AWS Big Data Blog
How Tricentis unlocks insights across the software development lifecycle at speed and scale using Amazon Redshift
This is a guest post co-written with Parag Doshi, Guru Havanur, and Simon Guindon from Tricentis.
Tricentis is a global leader in continuous testing for DevOps, cloud, and enterprise applications. It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release seven times fewer defects. Speed changes everything, and continuous testing across the entire CI/CD lifecycle is the key. However, speed is only realized when you have the confidence to release software on demand. Tricentis instills that confidence by providing software tools that enable Agile Continuous Testing (ACT) at scale. Whether exploratory or automated, functional or performance, API or UI, targeting mainframes, custom applications, packaged applications, or cloud-native applications, Tricentis provides a comprehensive suite of specialized continuous testing tools that help its customers achieve the confidence to release on demand.
The next phase of Tricentis’ journey is to unlock insights across all testing tools. Teams may struggle to have a unified view of software quality due to siloed testing across many disparate tools. For users that require a unified view of software quality, this is unacceptable. In this post, we share how the AWS Data Lab helped Tricentis to improve their software as a service (SaaS) with insights powered by Amazon Redshift.
The challenge
Tricentis provides SaaS and on-premises solutions to thousands of customers globally. Every change to software worth testing is tracked in test management tools such as Tricentis qTest, test automation tools such as Tricentis Tosca or Tricentis Testim, or performance testing tools such as Tricentis NeoLoad. Although Tricentis has amassed such data over a decade, it remains untapped for valuable insights. Each of these tools has its own reporting capabilities which can make it challenging to combine the data for integrated and actionable business insights.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands.
Finally, data integrity is of paramount importance. Every event in the data source can be relevant, and our customers don’t tolerate data loss, poor data quality, or discrepancies between the source and analytics coming from Tricentis. While aggregating, summarizing, and aligning to a common information model, all transformations must not affect the integrity of data from its source.
The solution
Tricentis aims to address the challenges of providing high volume, near-real-time, and visually appealing reporting and analytics across the entire Tricentis product portfolio.
The initial customer objectives were:
- Provide export of data securely accessible from the AWS Cloud
- Provide an initial set of pre-built dashboards that provide immediate business insights
- Beta test a solution with early adopter customers within six weeks
Considering the multi-tenant data source, Tricentis and the AWS Data Lab team engineered for the following constraints:
- Deliver the end-to-end pipeline to load only the eligible customers into an analytics repository
- Transform the multi-tenant data into single-tenant data isolated for each customer in strictly segregated environments
Knowing that data will be unified across many sources deployed in any environment, the architecture called for an enterprise-grade analytics platform. The data pipeline consists of multiple layers:
- Ingesting data from the source either as application events or change data capture (CDC) streams
- Queuing data so that we can rewind and replay the data back in time without going back to the source
- Light transformations such as splitting multi-tenant data into single tenant data to isolate customer data
- Persisting and presenting data in a scalable and reliable lake house (data lake and data warehouse) repository
Some customers will access the repository directly via an API with the proper guardrails for stability to combine their test data with other data sources in their enterprise, while other customers will use dashboards to gain insights on testing. Initially, Tricentis defines these dashboards and charts to enable insight on test runs, test traceability with requirements, and many other pre-defined use cases that can be valuable to customers. In the future, more capabilities will be provided to end-users to come up with their own analytics and insights.
How Tricentis and the AWS Data Lab were able to establish business insights in six weeks
Given the challenge of Tricentis Analytics with live customers in six weeks, Tricentis partnered with the AWS Data Lab. From detailed design to a beta release, Tricentis had customers expecting to consume data from a data lake specific to only their data, and all of the data that had been generated for over a decade. Customers also required their own repository, an Apache Parquet data lake, which would combine with other data in the customer environment to gather even greater insights.
The AWS account team proposed the AWS Data Lab Build Lab session to help Tricentis accelerate the process of designing and building their prototype. The Build Lab is a two-to-five-day intensive build by a team of customer builders with guidance from an AWS Data Lab Solutions Architect. During the Build Lab, the customer will construct a prototype in their environment, using their data, with guidance on real-world architectural patterns and anti-patterns, as well as strategies for building effective solutions, from AWS service experts. Including the pre-lab preparation work, the total engagement duration is three-six weeks and in the Tricentis case was three weeks: two for the pre-lab preparation work and one for the lab. The weeks that followed the lab included go-to-market activities with specific customers, documentation, hardening, security reviews, performance testing, data integrity testing, and automation activities.
