Passes with Different SELECT.
| VLDB Category | VLDB Property Setting | Value |
| Query Optimizations | SQL Global Optimization | Level 2: Merge Passes with Different SELECT |
SQL size
As we explained earlier, MicroStrategy tries to submit a single query statement containing the analytics of multiple passes in the derived table syntax. This can lead to sizeable SQL query syntax. It’s possible for such a statement to exceed the capabilities of the driver or database. For this reason, MicroStrategy governs the size of generated queries and throws an error message if this is exceeded. Starting with MicroStrategy 10.9, this value is tuned to current Amazon Redshift capabilities (16 MB). Earlier versions specify a smaller limit that can be modified using the following VLDB setting on the Amazon Redshift DB instance in Developer.
| VLDB Category | VLDB Property Setting | Value |
| Governing | SQL Size/MDX Size | 16777216 |
Subquery type
There are many cases in which the SQL engine generates subqueries (query blocks in the WHERE clause):
- Reports that use relationship filters
- Reports that use NOT IN set qualification, such as AND NOT
- Reports that use attribute qualification with M-M relationships; for example, showing revenue by category and filtering on catalog
- Reports that raise the level of a filter; for example, dimensional metric at Region level, but qualify on store
- Reports that use non-aggregatable metrics, such as inventory metrics
- Reports that use dimensional extensions
- Reports that use attribute-to-attribute comparison in the filter
The default setting for subquery type for Amazon Redshift is Where EXISTS(select (col1, col2…)):
Some reports may perform better with the option of using a temporary table and falling back to IN for a correlated subquery. Reports that include a filter with an AND NOT set qualification (such as AND NOT relationship filter) will likely benefit from using temp tables to resolve the subquery. However, such reports will probably benefit more from using the Set Operator Optimization option discussed earlier. The other settings are not likely to be advantageous with Amazon Redshift.
| VLDB Category | VLDB Property Setting | Value |
| Query Optimizations | Subquery Type | Use temporary table, falling back to IN for correlated subquery |
Full outer join support
Full outer join support is enabled in the Amazon Redshift object by default. Levels at which you can set this are database instance, report, and template.
For example, the following query shows the use of full outer join with the states_dates and regions tables:
DISTINCT or GROUP BY option (for no aggregation and no table key)
If no aggregation is needed and the attribute defined on the table isn’t a primary key, this property tells the SQL engine whether to use SELECT DISTINCT, GROUP BY, or neither.
Possible values for this setting include:
- Use DISTINCT
- No DISTINCT, no GROUP BY
- Use GROUP BY
The DISTINCT or GROUP BY option property controls the generation of DISTINCT or GROUP BY in the SELECT SQL statement. The SQL engine doesn’t consider this property if it can make the decision based on its own knowledge. Specifically, the SQL engine ignores this property in the following situations:
- If there is aggregation, the SQL engine uses GROUP BY, not DISTINCT
- If there is no attribute (only metrics), the SQL engine doesn’t use DISTINCT
- If there is COUNT (DISTINCT …) and the database doesn’t support it, the SQL engine performs a SELECT DISTINCT pass and then a COUNT(*) pass
- If for certain selected column data types, the database doesn’t allow DISTINCT or GROUP BY, the SQL engine doesn’t do it
- If the SELECT level is the same as the table key level and the table’s true key property is selected, the SQL engine doesn’t issue a DISTINCT
When none of the preceding conditions are met, the SQL engine uses the DISTINCT or GROUP BY property.
Use the latest Amazon Redshift drivers
For running MicroStrategy reports using Amazon Redshift, we encourage upgrading when new versions of the Amazon Redshift drivers are available. Running an application on the latest driver provides better performance, bugs recovery, and better security features. To get the latest driver version based on the OS, see Drivers and Connectors.
Conclusion
In this post, we discussed various Amazon Redshift cluster optimizations, data model optimizations, and SQL optimizations within MicroStrategy for optimizing your Amazon Redshift and MicroStrategy deployment.
About the Authors
 Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 13 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.
Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 13 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.
 Nita Shah is a Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is a Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
 Bosco Albuquerque is a Sr Partner Solutions Architect at AWS and has over 20 years of experience working with database and analytics products from enterprise database vendors and cloud providers, and has helped large technology companies design data analytics solutions as well as led engineering teams in designing and implementing data analytics platforms and data products.
Bosco Albuquerque is a Sr Partner Solutions Architect at AWS and has over 20 years of experience working with database and analytics products from enterprise database vendors and cloud providers, and has helped large technology companies design data analytics solutions as well as led engineering teams in designing and implementing data analytics platforms and data products.
 Amit Nayak is responsible for driving the Gateways roadmap at MicroStrategy, focusing on relational and big data databases, as well as authentication. Amit joined MicroStrategy after completing his master’s in Business Analytics at George Washington University and has maintained an oversight of the company’s gateways portfolio for the 3+ years he has been with the company.
Amit Nayak is responsible for driving the Gateways roadmap at MicroStrategy, focusing on relational and big data databases, as well as authentication. Amit joined MicroStrategy after completing his master’s in Business Analytics at George Washington University and has maintained an oversight of the company’s gateways portfolio for the 3+ years he has been with the company.