AWS Big Data Blog
Dive deep into AWS Glue 4.0 for Apache Spark
Jul 2023: This post was reviewed and updated with Glue 4.0 support in AWS Glue Studio notebook and interactive sessions.
Deriving insight from data is hard. It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless data integration is a key requirement in a modern data architecture to break down data silos. AWS Glue is a serverless data integration service that makes data preparation simpler, faster, and cheaper. You can discover and connect to over 70 diverse data sources, manage your data in a centralized data catalog, and create, run, and monitor data integration pipelines to load data into your data lakes and your data warehouses. AWS Glue for Apache Spark takes advantage of Apache Spark’s powerful engine to process large data integration jobs at scale.
AWS Glue released version 4.0 at AWS re:Invent 2022, which includes many upgrades, such as the new optimized Apache Spark 3.3.0 runtime, Python 3.10, and a new enhanced Amazon Redshift connector.
In this post, we discuss the main benefits that this new AWS Glue version brings and how it can help you build better data integration pipelines.
Spark upgrade highlights
The new version of Spark included in AWS Glue 4.0 brings a number of valuable features, which we highlight in this section. For more details, refer to Spark Release 3.3.0 and Spark Release 3.2.0.
Support for the pandas API
Support for the pandas API allows users familiar with the popular Python library to start writing distributed extract, transform, and load (ETL) jobs without having to learn a new framework API. We discuss this in more detail later in this post.
Python UDF profiling
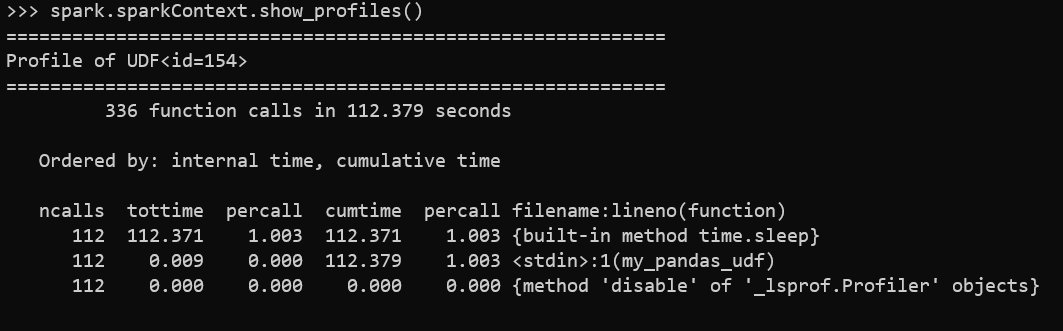
With Python UDF profiling, now you can profile regular and pandas user-defined functions (UDFs). Calling show_profiles() on the SparkContext to get details about the Python run was added on Spark 1 for RDD; now it also works for DataFrame Python UDFs and provides valuable information about how many calls to the UDF are made and how much time is spent on it.
For instance, to illustrate how the profiler measures time, the following example is the profile of a pandas UDF that processes over a million rows (but the pandas UDF only needs 112 calls) and sleeps for 1 second. We can use the command spark.sparkContext.show_profiles(), as shown in the following screenshot.
Pushdown filters
Pushdown filters are used in more scenarios, such as aggregations or limits. The upgrade also offers support for Bloom filters and skew optimization. These improvements allow for handling larger datasets by reading less data and processing it more efficiently. For more information, refer to Spark Release 3.3.0.
ANSI SQL
Now you can ask SparkSQL to follow the ANSI behavior on those points that it traditionally differed from the standard. This helps users bring their existing SQL skills and start producing value on AWS Glue faster. For more information, refer to ANSI Compliance.
Adaptive query execution by default
Adaptive query execution (AQE) by default helps optimize Spark SQL performance. You can turn AQE on and off by using spark.sql.adaptive.enabled as an umbrella configuration. Since AWS Glue 4.0, it’s enabled by default, so you no longer need to enable this explicitly.
Improved error messages
Improved error messages provide better context and easy resolution. For instance, if you have a division by zero in a SQL statement on ANSI mode, previously you would get just a Java exception: java.lang.ArithmeticException: divide by zero. Depending on the complexity and number of queries, the cause might not be obvious and might require some reruns with trial and error until it’s identified.
On the new version, you get a much more revealing error:
Not only does it show the query that caused the issue, but it also indicates the specific operation where the error occurred (the division in this case). In addition, it provides some guidance on resolving the issue.
New pandas API on Spark
The Spark upgrade brings a new, exciting feature, which is the chance to use your existing Python pandas framework knowledge in a distributed and scalable runtime. This lowers the barrier of entry for teams without previous Spark experience, so they can start delivering value quickly and make the most of the AWS Glue for Spark runtime.