The two weeks before the lab were used for the following:
- Understanding the use case and working backward with an architecture
- Preparing the Tricentis team for the lab by delivering all the training on the services to be used during the lab
For this solution, Tricentis and AWS built a data pipeline that consumes data from streaming, which was in place before the lab, and this streaming has the database transactions captured through CDC. In the streaming, the data from each table is separated by topic, and data from all the customers comes on the same topic (no isolation). Because of that, a pipeline was created to separate customers to create their tables isolated by the schema on the final destination at Amazon Redshift. The following diagram illustrates the solution architecture.
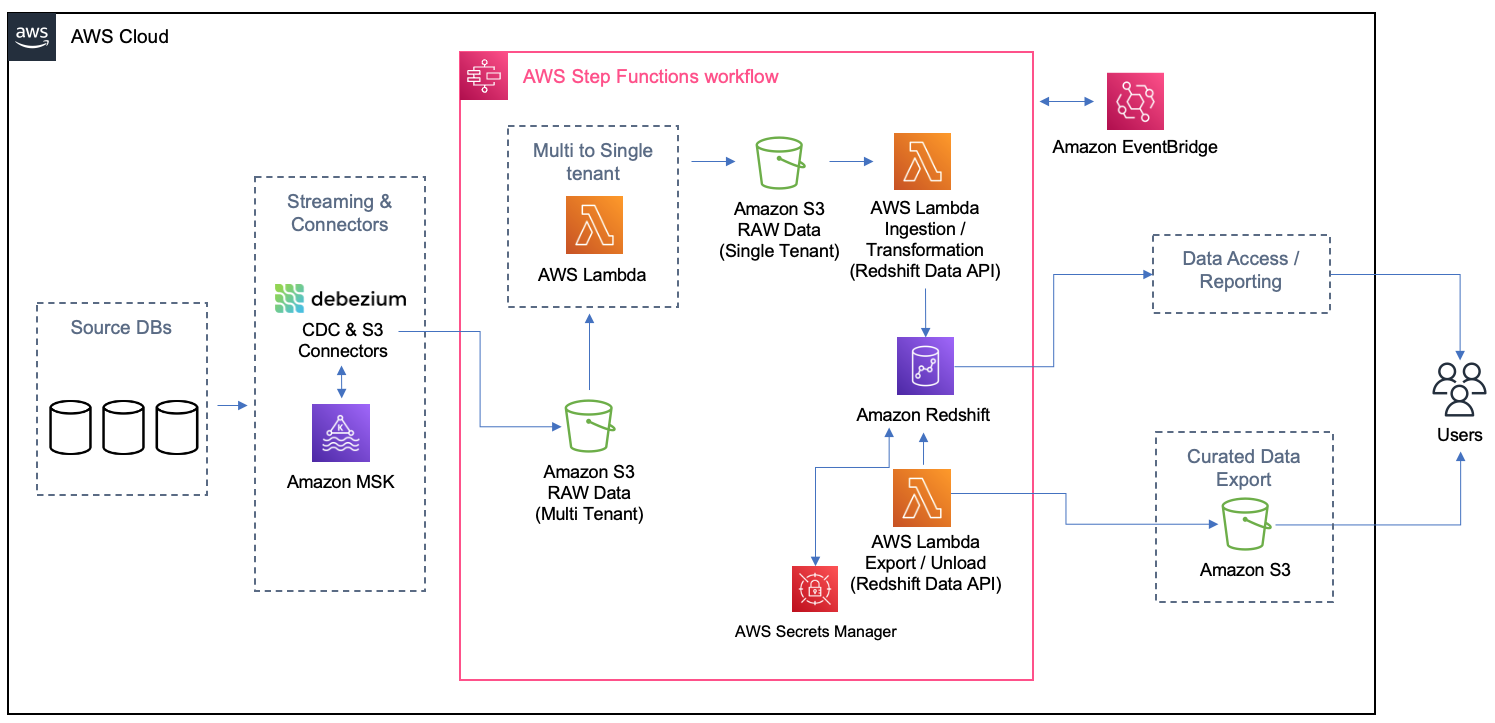
The main idea of this architecture is to be event-driven with eventual consistency. Any time new test cases or test results are created or modified, events trigger such that processing is immediate and new snapshot files are available via an API or data is pulled at the refresh frequency of the reporting or business intelligence (BI) tool. Every time the Amazon Simple Storage Service (Amazon S3) sink connector from Apache Kafka delivers a file on Amazon S3, Amazon EventBridge triggers an AWS Lambda function to transform the multi-tenant file into separated files, one per customer per table, and land it on specific folders on Amazon S3. As the files are created, another process is triggered to load the data from each customer on their schema or table on Amazon Redshift. On Amazon Redshift, materialized views were used to get the queries for the dashboards ready and easier to be returned to the Apache Superset. Also, the materialized views were configured to refresh automatically (with the autorefresh option), so Amazon Redshift updates the data automatically in the materialized views as soon as possible after base tables changes.
In the following sections, we detail specific implementation challenges and additional features required by customers discovered along the way.
Data export
As stated earlier, some customers want to get an export of their test data and create their data lake. For these customers, Tricentis provides incremental data as Apache Parquet files and will have the ability to filter on specific projects and specific date ranges. To ensure data integrity, Tricentis uses its technology known as Tricentis Data Integrity (not part of the AWS Data Lab session).
Data security
The solution uses the following data security guardrails:
- Data isolation guardrails – Tricentis source databases systems are used by all customers, and therefore, data from different customers is in the same database. To isolate customer-specific data, Tricentis has a unique identifier that discriminates customer-specific data. All the queries filter data based on the discriminator to get customer-specific data. EventBridge triggers a Lambda function to transform multi-tenant files to single-tenant (customer) files to land in customer-specific S3 folders. Another Lambda function is triggered to load data from customer-specific folders to their specific schema in Amazon Redshift. The latter Lambda function is data isolation aware and triggers an alert and stops processing further for any data that doesn’t belong to a specific customer.
- Data access guardrails – To ensure access control, Tricentis applied role-based access control principles to users and service accounts for specific work-related resources. Access to Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon S3, Amazon Relational Database Service (Amazon RDS), and Amazon Redshift was controlled by granting privileges at the role level and assigning those roles appropriate resources.
Pay per use and linear cost scalability
Tricentis’ objective is to pay for the compute and storage used and grow analytics infrastructure with linear cost scalability. To better manage storage costs in the data plane, Tricentis stores all raw and intermediate data in Amazon S3 storage in a compressed format. The Amazon MSK and Amazon Redshift is right-sized for the Tricentis analytics load and is allowed to scale up or down with no downtime based on future business needs. Data on all the stores, including Amazon MSK, Amazon Redshift, and Amazon S3, is subjected to tiered storage and retention policies per the customer data retention and archival requirements to reduce the cost further and provide linear cost scalability.
In the control plane, Debezium and Kafka Connect resources are turned on and off, so you only pay for what you use. Lambda triggers are triggered on an event or a schedule and turned off after completing tasks.
Automated data integrity
High data integrity is a fundamental design principle behind analytics for the Tricentis platform. Fortunately, Tricentis has a product called Tricentis Data Integrity, which is used to automate the measurement of data integrity across many different data sources. The main idea is to use the machine-generated data type and log sequence number (LSN) to reflect the latest snapshot data from the change data capture (CDC) streams. Tricentis reached the data integrity automation milestone outside of the AWS Data Lab window by automatically triggering Tosca DI at various stages of the AWS serverless architecture (illustrated earlier), and because of that Tricentis was able to ensure expected record counts at every step, preventing data loss or inadvertent data manipulation. In future versions, Tricentis will have much deeper data integrity verification record counts and incorporate specific fields to ensure data quality (for example, nullness) and semantic or format validation. To date, the combination of CDC and data cleansing has resulted in ultra-high data integrity when comparing source data to the final Parquet file contents.
Performance and data loss prevention
Performance was tuned for maximum throughput at three stages in the pipeline:
- Data ingestion – Data integrity during ingestion was dramatically improved using CDC events and allowed us to rely on the well-respected replication mechanisms in PostgreSQL and Kafka, which simplified the system and eliminated a lot of the past data corrections that were in place. The Amazon S3 sink connector further streams data into Amazon S3 in real time by partitioning data into fixed-sized files. Fixed-size data files avoid further latency due to unbound file sizes. As a result, data was higher quality and was streamed in real time at a much faster rate.
- Data transformation – Batch processing is highly cost efficient and compute efficient, and can mitigate various potential performance issues if appropriately implemented. Tricentis uses batch transformation to move data from multi-tenant Amazon S3 to single-tenant Amazon S3 and between single-tenant Amazon S3 to Amazon Redshift by micro-batch loading. The batch processing is staged to work within the Lamba invocations limits and maximum Amazon Redshift connections limits to keep the cost minimum. However, the transformation pipeline is configurable to go real time by processing every incoming S3 file on an EventBridge event.
- Data queries – Materialized views with appropriate sort keys significantly improve the performance of repeated and predictable dashboard workloads. Tricentis pipelines use dynamic data loading in views and precomputed results in materialized views to seamlessly improve the performance of dashboards, along with setting up appropriate simple and compound sort keys to accelerate performance. Tricentis query performance is further accelerated by range-restricted predicates in sort keys.
Implementation challenges
Tricentis worked within the default limit of 1,000 concurrent Lambda function runs by keeping track of available functions at any given time and firing only those many functions for which slots are available. For the 10 GB memory limit per function, Tricentis right-sized the Amazon S3 sink connector generated files and single-tenant S3 files to not exceed 4 GB in size. The Lambda function throttling can be prevented by requesting a higher limit of concurrent runs if that becomes necessary later.