The new API provides a pandas DataFrame-compatible API, so you can use existing pandas code and migrate it to AWS Glue for Spark changing the imports, although it’s not 100% compatible.
If you just want to migrate existing pandas code to run on pandas on Spark, you could replace the import and test:
In some cases, you might want to use multiple implementations on the same script, for instance because a feature is still not available on the pandas API for Spark or the data is so small that some operations are more efficient if done locally rather than distributed. In that situation, to avoid confusion, it’s better to use a different alias for the pandas and the pandas on Spark module imports, and to follow a convention to name the different types of DataFrames, because it has implications in performance and features, for instance, pandas DataFrame variables starting with pdf_, pandas on Spark as psdf_, and standard Spark as sdf_ or just df_.
You can also convert to a standard Spark DataFrame calling to_spark(). This allows you to use features not available on pandas such as writing directly to catalog tables or using some Spark connectors.
The following code shows an example of combining the different types of APIs:
Improved Amazon Redshift connector
A new version of the Amazon Redshift connector brings many improvements:
- Pushdown optimizations
- Support for reading SUPER columns
- Writing allowed based on column names instead of position
- An optimized serializer to increase performance when reading from Amazon Redshift
- Other minor improvements like trimming pre- and post-actions and handling numeric time zone formats
This new Amazon Redshift connector is built on top of an existing open-source connector project and offers further enhancements for performance and security, helping you gain up to 10 times faster application performance. It accelerates AWS Glue jobs when reading from Amazon Redshift, and also enables you to run data-intensive workloads more reliably. For more details, see Moving data to and from Amazon Redshift. To learn more about how to use it, refer to New – Amazon Redshift Integration with Apache Spark.
When you use the new Amazon Redshift connector on an AWS Glue DynamicFrame, use the existing methods: GlueContext.create_data_frame and GlueContext.write_data_frame.
When you use the new Amazon Redshift connector on a Spark DataFrame, use the format io.github.spark_redshift_community.spark.redshift, as shown in the following code snippet:
Other upgrades and improvements
The following are updates and improvements in the dependent libraries:
- Spark 3.3.0-amzn-1
- Hadoop 3.3.0-amzn-0
- Hive 2.3.9-amzn-2
- Parquet 1.12
- Log4j 2
- Python 3.10
- Arrow 7.0.0
- Boto3 1.26
- EMRFS 2.54.0
- AWS Glue Data Catalog client 3.7.0
- New versions of the provided JDBC drivers:
- MySQL 8.0.23
- PostgreSQL 42.3.6
- Microsoft SQL Server 9.4.0
- Oracle 21.7
- MongoDB 4.7.2
- Amazon Redshift redshift-jdbc42-2.1.0.16
- Integrated and upgraded plugins to popular table formats:
- Iceberg 1.0.0
- Hudi 0.12.1
- Delta Lake 2.1.0
To learn more, refer to the appendices in Migrating AWS Glue jobs to AWS Glue version 4.0.
Improved performance
In addition to all the new features, AWS Glue 4.0 brings performance improvements at lower cost. In summary, AWS Glue 4.0 with Amazon Simple Storage Service (Amazon S3) is 2.7 times faster than AWS Glue 3.0, and AWS Glue 4.0 with Amazon Redshift is 7.1 times faster than AWS Glue 3.0. In the following sections, we provide details about AWS Glue 4.0 performance results with Amazon S3 and Amazon Redshift.
Amazon S3
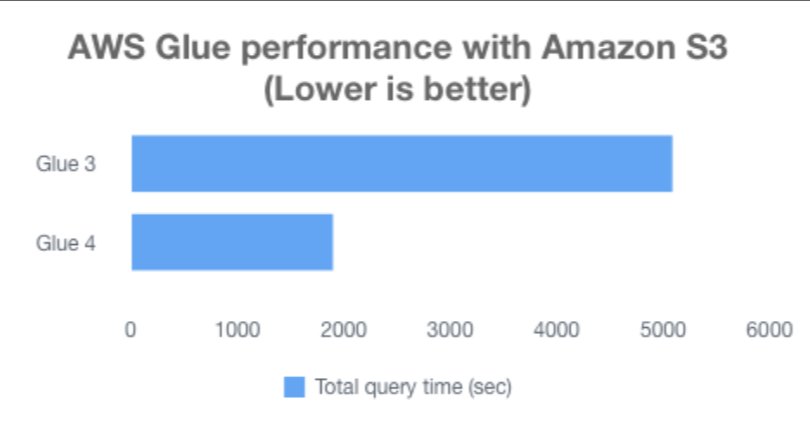
The following chart shows the total job runtime for all queries (in seconds) in the 3 TB query dataset between AWS Glue 3.0 and AWS Glue 4.0. The TPC-DS dataset is located in an S3 bucket in Parquet format, and we used 30 G.2X workers in AWS Glue. We observed that our TPC-DS tests on Amazon S3 had a total job runtime on AWS Glue 4.0 that was 2.7 times faster than that on AWS Glue 3.0. Detailed instructions are explained in the appendix of this post.