Tricentis also experienced some Amazon Redshift connection limitations. Amazon Redshift has quotas and adjustable quotas that limit the use of server resources. To effectively manage Amazon Redshift limits of maximum connections, Tricentis used connection pools to ensure optimal consumption and stability.
Results and next steps
The collaborative approach between Tricentis and the AWS Data Lab allowed considerable acceleration and the ability to meet timelines for establishing a big data solution that will benefit Tricentis customers for years. Since this writing, customer onboarding, observability and alerting, and security scanning were automated as part of a DevSecOps pipeline.
Within six weeks, the team was able to beta a data export service for one of Tricentis’ customers.
In the future, Tricentis anticipates adding multiple data sources, unify towards a common, ubiquitous language for testing data, and deliver richer insights so that our customers can have the correct data in a single view and increase confidence in their delivery of software at scale and speed.
Conclusion
In this post, we walked you through the journey the Tricentis team took with the AWS Data Lab during their participation in a Build Lab session. During the session, the Tricentis team and AWS Data Lab worked together to identify a best-fit architecture for their use cases and implement a prototype for delivering new insights for their customers.
To learn more about how the AWS Data Lab can help you turn your ideas into solutions, visit AWS Data Lab.
About the Authors
 Parag Doshi is Vice President of Engineering at Tricentis, where he continues to lead towards the vision of Innovation at the Speed of Imagination. He brings innovation to market by building world-class quality engineering SaaS such as qTest, the flagship test management product, and its underlying analytics capabilities, which unlocks software development lifecycle insights across all types of testing. Prior to Tricentis, Parag was the founder of Anthem’s Cloud Platform Services, where he drove a hybrid cloud and DevSecOps capability and migrated 100 mission-critical applications. He enabled Anthem to build a new pharmacy benefits management business in AWS, resulting in $800 million in total operating gain for Anthem in 2020 per Forbes and CNBC. He also held posts at Hewlett-Packard, having multiple roles including Chief Technologist and head of architecture for DXC’s Virtual Private Cloud, and CTO for HP’s Application Services in the Americas region.
Parag Doshi is Vice President of Engineering at Tricentis, where he continues to lead towards the vision of Innovation at the Speed of Imagination. He brings innovation to market by building world-class quality engineering SaaS such as qTest, the flagship test management product, and its underlying analytics capabilities, which unlocks software development lifecycle insights across all types of testing. Prior to Tricentis, Parag was the founder of Anthem’s Cloud Platform Services, where he drove a hybrid cloud and DevSecOps capability and migrated 100 mission-critical applications. He enabled Anthem to build a new pharmacy benefits management business in AWS, resulting in $800 million in total operating gain for Anthem in 2020 per Forbes and CNBC. He also held posts at Hewlett-Packard, having multiple roles including Chief Technologist and head of architecture for DXC’s Virtual Private Cloud, and CTO for HP’s Application Services in the Americas region.
 Guru Havanur serves as a Principal, Big Data Engineering and Analytics team in Tricentis. Guru is responsible for data, analytics, development, integration with other products, security, and compliance activities. He strives to work with other Tricentis products and customers to improve data sharing, data quality, data integrity, and data compliance through the modern big data platform. With over 20 years of experience in data warehousing, a variety of databases, integration, architecture, and management, he thrives for excellence.
Guru Havanur serves as a Principal, Big Data Engineering and Analytics team in Tricentis. Guru is responsible for data, analytics, development, integration with other products, security, and compliance activities. He strives to work with other Tricentis products and customers to improve data sharing, data quality, data integrity, and data compliance through the modern big data platform. With over 20 years of experience in data warehousing, a variety of databases, integration, architecture, and management, he thrives for excellence.
 Simon Guindon is an Architect at Tricentis. He has expertise in large-scale distributed systems and database consistency models, and works with teams in Tricentis around the world on scalability and high availability. You can follow his Twitter @simongui.
Simon Guindon is an Architect at Tricentis. He has expertise in large-scale distributed systems and database consistency models, and works with teams in Tricentis around the world on scalability and high availability. You can follow his Twitter @simongui.
 Ricardo Serafim is a Senior AWS Data Lab Solutions Architect. With a focus on data pipelines, data lakes, and data warehouses, Ricardo helps customers create an end-to-end architecture and test an MVP as part of their path to production. Outside of work, Ricardo loves to travel with his family and watch soccer games, mainly from the “Timão” Sport Club Corinthians Paulista.
Ricardo Serafim is a Senior AWS Data Lab Solutions Architect. With a focus on data pipelines, data lakes, and data warehouses, Ricardo helps customers create an end-to-end architecture and test an MVP as part of their path to production. Outside of work, Ricardo loves to travel with his family and watch soccer games, mainly from the “Timão” Sport Club Corinthians Paulista.