| . | AWS Glue 3.0 | AWS Glue 4.0 |
| Total Query Time | 5084.94274 | 1896.1904 |
| Geometric Mean | 14.00217 | 10.09472 |
Amazon Redshift
The following chart shows the total job runtime for all queries (in seconds) in the 1 TB query dataset between AWS Glue 3.0 and AWS Glue 4.0. The TPC-DS dataset is located in a five-node ra3.4xlarge Amazon Redshift cluster, and we used 150 G.2X workers in AWS Glue. We observed that our TPC-DS tests on Amazon Redshift had a total job runtime on AWS Glue 4.0 that was 7.1 times faster than that on AWS Glue 3.0.
| . | AWS Glue 3.0 | AWS Glue 4.0 |
| Total Query Time | 22020.58 | 3075.96633 |
| Geometric Mean | 142.38525 | 8.69973 |

Get started with AWS Glue 4.0
You can start using AWS Glue 4.0 via AWS Glue Studio, the AWS Glue console, the latest AWS SDK, and the AWS Command Line Interface (AWS CLI).
To start using AWS Glue 4.0 jobs in AWS Glue Studio, open the AWS Glue job and on the Job details tab, choose the version Glue 4.0 – Supports spark 3.3, Scala 2, Python 3.

To start using AWS Glue 4.0 on an AWS Glue Studio notebook or interactive sessions, set 4.0 in the %glue_version magic: 
To migrate your existing AWS Glue jobs from AWS Glue 0.9, 1.0, 2.0, and 3.0 to AWS Glue 4.0, see Migrating AWS Glue jobs to AWS Glue version 4.0.
The AWS Glue 4.0 Docker images are now available on Docker Hub, so you can use them to develop locally for the new version. Refer to Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container for further details.
Conclusion
In this post, we discussed the main upgrades provided by the new 4.0 version of AWS Glue. You can already start writing new jobs on that version and benefit from all the improvements, as well as migrate your existing jobs.
About the authors
 Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team. He’s been an Apache Spark enthusiast since version 0.8. In his spare time, he likes playing board games.
Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team. He’s been an Apache Spark enthusiast since version 0.8. In his spare time, he likes playing board games.
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
 Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies.
Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies.
 Rajendra Gujja is a Senior Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about the data.
Rajendra Gujja is a Senior Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about the data.
 Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on solving challenging distributed systems problems for data integration on Glue platform for customers using Apache Spark.
Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on solving challenging distributed systems problems for data integration on Glue platform for customers using Apache Spark.
 Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team works on distributed systems for building data lakes on AWS and simplifying integration with data warehouses for customers using Apache Spark.
Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team works on distributed systems for building data lakes on AWS and simplifying integration with data warehouses for customers using Apache Spark.
Appendix: TPC-DS benchmark on AWS Glue against a dataset on Amazon S3
To perform a TPC-DS benchmark on AWS Glue against a dataset in an S3 bucket, you need to copy the TPC-DS dataset into your S3 bucket. These instructions are based on emr-spark-benchmark:
- Create a new S3 bucket in your test account if needed. In the following code, replace
$YOUR_S3_BUCKETwith your S3 bucket name. We suggest you exportYOUR_S3_BUCKETas an environment variable:
- Copy the TPC-DS source data as input to your S3 bucket. If it’s not exported as an environment variable, replace
$YOUR_S3_BUCKETwith your S3 bucket name:
- Build the benchmark application following the instructions in Steps to build spark-benchmark-assembly application.
For your convenience, we have provided the sample application JAR file spark-benchmark-assembly-3.3.0.jar, which we built for AWS Glue 4.0.
- Upload the spark-benchmar-assembly JAR file to your S3 bucket.
- In AWS Glue Studio, create a new AWS Glue job through the script editor:
- Under Job details, for Type, choose Spark.
- For Glue version, choose Glue 4.0 – Supports spark 3.3, Scala 2, Python 3.
- For Language, choose Scala.
- For Worker type, choose your preferred worker type.
- For Requested number of workers, choose your preferred number.
- Under Advanced properties, for Dependent JARs path, enter your S3 path for the
spark-benchmark-assemblyJAR file. - For Script, enter the following code snippet:
- Save and run the job.
The result file will be stored under s3://YOUR_S3_BUCKET/blog/GLUE_TPCDS-TEST-3T-RESULT/.